【 TiKV 使用环境】测试
【 TiKV 版本】v7.6.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
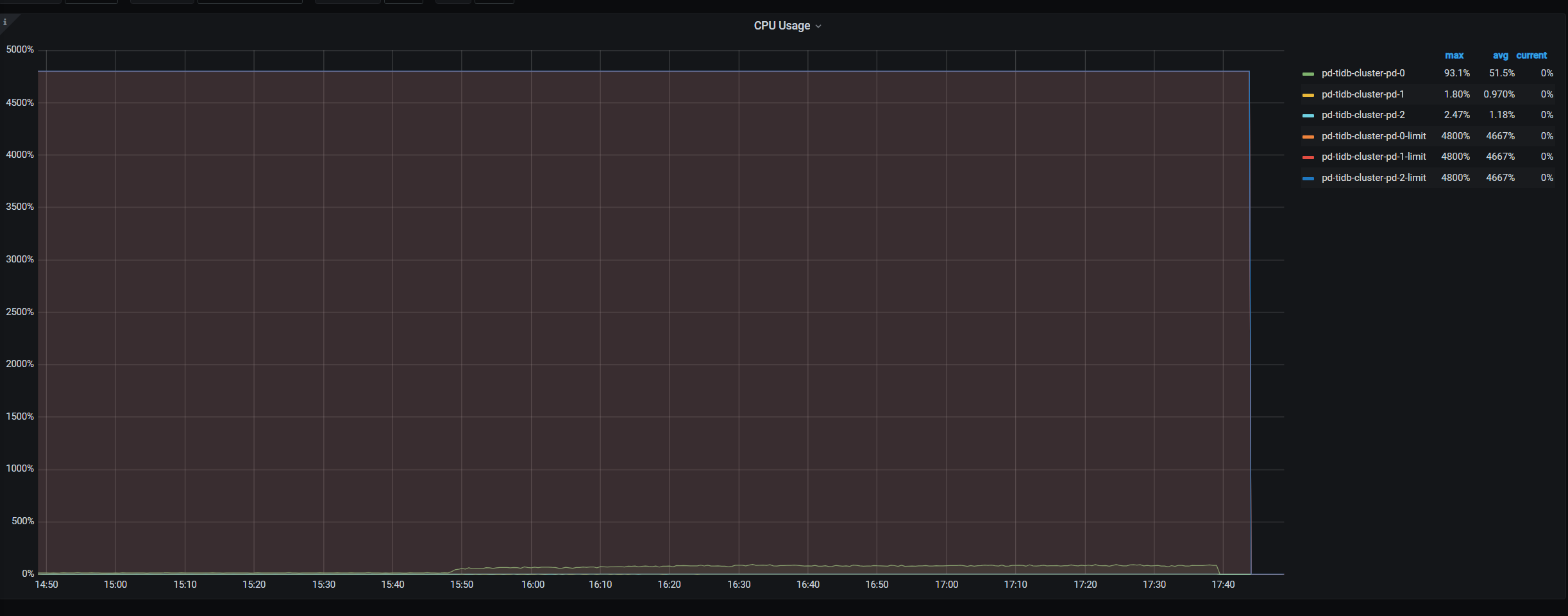
使用k8s部署的TiKV集群,在配置中给每个pd实例都分配了12个cpu核,使用ycsb压测时,发现pd的cpu占用始终小于100%
请问在我们的配置下,理论上pd的cpu占用最高是否可以达到1200%,还是说cpu占用只会在100%以下
并且测试过程中出现了以下warning,请问可能是什么原因
nobody
(不定时出现)
2
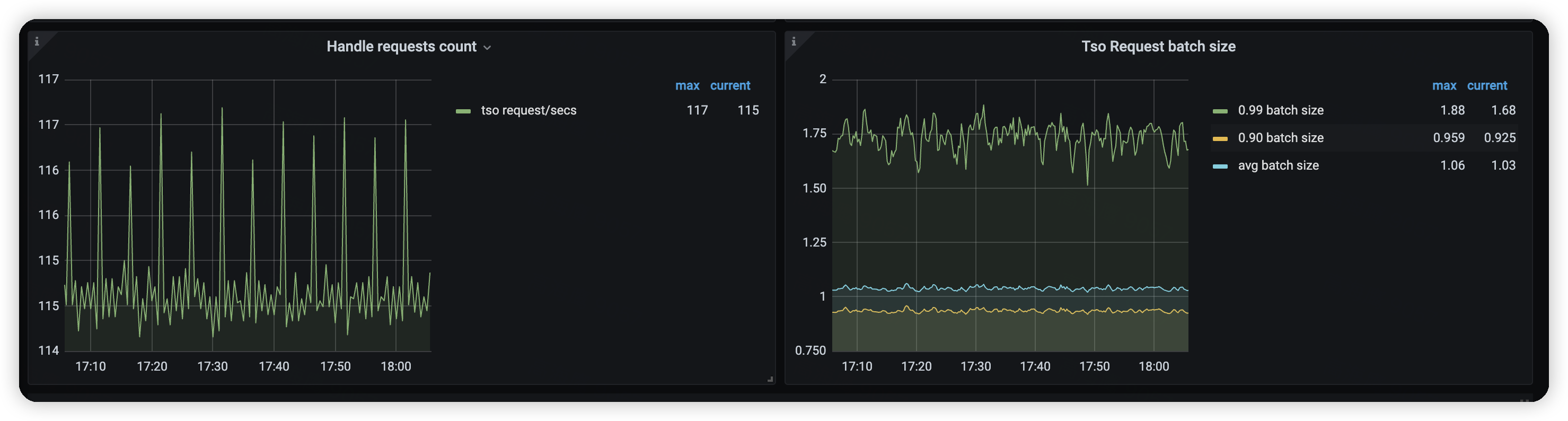
大部分情况下 pd 主要是处理 tso 请求,tidb 请求 tso 是攒批的形式,也就是攒批请求通过一个 rpc 去 pd 申请 tso 。
如果前端压力增加但是pd cpu 没有增加的,一个合理的解释可能是 tidb 攒的批越来越大,导致tidb 给 pd 发送的请求并没有增加。可以通过 pd->tidb 的如下监控辅助判断
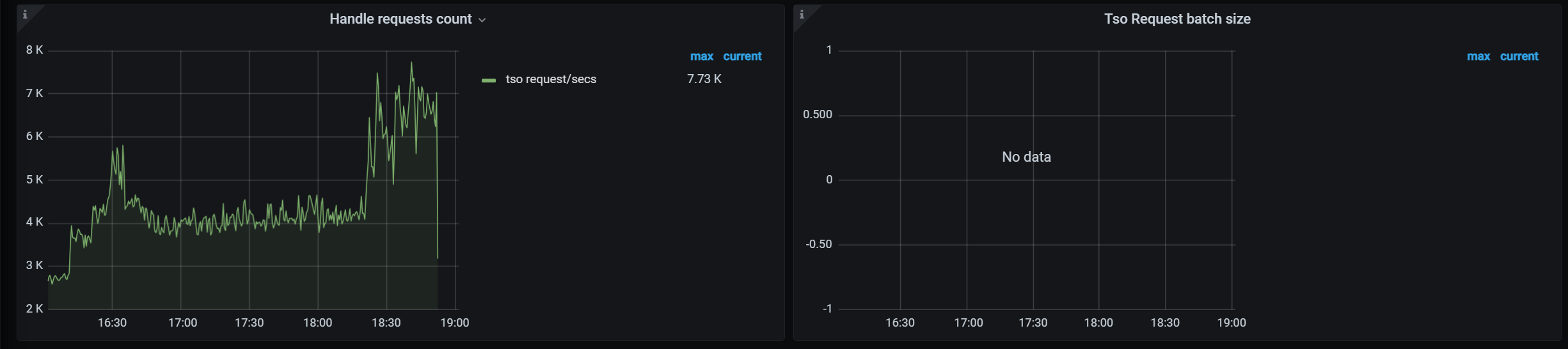
只部了pd和tikv,没有部tidb,所以这里tidb相关的batch数据是没有的,请问还有其他可能的原因吗

nobody
(不定时出现)
4
