【 TiDB 使用环境】生产环境 /测试/ Poc
Poc
【 TiDB 版本】
v8.1.1
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
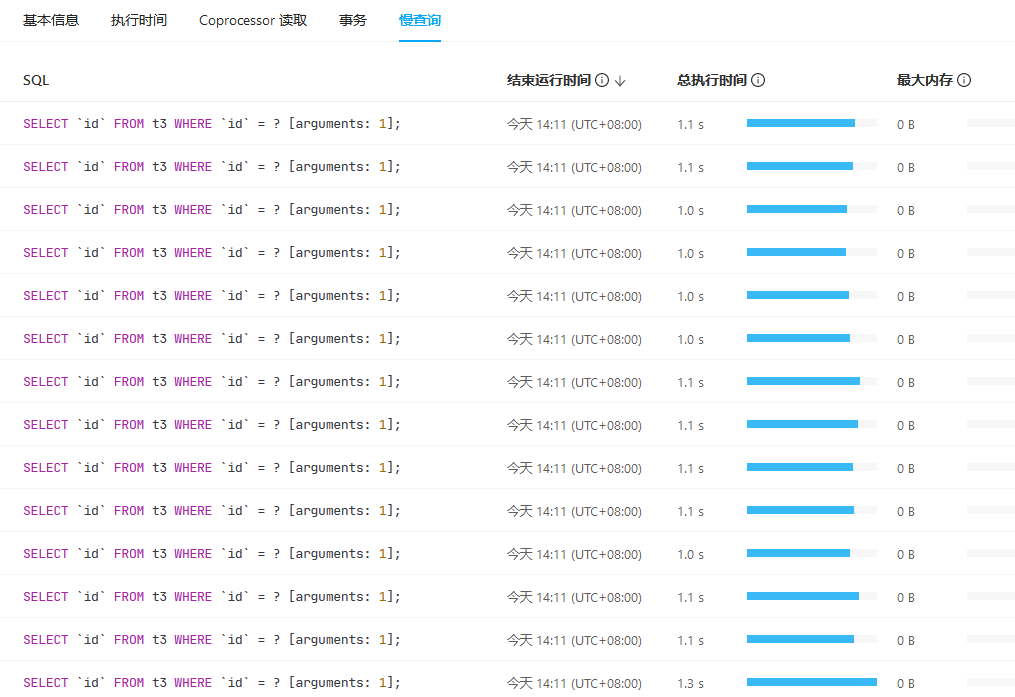
【附件:截图/日志/监控】
复现步骤:
use test;
create table test.t3(id int primary key,name longblob);
insert into test.t3 values(1,REPEAT('A', 1048576)),(2,REPEAT('B', 1048576)),(3,REPEAT('C', 1048576))
使用 golang并发访问
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
db := getDB()
defer db.Close()
for i := 0; i < 400; i++ {
go func() {
for {
rows, err := db.Query("SELECT `id` FROM t3 WHERE `id` = ? ", 1)
if err != nil {
fmt.Printf("Query error: %v\n", err)
return
}
defer rows.Close()
for rows.Next() {
var id uint64
if err := rows.Scan(&id); err != nil {
fmt.Printf("Scan error: %v\n", err)
continue
}
}
}
}()
}
select {}
}
func getDB() *sql.DB {
db, err := sql.Open("mysql", "root:xxxxxx@tcp(192.168.76.12:4000)/test")
if err != nil {
panic(err)
}
db.SetConnMaxLifetime(-1)
db.SetMaxOpenConns(300)
db.SetMaxIdleConns(100)
return db
}
会出现大于1s的查询。这个是否是正常现象。按道理没访问longblob 字段,应该不会出现超1s的慢查询
慢查询执行计划
| id | estRows | estCost | actRows | task | access object | execution info | operator info | memory | disk |
| Point_Get_1 | 1.00 | 0.00 | 1 | root | table:t3, index:PRIMARY(id) | time:1.09s, loops:2, Get:{num_rpc:2, total_time:1.09s}, time_detail: {total_process_time: 680µs, total_wait_time: 12.8ms, total_kv_read_wall_time: 13.5ms, tikv_wall_time: 234.9ms}, scan_detail: {total_process_keys: 2, total_process_keys_size: 1048670, total_keys: 2, get_snapshot_time: 13.3µs, rocksdb: {block: {cache_hit_count: 4}}} | | N/A | N/A |
