【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】v4.0.0
【遇到的问题:问题现象及影响】现在机器需要停机,停机前想要使用tiup cluster stop命令停止多个机器上的节点,比如tikv、tidb、tiflash(非混合部署)等,但是停机时间可能较久,比如超过3小时,如果机器启动后,再次使用start命令启动对应节点,那么这些节点是否可以正常加入集群,以及会有哪些额外影响
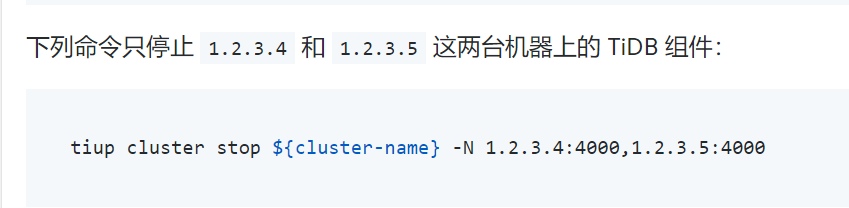
1、停止多个节点,可以使用tiup cluster stop ${cluster_name} -R tikv。-R后面跟角色名称,比如tikv pd tidb。也可以使用-N,就是图片的内容。
2、再次启动机器,不需要使用start的命令,角色跟随操作系统一起启动。
3、可以正常加入集群,使用tiup cluster display ${cluster_name} 查看。
可以正常停机,也可以正常加入,不过tikv和pd同时停2个,集群就停止工作了
停止时间过长,pd是不是就认为该机器故障了,然后把该节点从集群中处理掉?以及该机器上保存的数据会怎么处理?当我再次启动时,还会将其作为集群中一节点继续使用吗,数据会受影响吗
节点应该是可以正常重新加入集群,但在长时间停止后,可能需要一些额外的时间来恢复数据一致性和集群状态。建议在进行长时间的停机维护时,提前做好数据备份和监控,以减少潜在的影响。
首先,停机前先做一个全备份,有备无患。
只要你正常停机 ,启动时候肯定没问题
最好就是一台台的停,然后启动。正常之后。在以此第二个。tidb server和pd server和tikv 轮流一个个来。停止一台问题吧。我的是4.0.2高版本。有一次阿里服务器问题。导致一台TIKV 关机1个小时。启动之后。他又自动加入了。
好的,谢谢
主要还是担心数据的问题
借你吉言
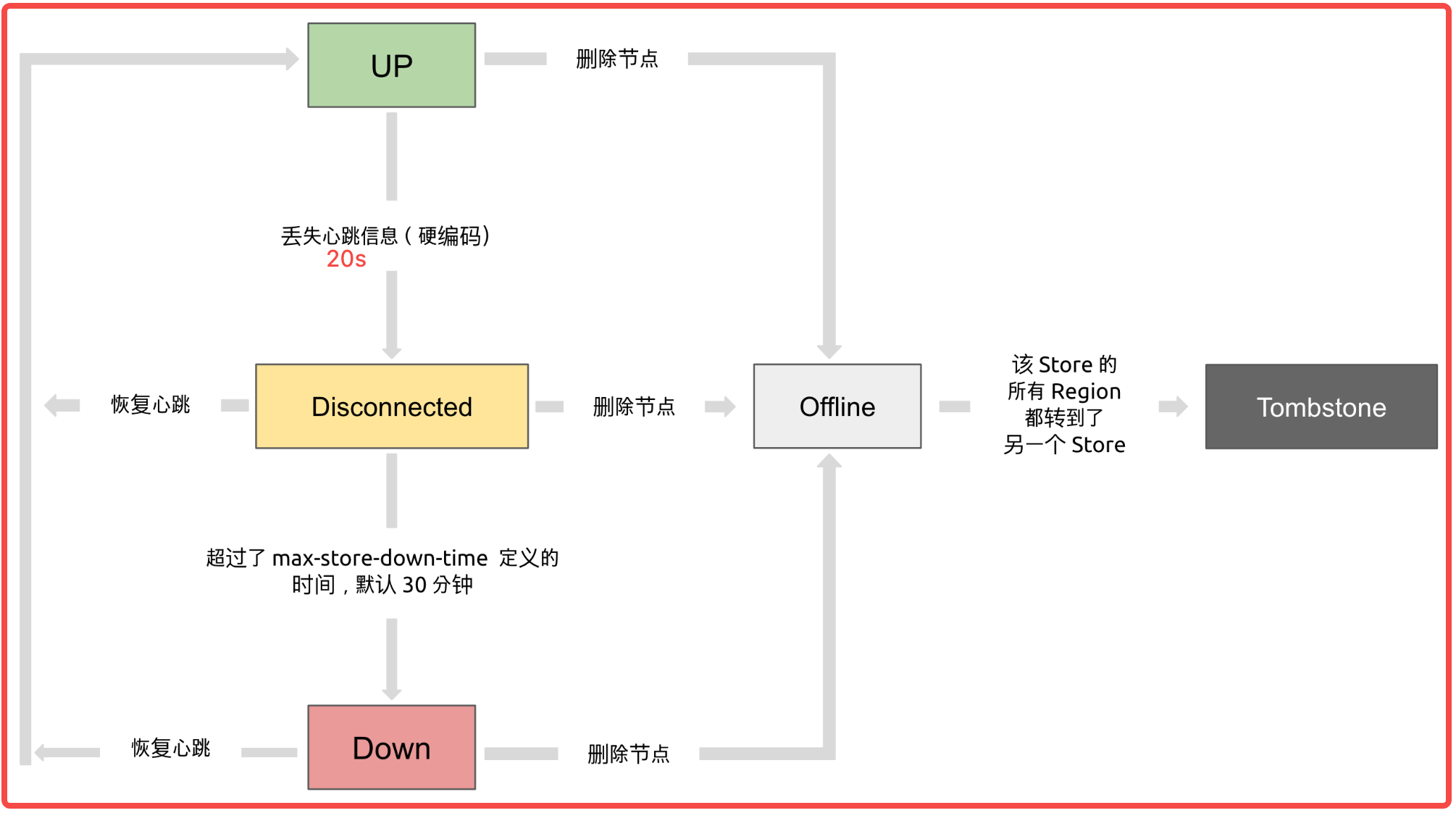
