【 TiDB 使用环境】生产环境
【 TiDB 版本】V7.5.0
【复现路径】
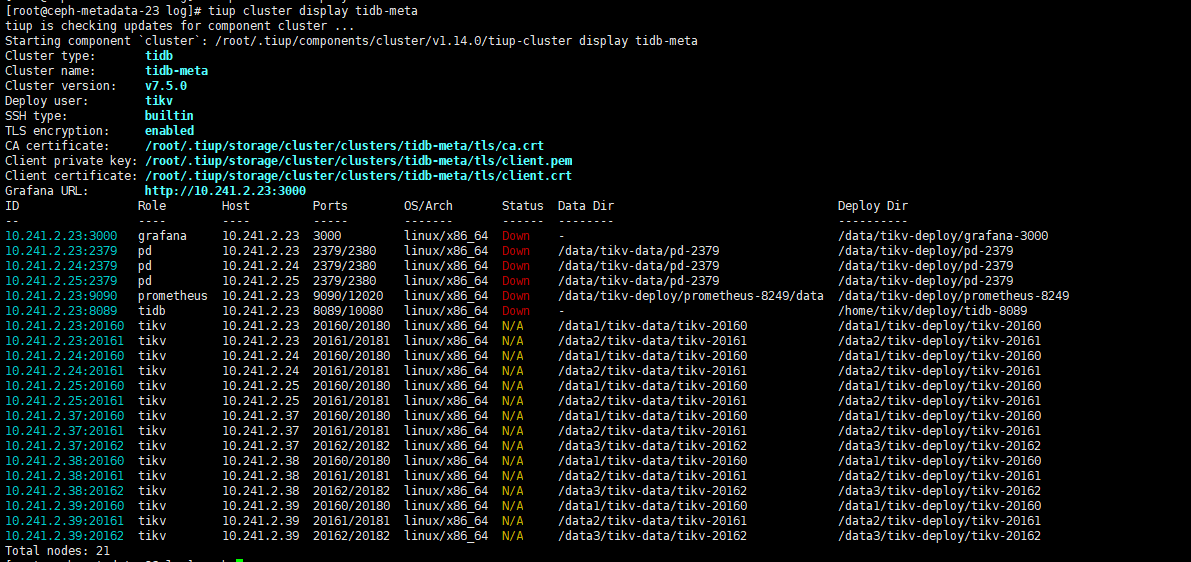
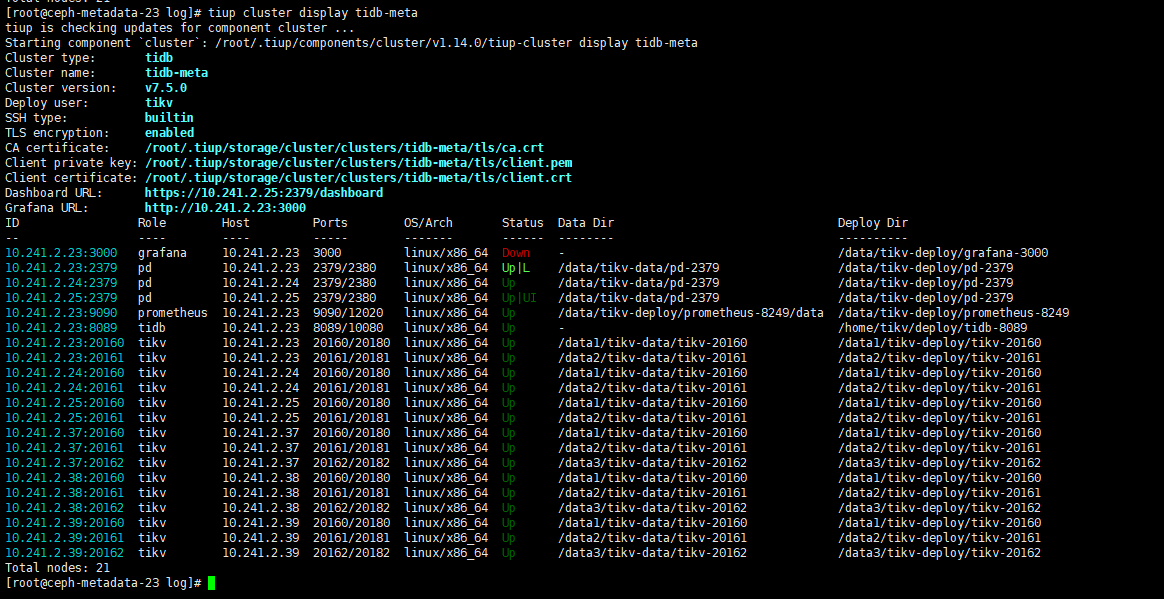
当前使用的是TIKV 集群,是用tiup 部署的,集群状态如图:
集群一共6个节点,23, 24 , 25 和 37 , 38 , 39 ,其中前3个节点是4个SSD盘,后3个节点是4个NVME 硬盘。
