【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】 8.1.0
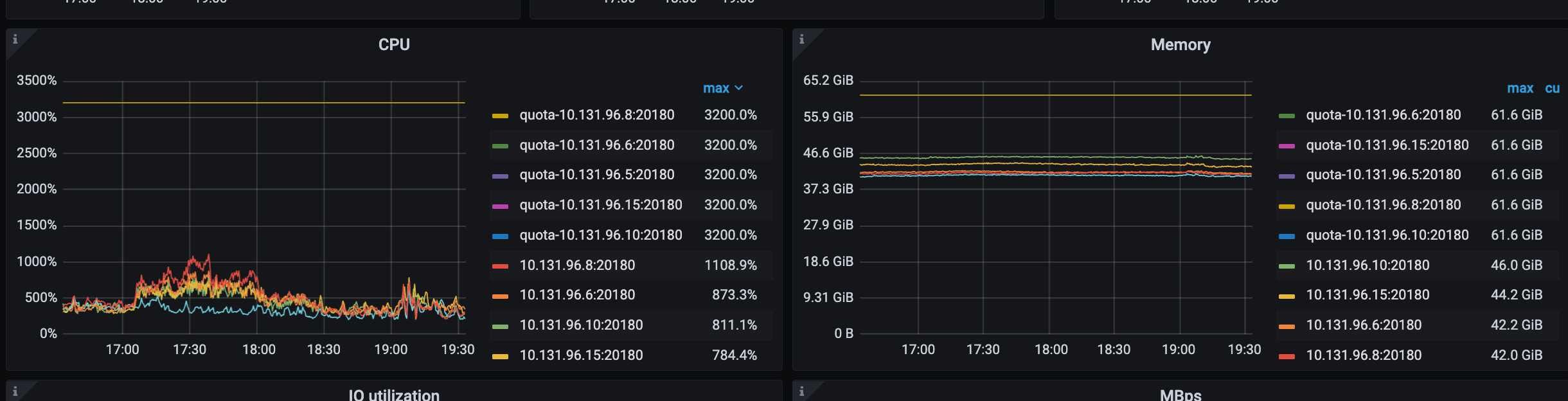
【复现路径】3亿的数据加索引,导致8c16g的tidb节点宕机了
【遇到的问题:问题现象及影响】 4C8G的机器tidb节点直接宕机失联了,并且整个集群的性能变低了很多。




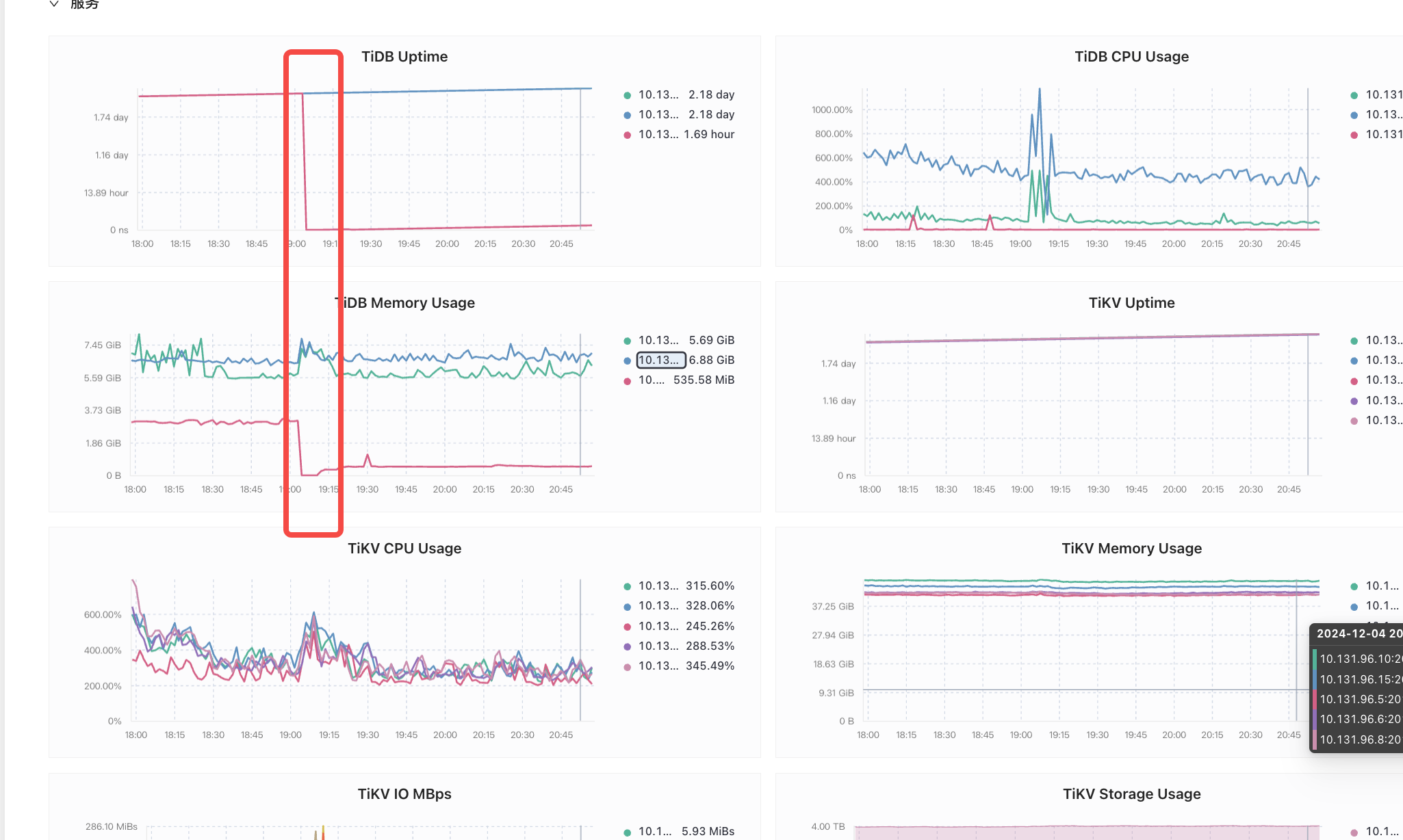
tikv cpu和memory占用正常
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】 8.1.0
【复现路径】3亿的数据加索引,导致8c16g的tidb节点宕机了
