上周六下午(10月26日),TiDB 地区交流活动在杭州圆满举办!本次活动由 TiDB 社区杭州地区组织者——电魂网络任嘉伟老师与杭州银行邵健老师精心筹办,来自电魂网络、杭州银行、bilibili、安能物流、Databend、云猿生、美创科技、PingCAP 等多位资深技术专家齐聚一堂,共同探讨 TiDB 在各行业的创新实践和技术应用。
Databend 云平台研发工程师韩山杰老师受邀参加本次活动,并带来专题分享《数据库归档业务用户福音: TiDB+Databend,降低数据归档成本》。 他详细介绍了如何通过 db-archiver 工具将 TiDB 中的冷数据归档到 Databend,充分利用对象存储的优势帮助企业高效优化存储。同时,他还展示了如何轻松将数据从 Databend 恢复至 TiDB,以便在需要时快速取回归档数据。

韩山杰,目前在 Databend 主要负责云平台的研发,以及 Databend 生态工具的开发和维护,包括 Databend 多语言的 SDK、ELT 工具的研发与集成,例如 airbit、Kafka connector、Flink connector 等工具。此外,他还在 CNCF 的 OpenKruise 项目中担任 Maintainer。
以下是精彩演讲实录:
目前数据归档普遍面临的挑战
随着数据量的爆炸性增长,如何高效管理和归档冷数据已成为当今企业面临的重要挑战。
![]() 数据量激增
数据量激增
随着企业数字化转型,线上业务不断增长,产生的数据量呈指数级增长,这给存储和管理带来巨大压力。后续如果想对这部分数据进行分析或二次加工,可能会对线上业务产生压力。
 兼容性问题
兼容性问题
归档后的数据若需再次查询或使用,往往需要对业务代码进行大量改造,增加了使用的复杂性。
![]() 归档工具
归档工具
目前,从 TiDB 到 Databend 的归档工具可选择性较少,且使用不方便。比如 Datax 虽然是大家使用较多的归档软件,但其编译后的体积非常大,编译速度慢,并且社区维护状态不佳,基本处于半维护状态。
 成本控制
成本控制
如果将大量历史数据一直存储在 TiDB 中,需要投入大量的硬件资源和持续的维护成本,给企业带来一定成本压力。
为什么选择 Databend 归档 TiDB
为了解决以上这些痛点,我们需要找到一个合适的归档方案来归档 TiDB 的数据,降低数据存储在 TiDB 的成本。在这一背景下,Databend 成为理想的归档目标。
![]() 高效的数据存储和查询能力
高效的数据存储和查询能力
TiDB 作为一个分布式的 HTAP 数据库,可以快速处理大规模的联机交易数据。而 Databend 是一个云原生的分析型数据库,擅长处理大规模的数据分析任务,它的计算能力是很强的。结合这两者,我们就可以实现高效的数据存储+分析,并提供非常快速的高并发查询能力。