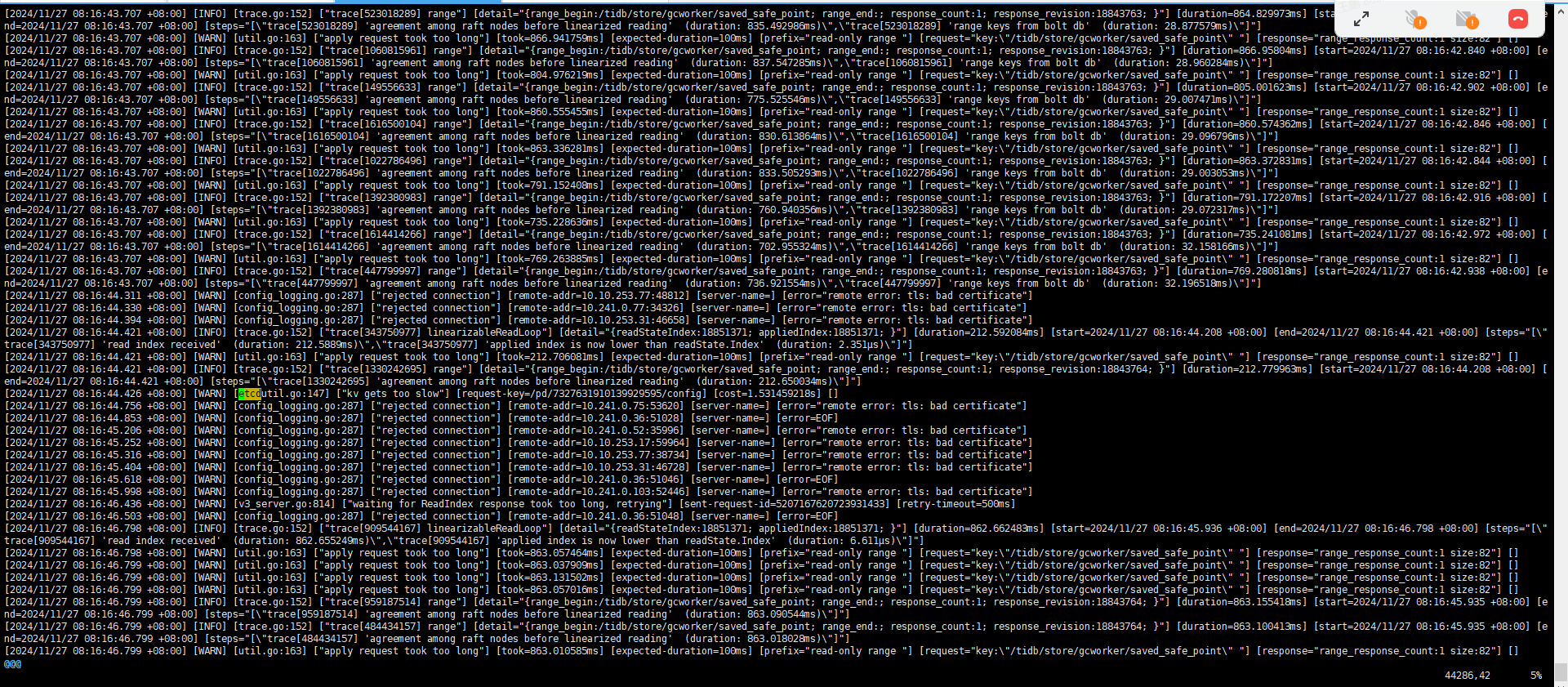
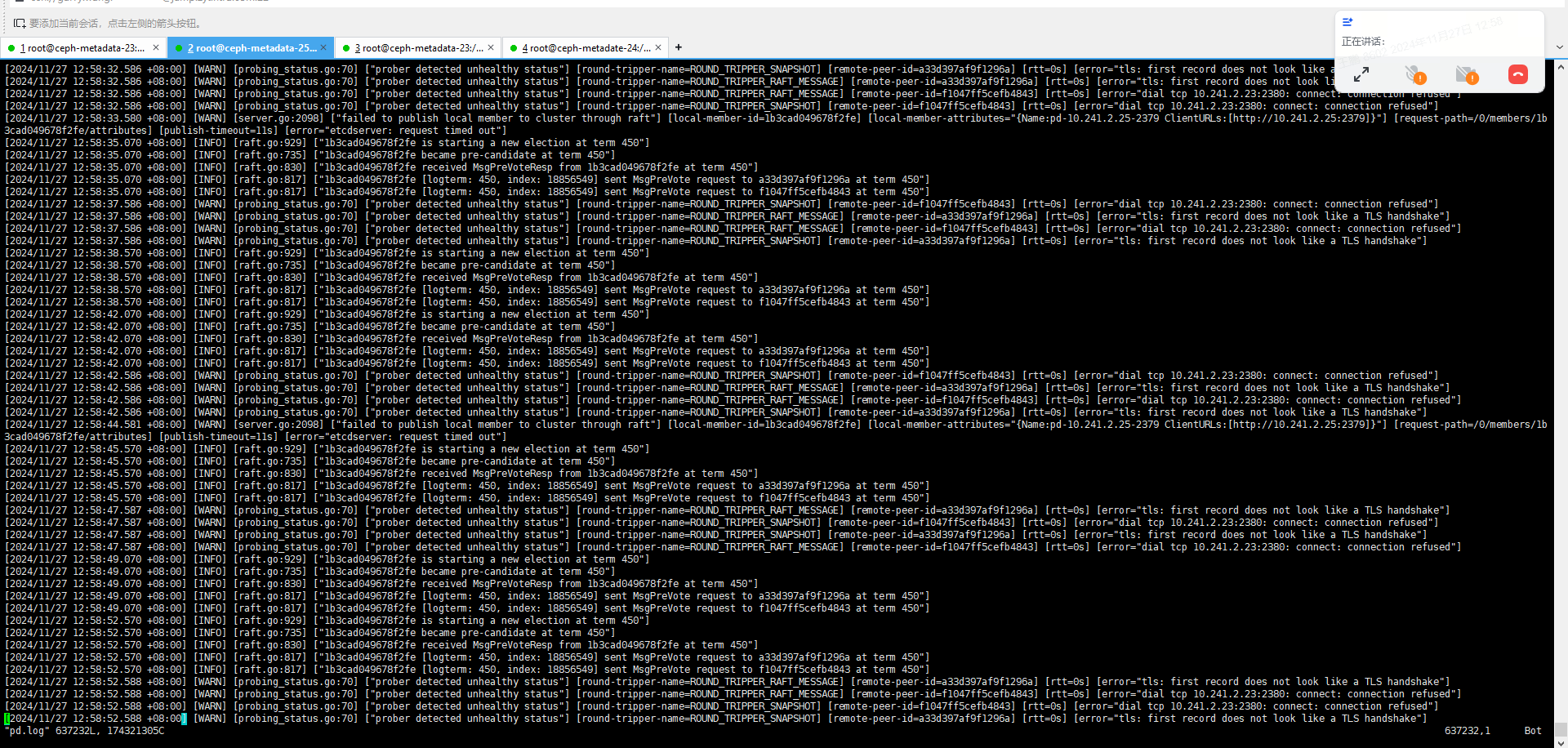
今天早上发现TIKV 服务连不上了,发现3个PD 全部是down 的状体,具体时间未知。截取了一段时间的日志:23 节点的日志
后来重启过24节点,因为发现24节点的dmesg 有打印:
因此,修改了 /etc/security/limits.conf 和 /etc/sysctl.conf ,