【遇到的问题:问题现象及影响】 4C8G的机器tidb节点直接宕机失联了,并且整个集群的性能变低了很多。
tikv cpu和memory占用正常
宕机原因是啥? OOM 了?
是的,内存占满了
是 tidb owner OOM 么?如果是的话 owner 应该切换了,是不是另外一个节点也在内存上升?是的话可以考虑抓个火焰图出来。
![]() 正常应该有并行限制的,oom 感觉不一定和 add index 有关。
正常应该有并行限制的,oom 感觉不一定和 add index 有关。
军哥,正文也补充了一些日志和监控
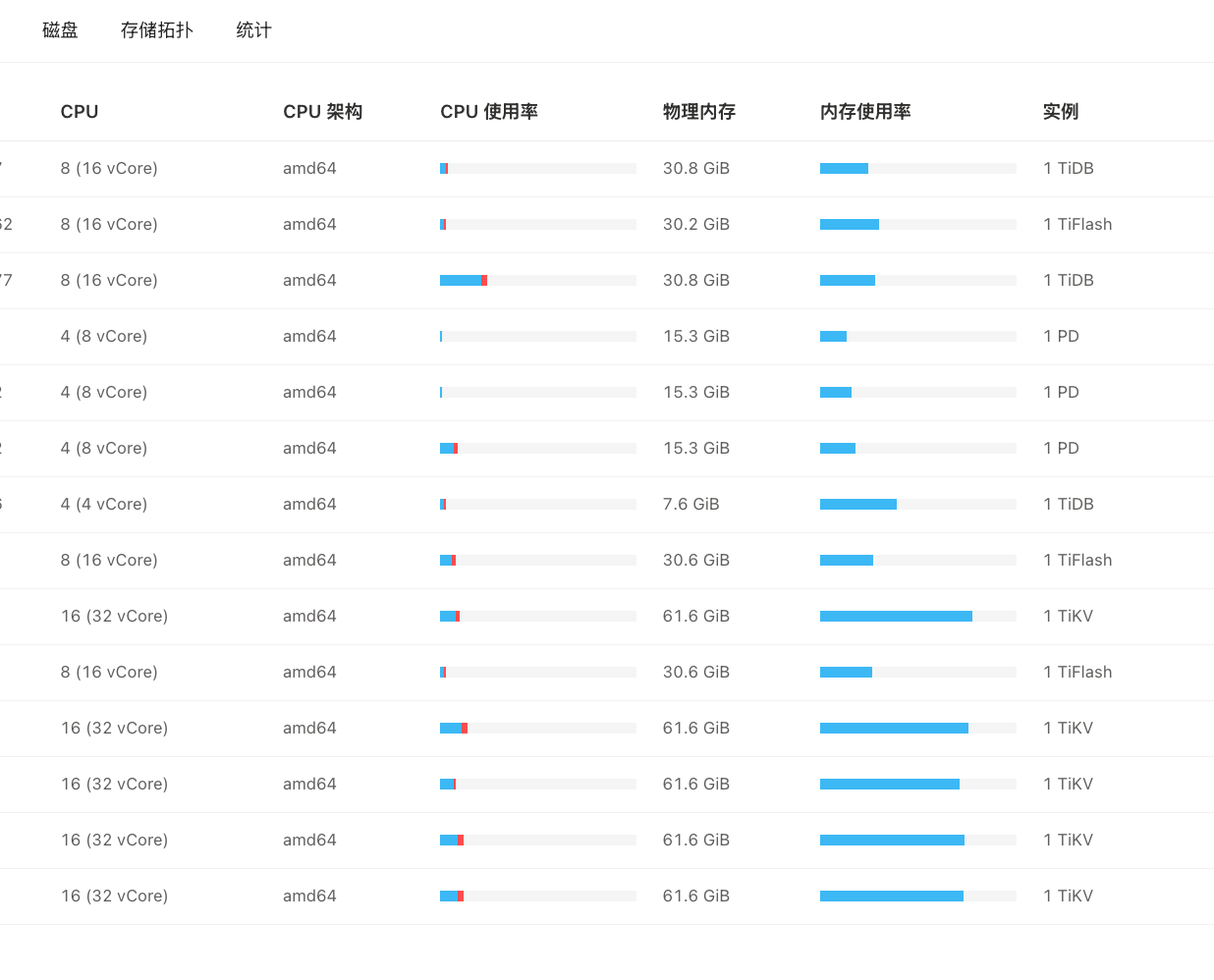
你这个TiDB-server 配置有点低,
把 tidb_ddl_reorg_worker_cnt 和 tidb_ddl_reorg_batch_size 调低可以缓解
或者直接关闭 tidb_ddl_enable_fast_reorg
运维节点
小规格服务器添加大索引适合关闭 tidb_ddl_enable_fast_reorg ,通过传统事务模型细水长流运行,动态调整 tidb_ddl_reorg_worker_cnt 和 tidb_ddl_reorg_batch_size 到资源可控的居中值。
建议先关闭tidb_ddl_enable_fast_reorg参数后再试试,如果怕再次失联影响该tidb server上的其他的SQL的执行,建议设置 tidb_mem_quota_query 来控制单条SQL语句的内存使用阈值
扩容吧 咋调整你这配置我觉得效果也不明显
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。