tikv 的确没啥特别好的观测手段,但是如果随着 ycsb 客户端数量增加,qps 线性增加的话,那证明 pd 是没啥瓶颈的,不用纠结使用率。pd 本身成为瓶颈的概率很低。
ps: pd cpu 肯定是能超过超过 100%的。
kevinsna
(Ti D Ber P O Zcnp Ja)
5
在Kubernetes中,为容器分配CPU资源时,需要设置CPU的请求(request)和限制(limit)。如果PD实例的CPU请求设置得太低,即使分配了12个CPU核,实际使用的CPU资源也可能不足。请检查PD实例的资源配置,确保CPU请求和限制设置合理
有猫万事足
6
可以,而且别说1200%。pd的最大cpu限制是tidb集群上PB需要特别考虑的问题。tso,region心跳,调度,这些职责在region一多的情况下,是容易把pd的cpu耗尽的。
你用的ycsb压测的时候数据量还不够大,region还不够多。所以pd到不了100%。
另外有几个参数也影响pd的cpu上限。
https://docs.pingcap.com/zh/tidb/stable/pd-configuration-file#tso-update-physical-interval
可以把这个参数调小点再试试,不过如果tidb/tikv的组件cpu已经打满,可能效果也十分有限。
这个参数和其他的参数还有一些互动。下面的链接,你也需要阅读一下
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#causal-ts-从-v610-版本开始引入