然后尝试tiup cluster restart ,依然没用。PD还是down的起不来。
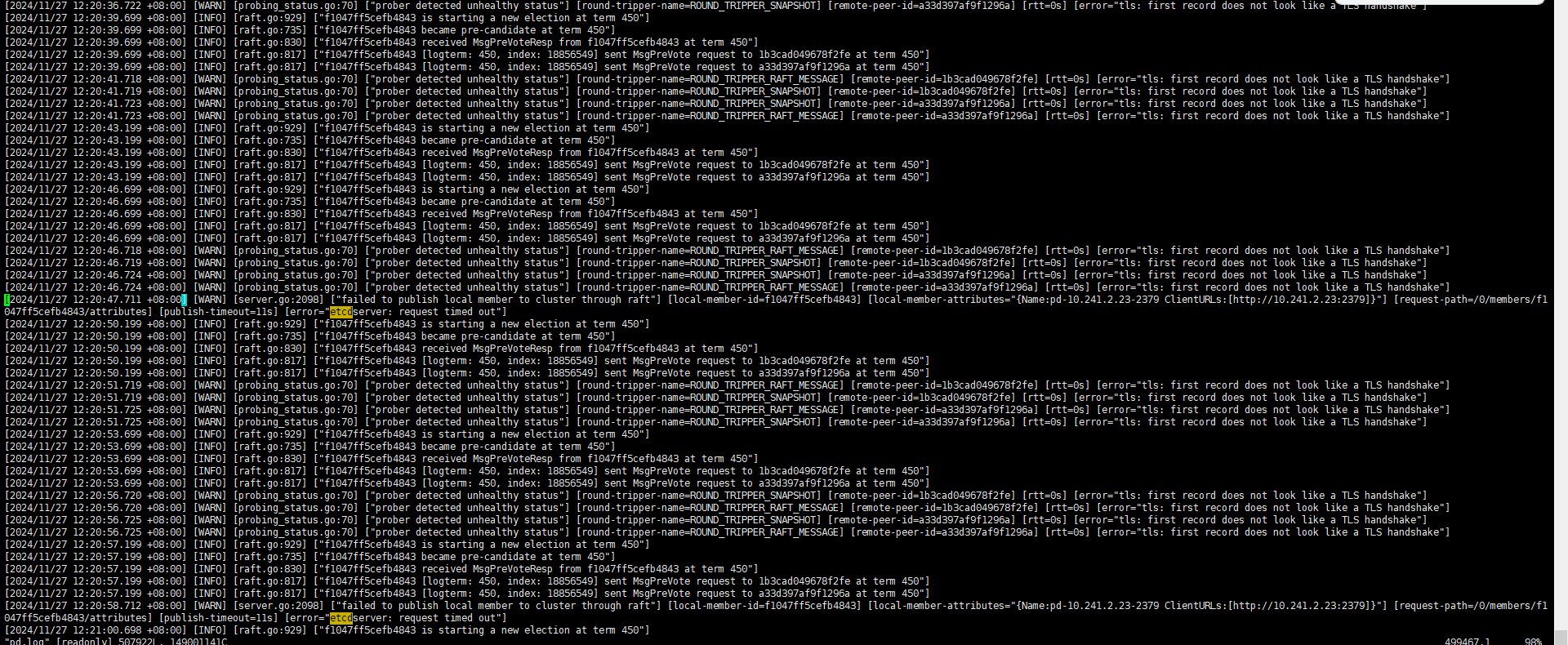
当前最新日志截图: 23节点上的PD日志
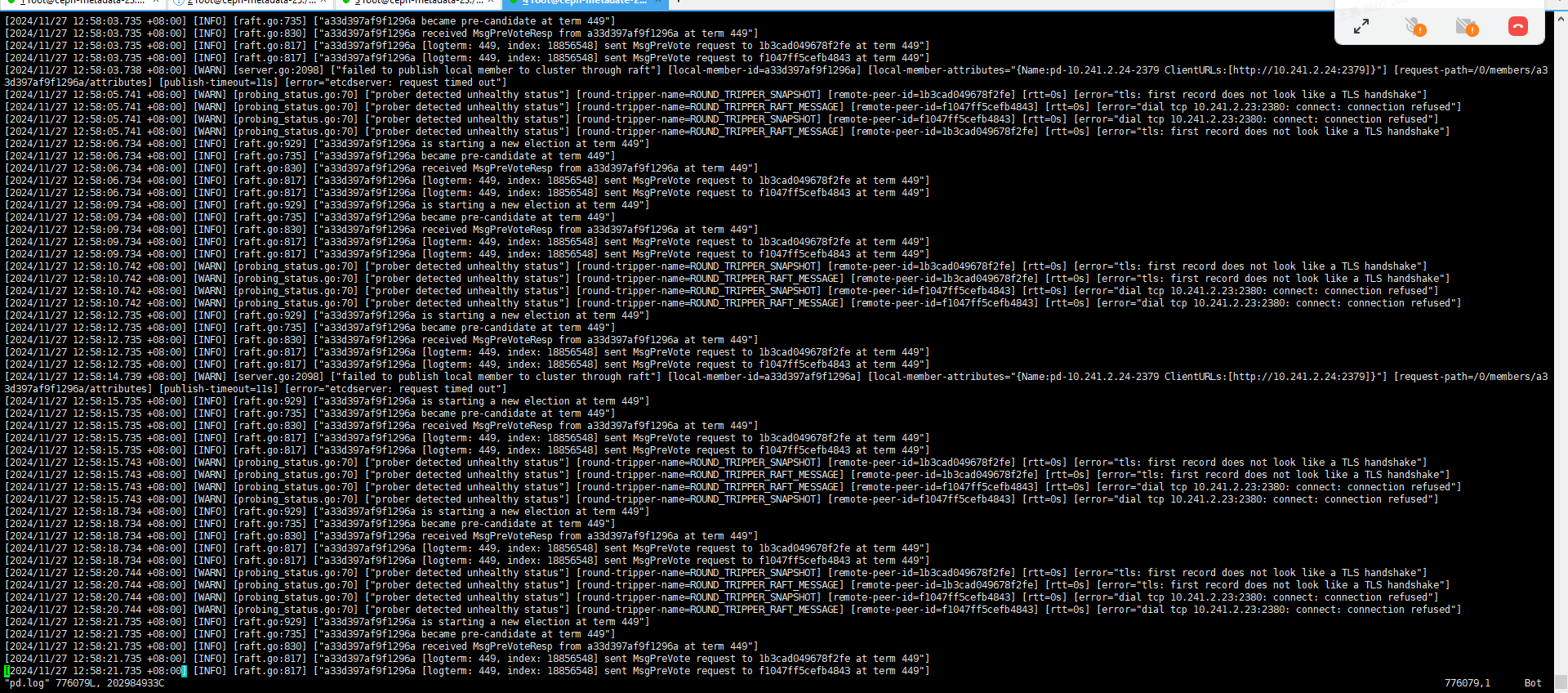
24节点上的PD 最新日志
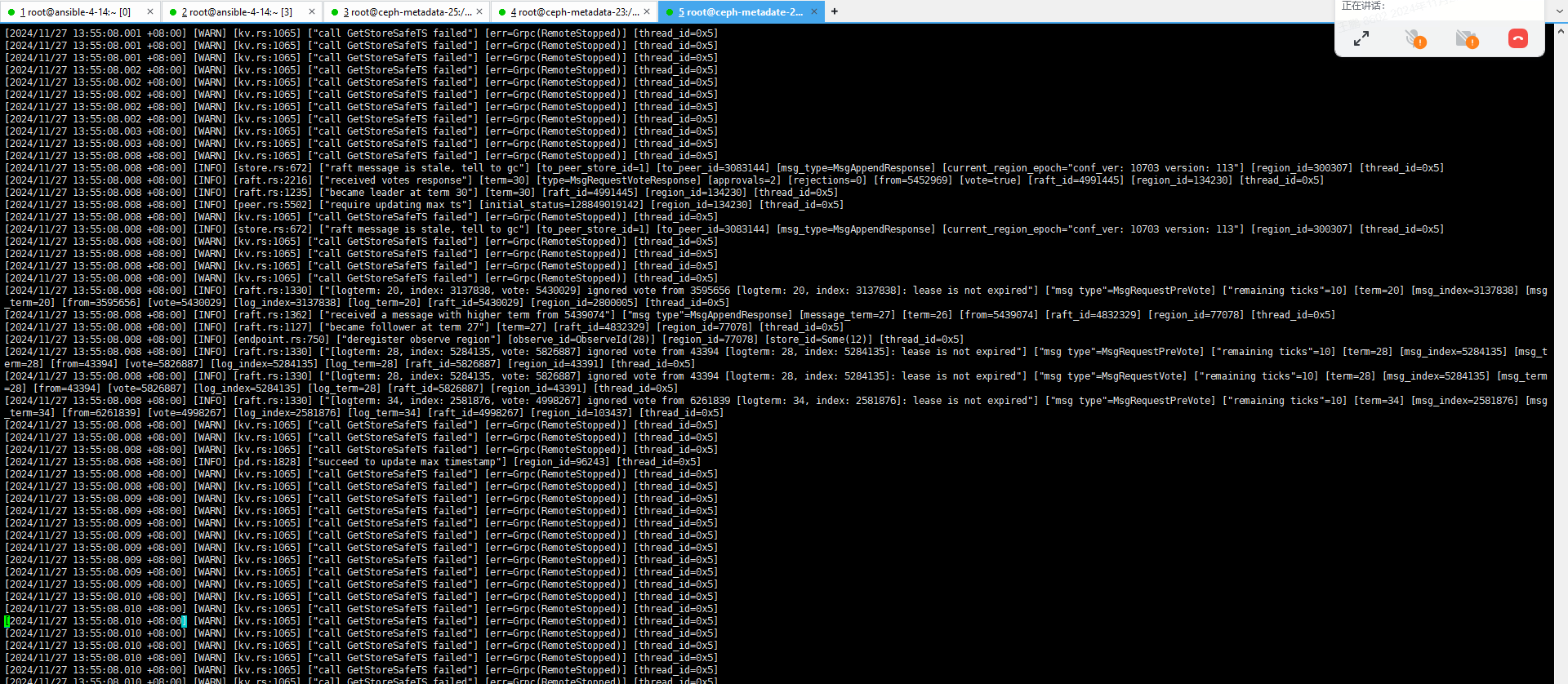
25 节点上的PD 最新日志
看起来是一直在选举,但是选不出来。