灵活的存储架构
TiFlash 列存引擎和 TiKV 行存引擎,可以面向业务提供 80% 的 OLTP 能力 和 20% 的 OLAP 能力。Databend 提供的也是一个列式存储,拥有非常好的压缩比,并且使用对象存储作为后端存储,可以大幅度降低数据存储成本。
![]() 良好的扩展性
良好的扩展性
TiDB 和 Databend 两者都是分布式系统,可以通过增加节点来线性扩展整个系统的计算能力和存储能力,从而让系统能够轻松应对不断增长的数据归档需求。
云原生架构
TiDB 和 Databend 都能支持云原生部署,可以充分利用云计算弹性伸缩节点,按需付费的优势。Databend 采用存算分离架构,计算节点在不需要做计算的时候,可以直接缩掉,仅保留后端对象存储的费用,从而实现极致的成本节约。
玩转 TiDB + Databend 进行数据归档及恢复
为了将 TiDB 的数据高效归档到 Databend,我们自研了一个 db-archiver 归档工具 (https://github.com/databendcloud/db-archiver)。该工具能够实现从 RDBMS 进行全量或者 T+1 增量归档数据,并且能够针对 MySQL、TiDB、PG、Oracle 等多种数据库进行归档。
下面这张表是从 TiDB 归档数据到 Databend,使用 db-archiver、Datax 和 pt-archiver 的对比。其中,pt-archive 是仅 MySQL 生态的,所以它只能支持 MySQL 生态的一些数据库,而且 pt-archive 在同步过程中只能是一个单线程的同步,所以同步效率是比较慢的。

简单介绍一下 db-archiver 的架构设计, db-archiver 从设计之初就支持多数据源,增加新的数据源也非常简单,只需要去实现代码里对应的接口就可以。
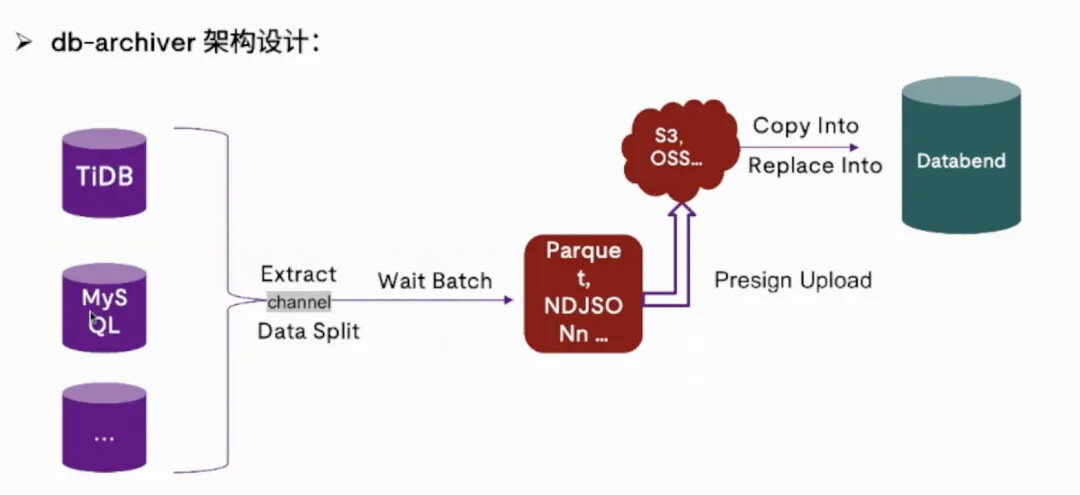
**整个架构主要分为三大部分:**第一部分是数据切片和数据抽取的模块。db-archiver 里内置了一个数据切片的算法,会根据用户提供的同步数据的范围,需要同步的线程数量,以及提供的 batchSize,来对源端的数据做切片,这样做的优势就是可以最大限度减轻对源端的抽取的压力。抽取完之后, db-archiver 会把抽取的各个部分的数据,在各个线程里攒批,充分利用目标端的写入能力。Databend 作为目标端,它的写入能力是非常强的,所以你完全可以在每个线程里去等待一个比较大的批次,然后把它生成 Parquet 或者 Json 的文件,传到 S3 上,最后利用 Databend 的 copy into 或者是 replace into 的能力,将这个文件写入到 Databend 的表里。
下图是 db-archiver 在同步过程中的一些指标和日志情况。为什么会有这么丰富的指标和日志?

