【 TiDB 使用环境】
生产环境
【 TiDB 版本】
v7.5.0
【复现路径】
通过 JuiceFS 方式使用 TIKV,直连 PD。具体原因不明,可能与大量写入有关。
【遇到的问题:问题现象及影响】
故障期间 JuiceFS 大范围客户端元数据时延飙高
【资源配置】
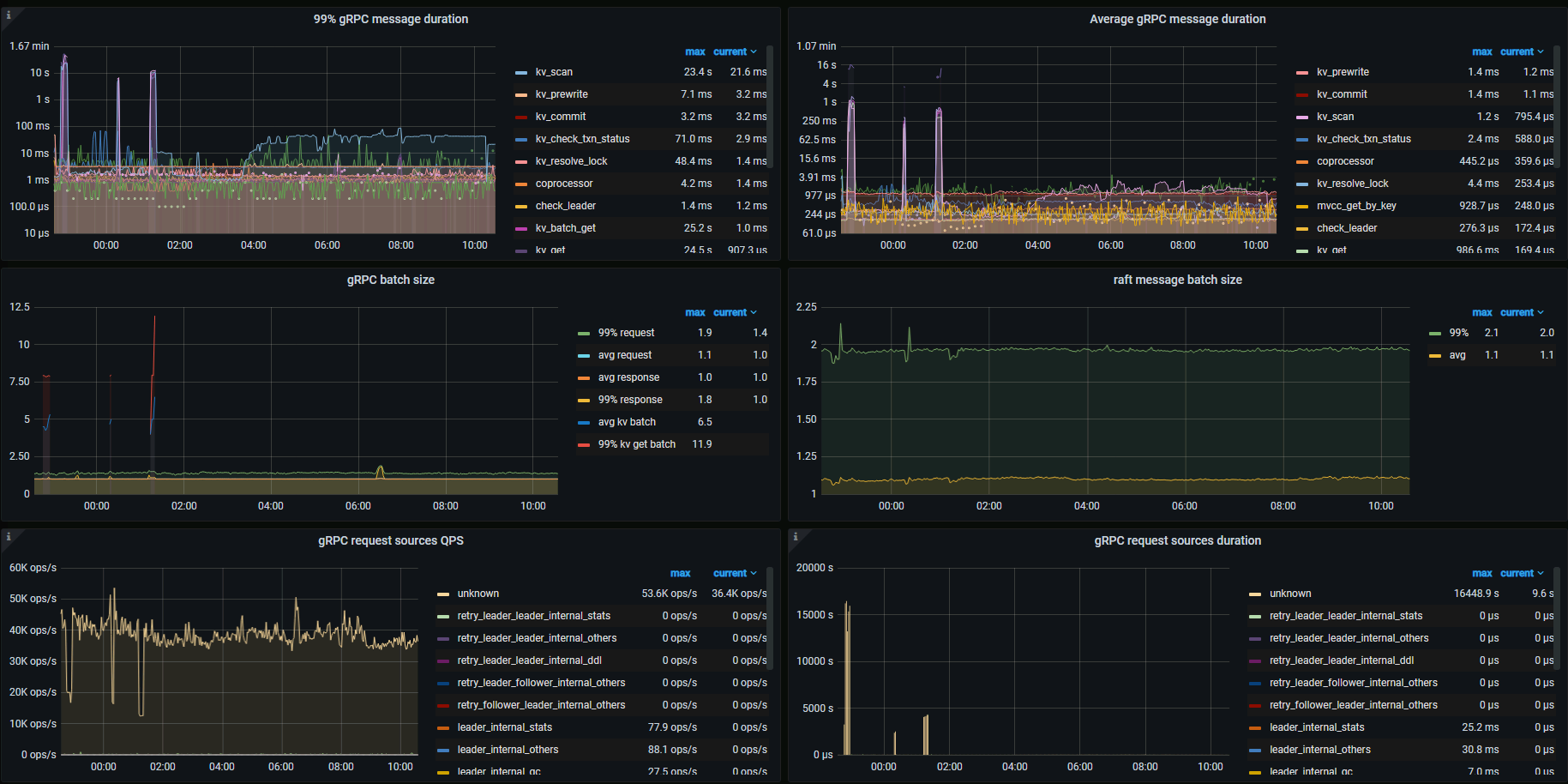
【附件:截图/日志/监控】
下图中 gRPC message duration 飙高对应的时段为故障时段。
【 TiDB 使用环境】
生产环境
【 TiDB 版本】
v7.5.0
【复现路径】
通过 JuiceFS 方式使用 TIKV,直连 PD。具体原因不明,可能与大量写入有关。
【遇到的问题:问题现象及影响】
故障期间 JuiceFS 大范围客户端元数据时延飙高
【资源配置】
这期间有没有什么操作?