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
这个当前已经修改为500w 了。
同时也重启了这个节点。

但是还没恢复。
Kongdom
(Kongdom)
7
最好是三个节点都修改一下,另外重启服务器后注意检查防火墙是否开启,如果开启也会影响TiDB集群启动。
因为看最后的pd日志,24、25都提示连接不到23。
当前进展同步:
我们在6个节点上用iptables 禁了其他客户端访问2379 和2380 端口的请i去。
然后如下图
23 节点上的PD 打印:
24 节点上的tikv 打印:
因为我们是juicefs 服务,我们尝试去连, 发现依然客户端报找不到members
当前是静止,等待下看看情况。
同时10分钟前放开IPTABLES , 发现服务又全部down, tikv 变为NA 状体,这个也不知道为何。
整理了下今天的修复,
找其他大佬协助看了下,最后认为是客户端请求链接太多了,打爆了PD 。我们通过iptables 禁止测试,也验证了确实是 ,只要限制链接范围,服务就能自己逐步恢复。
当前通过这个方式逐步恢复了。
后续有问题,我再持续跟进。
1 个赞
nobody
(不定时出现)
10
集群一直都是开启 TLS 的?感觉可能和认证有关系
看了上面是网络原因导致的。你还是排查下3个pd节点之间网络通不通吧。
telnet xxx:2379
是什么原因导致客户端链接这么多的啊?我看你fs.file-max已经设置成5百万了啊
是等待返回的进程太多还是同时访问太多