【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
背景:跨机房部署的tidb备份集群,通过ticdc同步数据,今天早上网络专线被挖断了,ticdc一直不能同步到下游。
想请教一下,ticdc会把变更的数据读到自己内存中吗?如果长时间不能同步到下游,会不会导致同步任务死掉或者ticdc服务死掉
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
背景:跨机房部署的tidb备份集群,通过ticdc同步数据,今天早上网络专线被挖断了,ticdc一直不能同步到下游。
想请教一下,ticdc会把变更的数据读到自己内存中吗?如果长时间不能同步到下游,会不会导致同步任务死掉或者ticdc服务死掉
ticdc可能会oom
我看ticdc会在pd中注册gc点,这个gc点不会hang住tikv gc进程吗?
不会的,它的机制就是这样,不会丢,会保存到内存中,TiCDC会管理其内存使用,并在必要时进行清理和优化
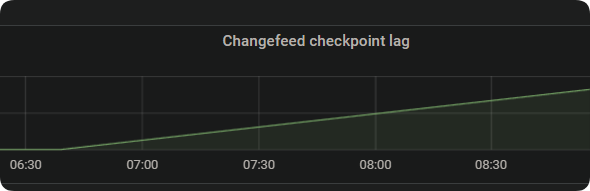
我的问题就是,如果一直不能同步到下游,那就一直累计到内存中,会不会内存满了卡死进程
TiCDC 卡住的话, cdc的GC safepoint 会阻塞 TiKV GC 数据,cdc的gc-ttl默认是24小时。
所以如果ticdc一直卡住,且不失败退出的话,这个gc点就不会失效对吧?
那如果一直不能同步到下游,ticdc本身会不会因为oom失败退出呢?
我有一次下游kafka不通卡住过,当时没有oom。一般是下游恢复后重启cdc任务因为数据量太大会oom.
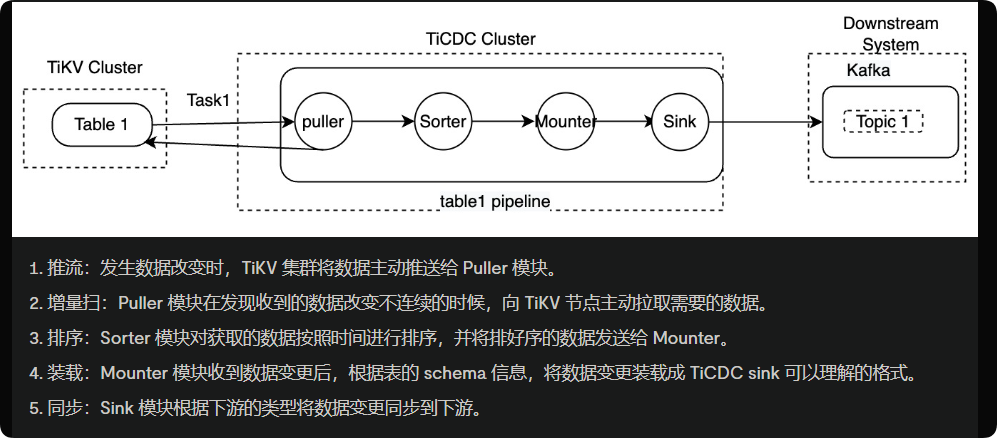
官网上说tikv会主动把变更数据退给ticdc,然后在ticdc内部排序。
像我遇到的这种ticdc一直无法想下游同步数据的情况,tikv还是一直推吗?有没有类似flink的那种反压机制?
一直推,总会把ticdc内存打满吧?
TiCDC确实会将变更数据读到内存中,并在必要时进行内存管理和优化。
如果TiCDC长时间不能同步到下游,TiCDC任务可能会报错卡住。TiC
TiCDC可能会因为下游恢复后重启任务时数据量太大而导致OOM。
我的理解是开始的时候下游连不上,cdc会重试,重试几次后任务就挂起不会再试了,内存不会堆积太多,下游恢复后你需要手动恢复任务。
TiCDC 为 service GC Safepoint 设置的默认存活有效期为 24 小时,即 TiCDC 服务中断 24 小时内恢复能保证 TiCDC 继续同步所需的数据不因 GC 而丢失。如果下游故障时间超过了 gc-ttl 指定的时长,那么该同步任务就会进入 failed 状态,并且无法被恢复
那是不是可以理解为ticdc的最长中断时间就是tidb_gc_life_time的时间。
例如 tidb_gc_life_time 设置为72小时,那在这72小时之内,下游只要能恢复,ticdc就能正确同步?
没有 changefeed 由于内存满了挂掉的问题吗?
在TiCDC中,当网络断开时,TiCDC可能会遇到一些问题。具体来说,如果TiCDC与下游系统的网络连接不可用,TiCDC的sink组件可能会被阻塞,这意味着它无法将捕获的更改数据传递到下游系统。在这种情况下,TiCDC不会将更改的数据读入内存,而是会等待网络恢复。
如果同步延迟时间过长,TiCDC的复制任务可能会进入失败状态。例如,当TiKV的垃圾回收(GC)被TiCDC的GC安全点阻塞时,如果复制任务的延迟超过了配置的gc-ttl 值,复制任务将进入失败状态,并报告ErrGCTTLExceeded 错误。这种情况会导致复制任务无法恢复,从而影响TiCDC服务的正常运行。
原来如此,那也就是说,如果遭遇我们遇到的这种网线被挖断,不能确定恢复时间的情况时。就直接把tidb_gc_life_time设置成一个较大的值,例如7天,这样就行了对吧?
我觉得 将 TiDB 的GC时间更改为 7 天可能会对硬件配置产生一定的影响,主要体现在以下几个方面:
tidb_gc_life_time,以确保 GC 过程能够有效运行而不影响系统的整体性能。根据具体的工作负载和使用场景,可能还需要调整其他相关参数。不讨论以上对性能的影响,只讨论ticdc本身会不会失败,以及能不能续传的问题
理论上,如果日志都存在。是可以继续续传的。只不过数据积压太多。可能会导致某些性能问题,
就好比mysql主从。从库网络断了。但是只要主库有对应时间binlog 只要一启动。他就可以继续读取传输同步。。
在内存就可能会丢