举一个我们给客户实施过程中的一个真实案例:有一个客户的数据存在腾讯云的 MySQL 上,他要将这部分 MySQL 的数据归档到 Databend,在使用 db-archiver 工具同步的过程中,他发现整个全局的同步速率并没有达到理想的效果。然后他就找到我们问同步的速度为什么这么慢,这时候我们就建议他把这个指标的开关打开。打开之后就可以看到每个过程中的指标都会被打印出来,然后我们就可以分析看一下到底是哪一个环节出了问题。
当时我们看到他在 upload stage 的时候耗时非常长。upload stage 其实是 db-archiver 将文件写入到对象存储中的一个过程,我们怀疑客户部署 db-archiver 的这台机器和目标端的对象存储不在一个区域,这就产生了一个跨网段的情况。用户回去排查之后发现确实是这个问题,然后他把部署 db-archiver 的机器换成与源端、目标端都在同一个 region 后,同步的速率就上去了。所以说我们提供了这样丰富的指标,对于完成一次完整的数据归档也是非常有帮助的。

上图是一个内置的数据切片算法的简单介绍。db-archiver 支持按照主键 ID 或者是时间字段来对数据进行切片。
我们以主键 ID 为例,看一下数据是怎样一步一步被切成一个个比较小的片段。在配置文件里有一个叫 source where condition 的字段,这个字段会限定用户本次归档的一批数据,我们会从里面拿到一个 min(id) 和 max(id),同时把一个大的数据范围,按照用户给定的现成的数量分到不同的线程里,然后每个线程再按照 batchSize(每次想要同步的批次数量),再去切分到一个小的范围,然后去源端去做抽取,并在抽取的过程中根据对源端的压力,做自适应调整。

上图就是是一次同步过程中需要做的配置文件。databaseType 就是之前指定的数据库类型,如 TiDB、MySQL、PG、Oracle 都是可以的。源端配置中比较关键的就是 sourceDbTables,我们可以按照正则表达式来匹配对应的数据库对应的表,实现一个多数据库多表的同步。批次相关的一些配置,主要是根据执行 db-archiver 的机器配置,或者整个网络情况来去做的设定。每次同步之后 db-archiver 也会去做一个数据校验,可以配置 db-archiver 自动清理源端的历史数据,快速把存储释放。
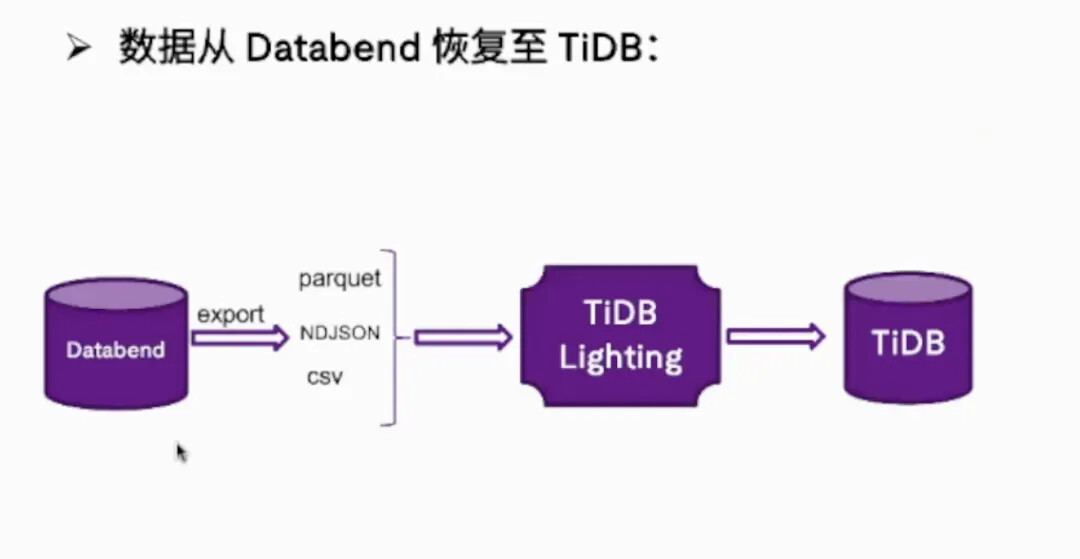
