【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1.1
【遇到的问题】
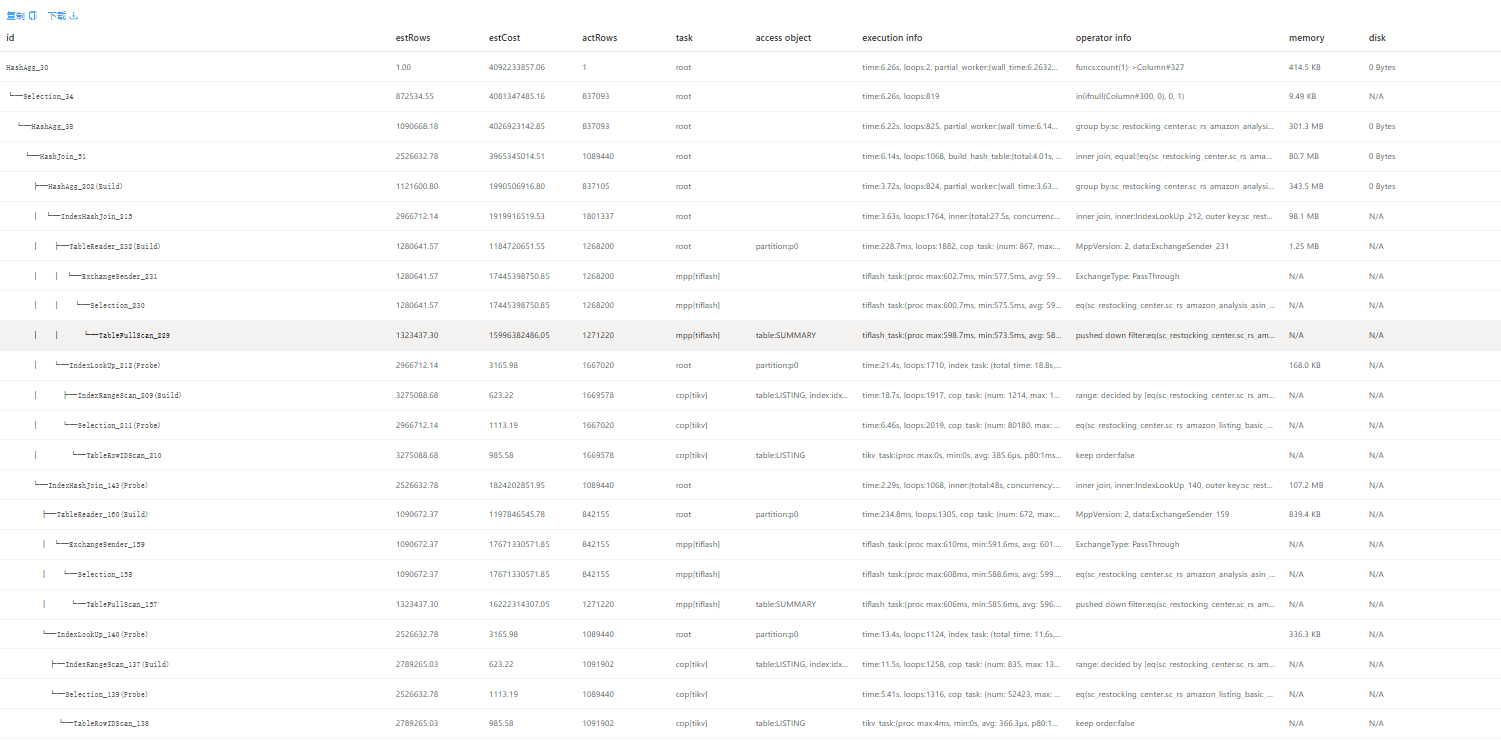
1,现在有两套tidb,并且表单的数据量都是2亿左右,现在在相同的表(建表语句相同)执行相同的sql发现执行计划不一致
截图为:
这是查询速度较快的集群:查询耗时6s
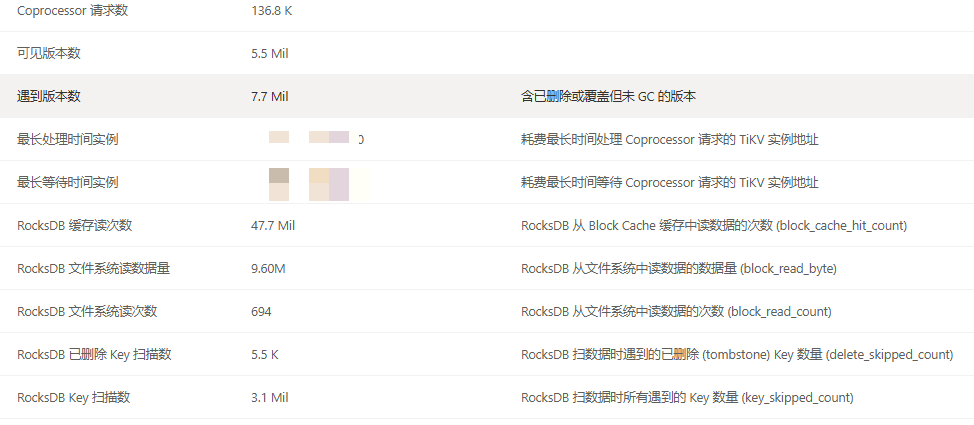
这是耗时较久的集群,20s
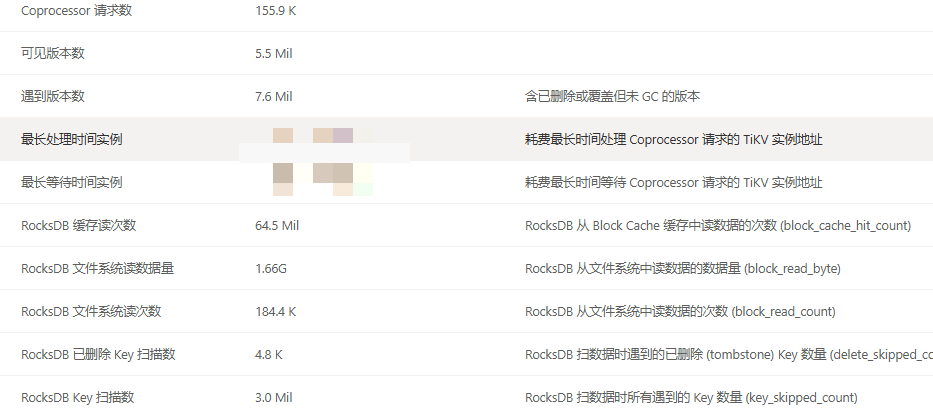
为什么会出现这样的结果,新集群tikv配置是32C128G15台,反而变慢了 ,只有节点数量的区别,旧集群21台16C64G
【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1.1
【遇到的问题】
1,现在有两套tidb,并且表单的数据量都是2亿左右,现在在相同的表(建表语句相同)执行相同的sql发现执行计划不一致
截图为:
这是查询速度较快的集群:查询耗时6s
为什么会出现这样的结果,新集群tikv配置是32C128G15台,反而变慢了 ,只有节点数量的区别,旧集群21台16C64G
那么返回的数量是否相同呢
就只是一个count(*)的语句 返回页数
数据量一样执行计划不一样,先analyze再看看
新机器肯定是更好的。
你看看读取数据量,一个9.6m一个1.66g,大了快200倍了,只慢了14s。
数据分布、统计信息、 查询优化器的差异等诸多因素都会影响到这个执行计划的差异
猫哥 但是16c的集群查询这个sql只需要6s 现在新集群都要20s 不知道哪里出了问题
执行计划不一样,扫描的次数太多了。
能看看具体的执行计划是有什么差异吗?
这两个执行计划是一样的。时间差异这么大,确实奇怪。
这么看还不是执行计划差异导致的变慢。
令人费解。
磁盘型号都一样的?
都是nvme盘
用explain analyze 检查扫描的key数量
有没有热点或者数据倾斜。文件系统读取次数明显是没有预热,内存缓存太少
如何预热呢?
有优化的 调越大越快
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。