EDG-给我冲
(Ti D Ber Rlngnbg F)
1
【 TiDB 版本】 V7.5.4
【 架构】 1个PD,一个tidb-server,在同一台机器上。配置为 8C32G。三个tikv,在同一个服务器上,分别挂载了三个硬盘。 配置为 32C128G。
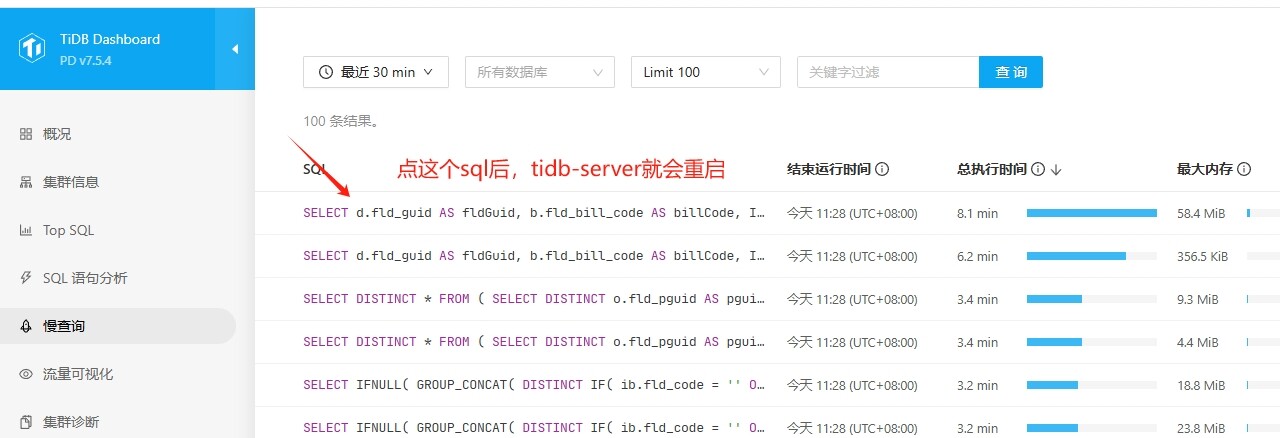
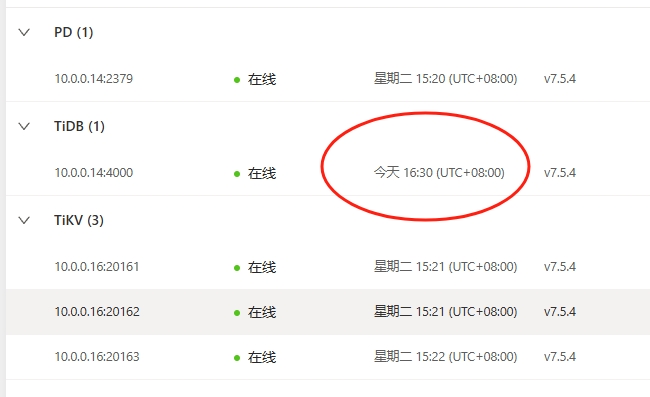
【遇到的问题:】某一时间,程序突然提示数据库连接不到。通过 dashboard排查慢sql,发现该时间段有很多几分钟的sql,当我点击查看某个sql的具体内容时 ,PD占用cpu突然升高,服务器负载升高。具体见下图。然后tidb-server开始重启。并不是点慢查询中的所有sql都有出现该问题。查看某些sql时比较快的就可以看到sql详情。
【附件:截图/日志/监控】
diwing
(Ti D Ber R Qstj35v)
2
先看tidb日志有没有报错,再看系统日志有没有oom
kevinsna
(Ti D Ber P O Zcnp Ja)
3
检查TiDB的日志文件,特别是tidb_stderr.log`,以查看是否有关于慢查询或资源使用的相关信息。这可能帮助您识别导致负载增加的具体查询,监控PD和TiKV的状态,查看是否有OOM发生,检查下主机的内存是否充足
遇到过,原因一语句欠优化 ,原因二,混合部署了其他吃资源的数据同步系统导致内存徒增,。
感觉楼主的问题也是内存问题引起的
1 个赞
大概率是OOM了,如果是物理机器部署的tidbserver,可以从/var/log/message日志里看下
小龙虾爱大龙虾
(Minghao Ren)
7
看看内存情况如何,是不是出发了操作系统 oom-kill 行为
再看看 TiDB 日志,有没有 panic 日志
sql导致的,大概率感觉应该是oom了,tidb日志搜一下看有没有welcom关键字
EDG-给我冲
(Ti D Ber Rlngnbg F)
9
是说那个慢 sql 欠优化么? 假设是。但是那句sql 已经执行过了。我只是去看下这个sql 的详情哇 
EDG-给我冲
(Ti D Ber Rlngnbg F)
10
控制台显示新的启动时间了,日志肯定是有的。但是 重启之前没有报错。退一步讲 ,我就只是查这个sql 的详情。也不知道去执行这个可能有问题的 sql。
SELECT * FROM INFORMATION_SCHEMA.CLUSTER_STATEMENTS_SUMMARY
SELECT * FROM INFORMATION_SCHEMA.CLUSTER_STATEMENTS_SUMMARY_HISTORY;
SELECT * FROM INFORMATION_SCHEMA.SLOW_QUERY;
这几个表都查下,能在这几个表中找到对应的sql记录吗?
/搜日志welcome关键字,然后再?搜expensive,一般就能查到问题SQL
舞动梦灵
(Ti D Ber Nckmz Hmh)
14
大事务sql导致oom才会自动重启,我这边也有这个情况。要么加内存。要么看这个sql如果是偶尔一次。那就忽略
EDG-给我冲
(Ti D Ber Rlngnbg F)
15
解决了。绑核了。所以内存只用了一半。然后设置的最大可用内存超过了一半的内存。但是访问慢 sql 时 ,确实是会占用不少内存。
1 个赞
residentevil
(Ti D Ber Zux S Mt7 W)
16
这业务的SQL确实够复杂的,执行时间都是分钟级别了
system
(system)
关闭
17
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。