【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.2
【遇到的问题:问题现象及影响】
qps变化不大的情况下,tikv内存一直不断增长,查看tikv节点,io,cpu使用率并不高
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面

tiup show-config 看下你的 tikv参数 尤其是 block-cache.capacity
然后 display 看下你的部署拓扑,是混合部署吗
block-cache.capacity为120G,已经降低了两次,改为80G了,每次改完,过不了多久内存使用就又涨上来了,tikv进程的内存占用200多G,远大于block-cache.capacity这个设置
1 个赞
一台物理机,部署几个tikv实例
集群混合部署,但是另外俩集群业务量小,看了下内存占用很少
一台物理机上有3套tikv集群的各一个tikv节点,另外两套集群的tikv内存占用很少
看下grafana面板,tikv-details中的内存使用情况
TiKV Detail → Resolved TS → Lock heap size
TiKV Detail → Server → Memory Trace
这2个先看看
内存占用计算方式如下: 占用内存=block-cache.capacity (默认值:系统总内存 * 45%)+ ( write-buffer-size * max-write-buffer-number * 4 ) + raft-engine.memory-limit(默认值:系统总内存 * 15%),所以需要先确认一下tikv配置及tikv实例数量。
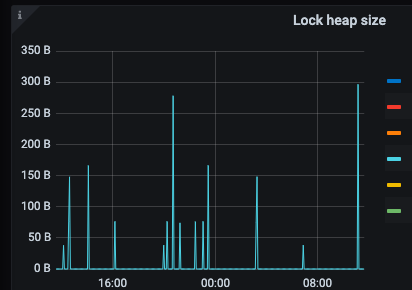
block-cache.capacity 80G
write-buffer-size 128MB
max-write-buffer-number 5
raft-engine.memory-limit 57.8G
可以看下 topsql 和 internal sql,这个版本好像有个 internal sql 导致内存使用率高的 bug
internal sql 在哪看啊
这个 issue,https://github.com/pingcap/tidb/issues/52826,,可以看下 sql statement 中有没有时常执行这个 sql,如果没有的话,就应该不是这个问题
没有,不过看grafana上,发现有一个指标跟内存增长的时间点对的上
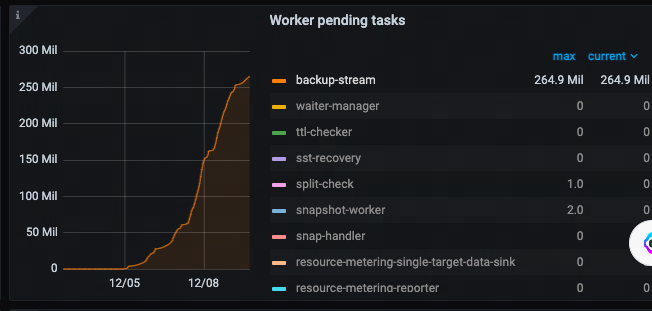
这个backup-stream是什么啊
从你这个监控也只能从 backup 方面看看有没有什么异常了
大于是正常的,block-cache.capacity限制的只是tikv缓存的大小,tikv占用内存达到这个值的2倍也很正常。但是你这个都2.5倍了有点不正常,建议可以先把这个值再调小一点例如60G看看tikv的内存占用情况.
调小过的,最开始是120G调整到100G,后来调整到80G,都是调整后没多久内存使用就又上来了
我的意思你调整到60G,看看整个内存还能占用到200G吗