TiFlash存算分离架构查询偶尔会报“no alive tiflash, cannot dispatch BatchCopTask”的错误,但实际上,TiFlash Write 节点和 Compute 节点当时都没有重启。

1 个赞
偶尔,还是会持续…
感觉是元数据的读取和处理上,有点逻辑问题了
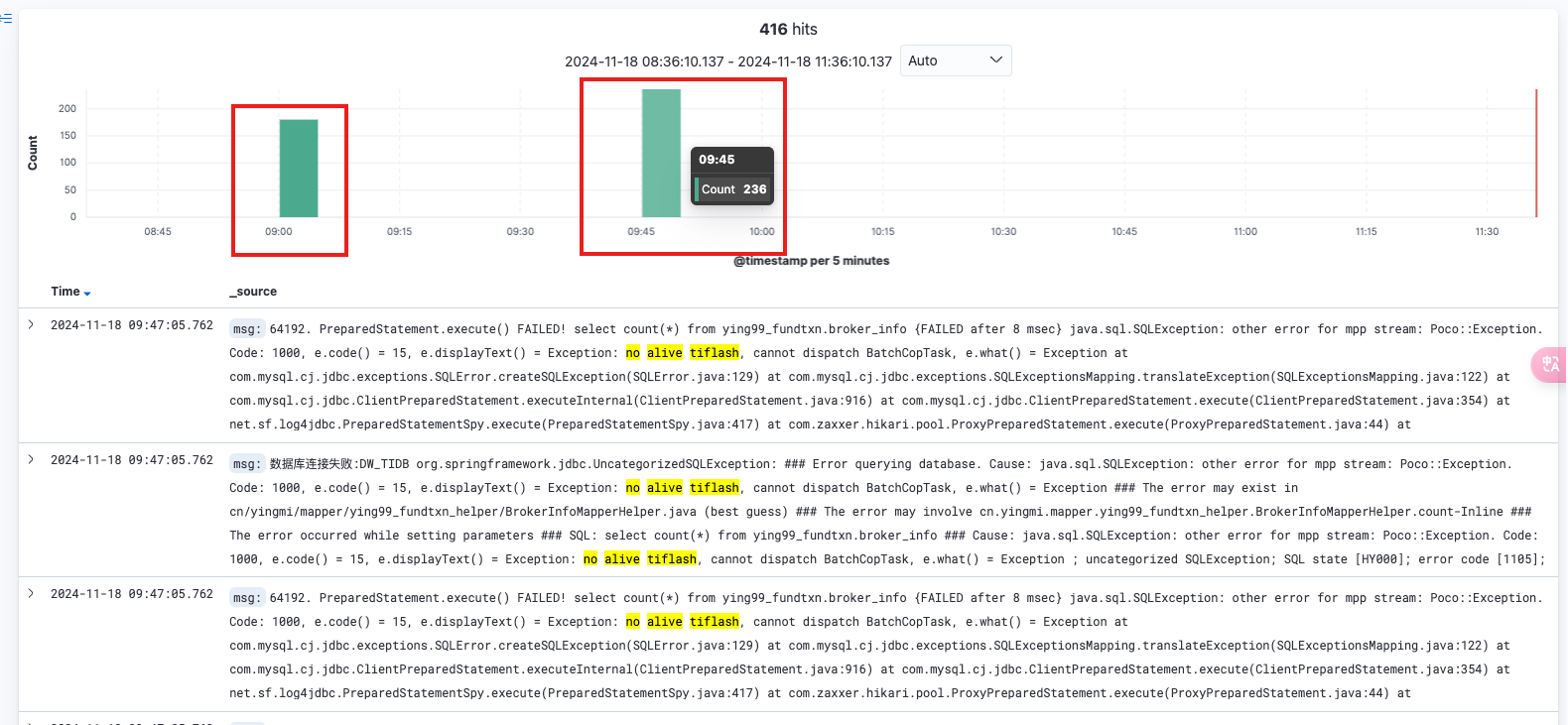
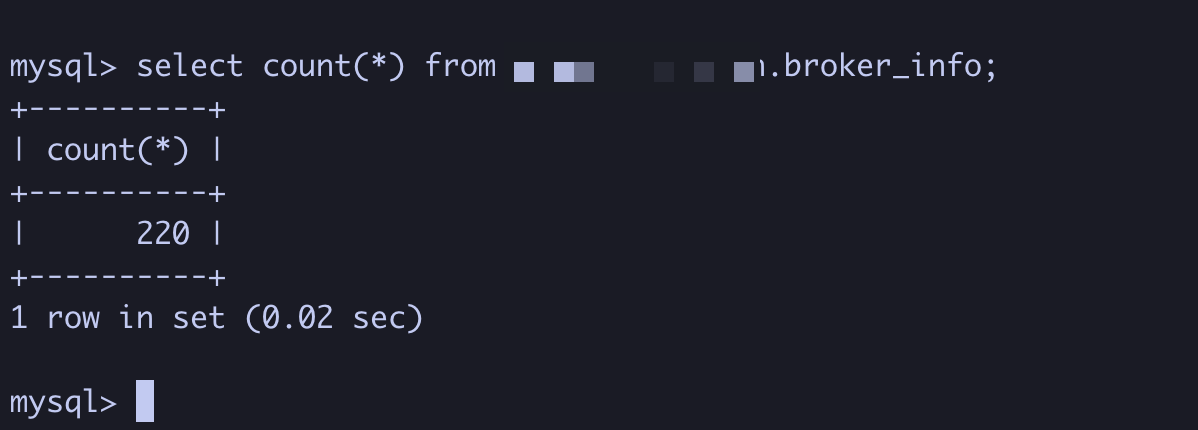
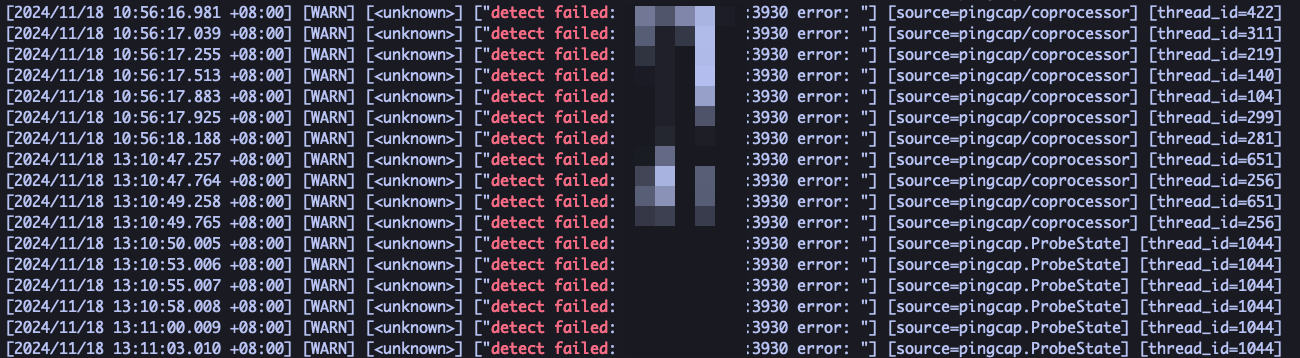
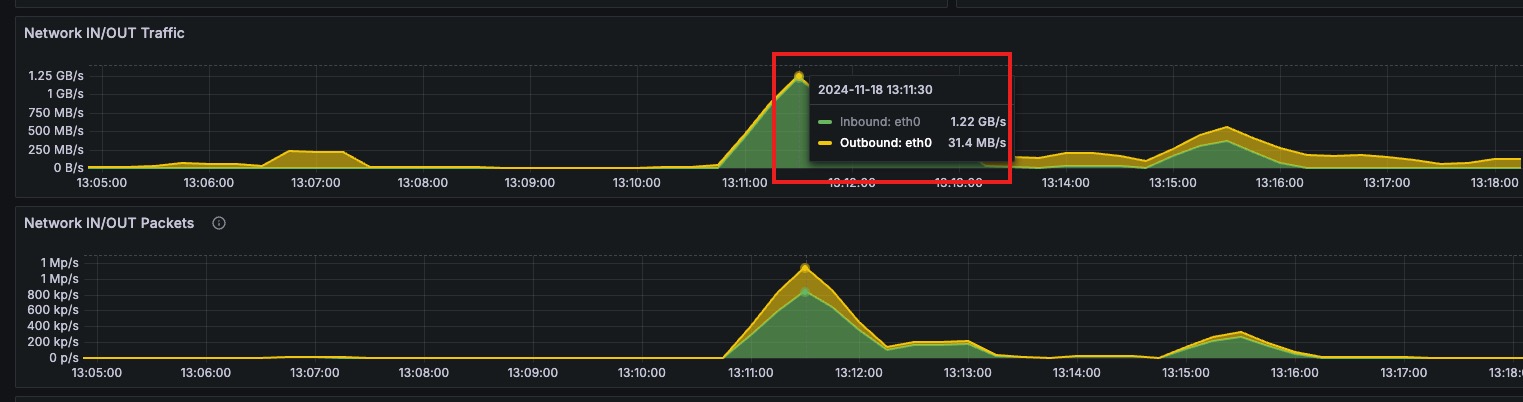
在存算分离下,当查询请求没有命中 compute node 的 local cache 情况下。查询请求的数据会直接从 S3 读,然后再添加后台任务下载 S3 文件到 compute node 本地缓存。这个时候峰值流量太大,导致了 compute node 与 write node 之间的探活请求超时(2s),compute node 认为 write node 失联了,无法下发读取任务。一般业务端重试,读取相同的数据会命中 compute node 本地缓存,S3 读取流量减少,任务可以成功。
所以限制后台下载的并发,理论上能够减少峰值流量。
profiles.default.dt_filecache_max_downloading_count_scale
这个 tiflash 配置参数可以调整 compute node 从 S3 下载的排队任务数。调小的话,影响从 S3 下载 Cache 到本地的并发,后续访问相同数据的时候读取速度会慢一些。以及 S3 文件的读流量会增大。
并发任务数是 (这个参数 * 逻辑核心数 * 5)。可以调整到 0.2 试试有没有缓解。
如果业务突发请求,导致数据只能直接从 S3 下载导致打爆了网卡,那考虑从限制读取的并发来看能不能缓解。
tidb 的 session 变量 tidb_max_tiflash_threads,限制每个请求在 tiflash 上执行的并发数
tiflash 配置里面的 profiles.default.dt_read_thread_count_scale,限制 tiflash instance 级别的 table scan 的并发。默认是 2.0,代表并发为 2.0*逻辑核心数。
或者试试 resource control 的 RU 限制能不能帮你平缓一下请求。
我们就是第二种情况,是业务突发请求直接从 S3 瞬时下载数据太大导致的。目前只能是限制通用查询并发来限制了,但是希望后续能增加一下读取 S3 的一些限流措施,因为 S3 这类云服务往往都会有 QPS 或者 带宽限制,如果瞬时流量太大,运营商会直接限流,导致查询失败的。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。