在实施数据归档的过程中,有些用户可能会有一些顾虑:数据归档到 Databedn 之后,TiDB 的数据随之就被删除掉了,会不会有一天有一部分数据想要再恢复到 TiDB 中,来做一些别的用途怎么办?其实数据从 Databend 恢复到 TiDB 也是比较简单的,因为 Databend 支持导出 parquet、NDJSON、CSV 等格式,同时 TiDB 也提供了一个 TiDB lighting 工具,可以快速把这些格式的文件数据加载回 TiDB,完成一次数据恢复的过程。
TiDB + Databend 归档实战案例
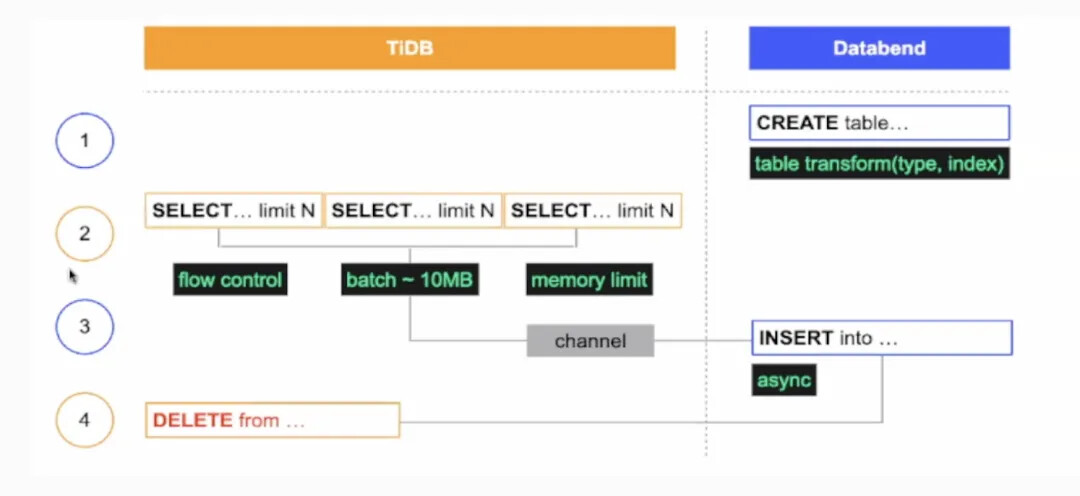
上图是多点当时做的一个数据归档方案。整体来说与 db-archiver 差不多,也是先切片、攒批、多线程 insert into 的动作。insert into 后校验通过,也会把原来 TiDB 的数据删掉。区别可能有两点,第一点是它源端只支持 TiDB。第二点是它写入 Databend 的方式是 insert into。其实 Databend 对于大批量写入数据的最佳实践是建议用户使用 copy into,会更加简单和高效。后续如果想改成 replace into,也会更加简单,用replace into 可以根据主键做一些去重操作。比如我们在同步过程中可能会有一些重试的操作,假如用了 replace into,就可以确保根据主键在目标端做去重。
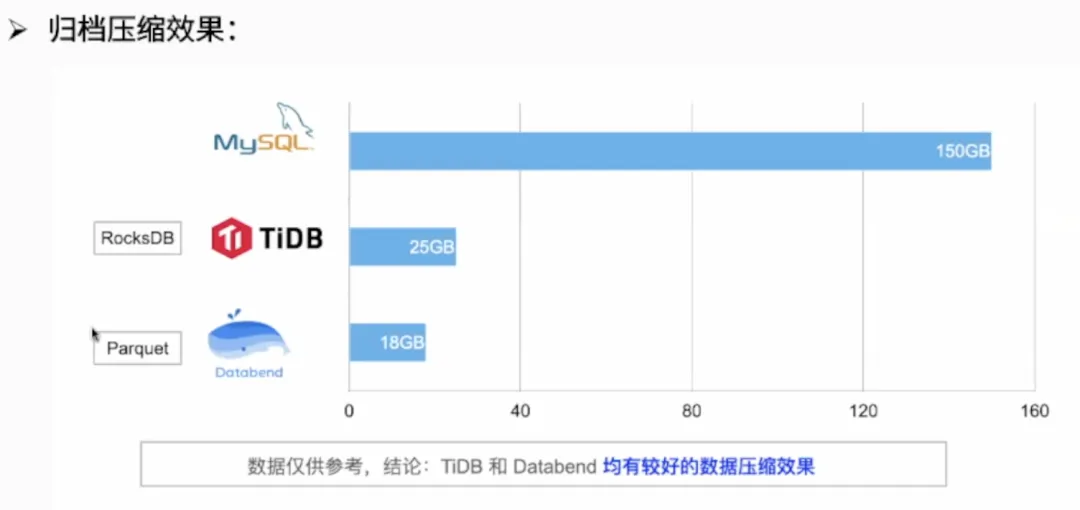
上表是他们在归档前做的压缩测试,他们把 MySQL 中 150GB 的数据导到了 TiDB 和 Databend 中,可以看到 TiDB 和 Databend 的数据压缩效果都是不错的。TiDB 在自带的 RocksDB 上大概能提供 6 倍的压缩比,而 Databend 是一个 8 倍的压缩比。但这里的数据仅供参考,因为不同的数据格式在不同的情况下,二者的压缩情况可能不一样。
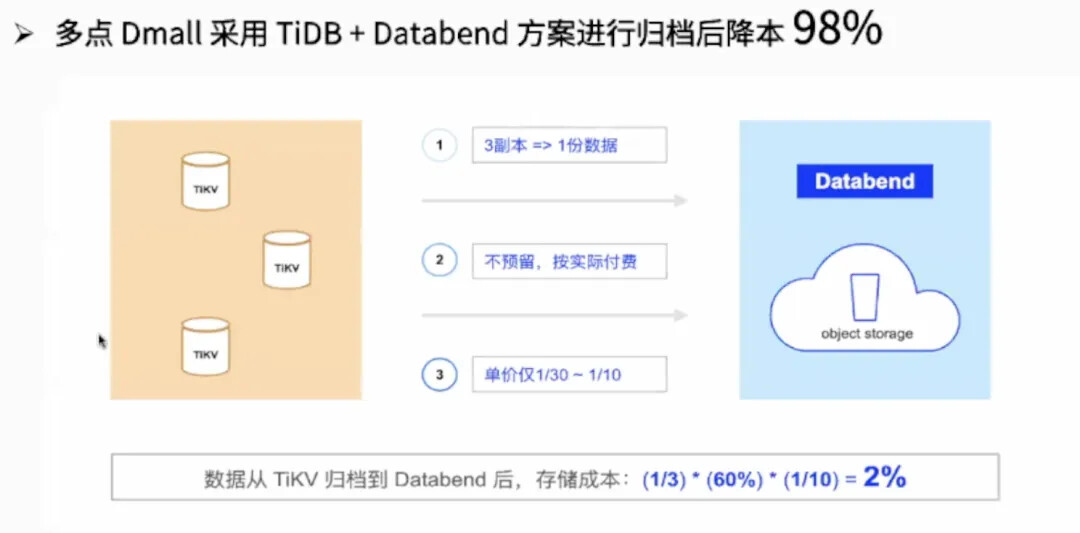
多点在采用 Databend 归档 TiDB 数据后,整个数据存储的成本降低了 98%。
多点能达到这种收益,主要有三个因素:
**首先是副本数量。**大家都知道,TiKV 是需要有 3 副本的,所以就会有 3 倍的数据存储。而 Databend 的后端是对象存储,只需要有一份对象存储的数据。当然其实对于对象存储来说,云上也会对对象存储做一些备份。但我们从成本视角来看,是只有一份数据的成本。
**第二点是存储预留。**我们在使用 TiDB 时后面硬件会挂磁盘,但我们不会让磁盘每次都用完,肯定会预留一定的水位。比如说后面挂了 1TB 磁盘,可能只会用到 600-700GB,留个 200-300GB。但对于 Databend 来说,它的后端存储是对象存储,你可以理解为这个对象存储是无限扩展的,按需使用然后再按需付费,你不需要额外预留一些存储成本。