应该问题不大,disconnected状态时应该就会开始leader副本的迁移了,毕竟需要读写主副本,失联时是要保证读写的。等状态正常,又会把副本迁移回来。
停机时间过长,如果pd认为该机挂掉时,除了leader迁移之外,那么该机器上的数据是否会迁移?
在TiDB集群中,如果PD认为某个TiKV节点挂掉,除了进行Leader迁移以确保高可用性外,该节点上的数据也会被迁移。这是因为TiKV是一个分布式存储系统,它会确保数据的副本分布在不同的节点上以实现数据的高可用性和容错性
当一个TiKV节点被认为不可用时,PD会触发故障转移流程。这个过程包括以下几个步骤:
- Leader迁移:PD会将该节点上的一些Region的Leader角色迁移到其他健康的节点上,以确保这些Region的读写操作可以继续进行。
- 数据迁移:TiKV中的数据会根据PD的调度策略自动迁移到其他健康的节点上。这个过程是自动的,并且会尽量保持数据的均匀分布。
- 副本重建:为了保证数据的多副本,PD会调度其他节点来重建丢失节点上的数据副本,确保每个Region都有指定数量的副本。
如果整个集群需要停机,正常 tiup cluster stop cluster_name .
如果少数实例停机 比如3分之1 指定-N.停机的重新启动后,会自动加入进来。
tidb这点做的很好了。
正常停了,没什么问题
tikv连接不上时,pd多久会认为该节点不可用进行相关leader和region迁移?我看官方有个max-down-time-limie参数,默认值30分钟,超过该值会进行自动迁移,那么30分钟内,是否leader在该节点上的都不可用,岂不是和高可用有点出入?
正常加入进来数据是否会受影响?比如超过30分钟后,数据和leader都被迁移到其他节点了,但是30分钟内,由于该机器已经停机,该节点上的leader和数据都还在,那么请求到该机器上的服务是不是都不可用?还是说请求不可用时立马就进行leader迁移了?因为我看官方文档说是30分钟后pd才会认为该机器宕机