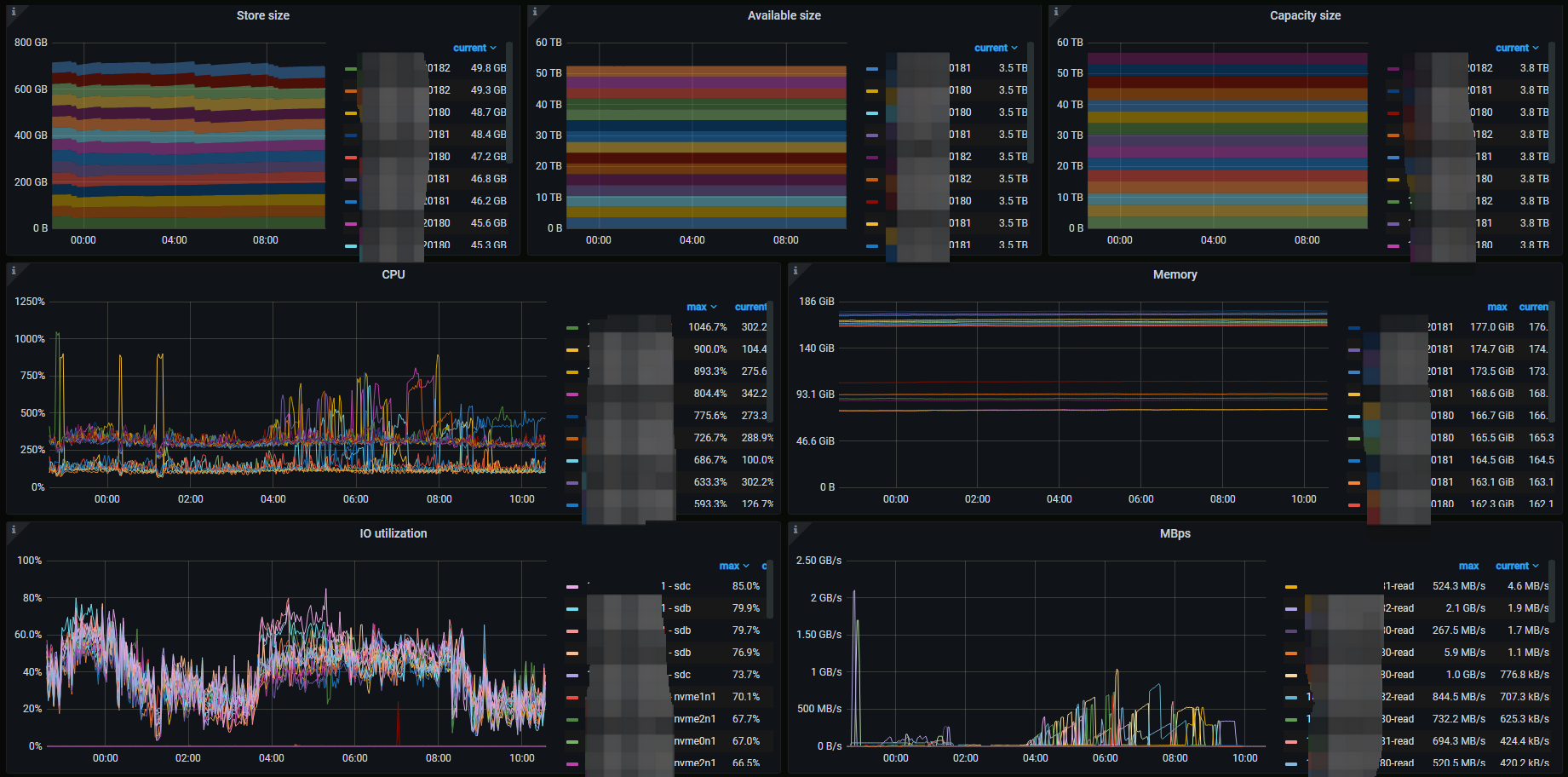
存储侧是没有的,业务侧的qps可能有增高。期间 TiKV_async_request_snapshot_duration_seconds 这个指标有告警,有一个节点的 Read Pool CPU 打的比较高,有800%。
看着像是当时有大范围的数据扫描(kv scan),导致 CPU 使用率升高,进而影响了其他业务。
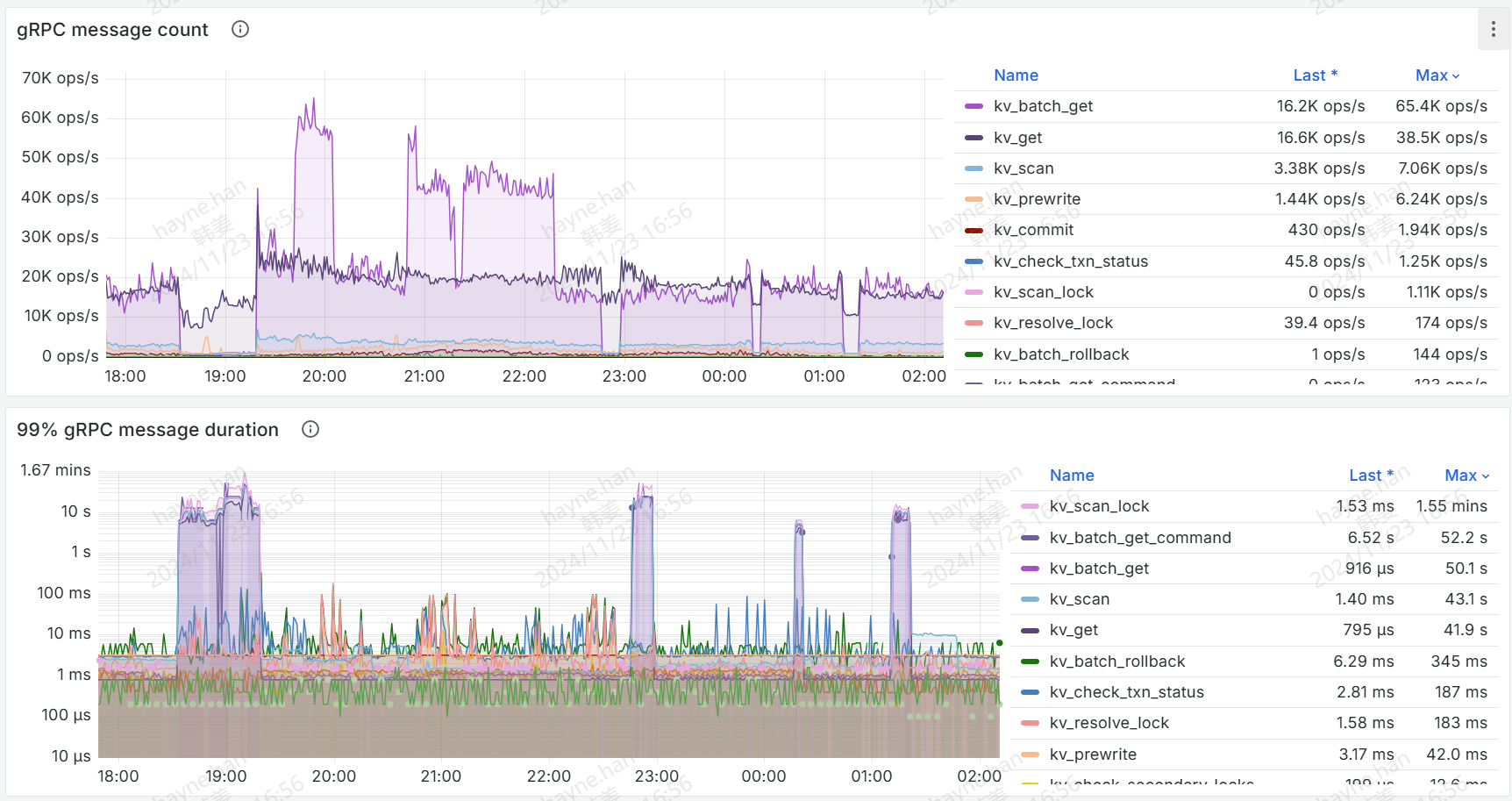
看一下 gRPC message count。
dashboar的热力图能看到有没有热点么?
故障期间,gRPC message count 基本掉0了。gRPC batch size 比较大,前后的 batch get 比较多。
这个我下周上班的时候关注下。
如果是读写热点问题看:https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues
写堆积的话,可以考虑调高一些 cf 参数:专栏 - TiDB 5.1 Write Stalls 应急文档 | TiDB 社区
1、检查TiKV的监控指标,特别是Grafana → TiKV → errors监控,确认具体busy原因。
2、查看TiKV RocksDB日志,确认是否存在write stall现象,这可能是由于level0 sst太多导致stall,可以通过添加参数[rocksdb] max-sub-compactions = 2(或3)加快level0 sst往下compact的速度