第三点也是最重要的一个因素,就是存储单价 。 数据存储在块设备上或对象存储上,单价差别是非常大的。对象存储相较普通的 HDD 盘,成本可能只有它的 1/10。而如果说用 SSD 来作为存储数据的磁盘,对象存储仅仅是它的 1/30。所以当数据从 TiDB 归档到 Databend 后,整个存储成本就是 (1/3) 副本* 60% 的磁盘利用率*(1/10)磁盘价格,最终的数字就是 2% 的存储成本。假如后端采用 SSD 盘的话,数据成本还会进一步降低。

总结以下使用 Databend 归档的一些优势:
![]() 降本显著
降本显著
基于对象存储,冷数据的存储成本可以直接降低 98%;。
云中立
大家可以任意选择使用的公有云或者混合云,Databend 在后端存储支持 S3 协议,你可以使用 AWS 的 S3,或者 Azure、GCP、阿里云的对象存储,也可以自建 Mini-IO 也可以支持;
 研发友好
研发友好
Databend 支持 MySQL 协议,你去做一些在线查询,数据的导出,都是比较方便的。业务代码都不需要做太多修改即可直接运行;
运维无忧
成本降低可能是比较显而易见的,但其实对于运维来说,当把数据从磁盘迁到了对象存储,尤其是公有云的对象存储,你可以理解为这部分存储就免维护了。公有云的对象存储,比如 AWS 的 S3,SLA 能够提供到很多个 9 的高可用性。同时,因为 Databend 是云中立的,支持很多对象存储,你也可以避免运厂商锁定,对象存储的数据迁移是非常方便的。
总结
总结来说,结合 TiDB 和 Databend 的特性,我们可以构建一个高效、可靠、可扩展的数据归档解决方案。TiDB 用来处理实时的数据,而 Databend 则可以用于长期的数据存储和大规模的数据分析,如大范围的数据查询和分析,两者配合使用可以满足不同时间跨度的数据归档需求,同时保持成本是最低的。
其实对于 Databend 来说,只用 Databend 来做数据归档的话,其实是有点大材小用的。当你把数据归档之后,还可以用 Databend 来做各种大规模的数据分析,它的计算能力也是非常强的。
大家感兴趣的话,可以关注我们的公众号了解更多 Databend 信息。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
![]() Databend Cloud:https://databend.cn
Databend Cloud:https://databend.cn
![]() Databend 文档:https://docs.databend.cn/
Databend 文档:https://docs.databend.cn/
![]() WeChat:Databend
WeChat:Databend