【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
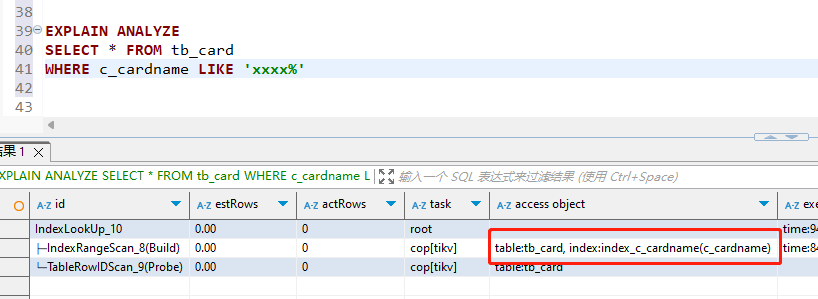
where条件like不走索引使用=可以正常走索引
表结构如下
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
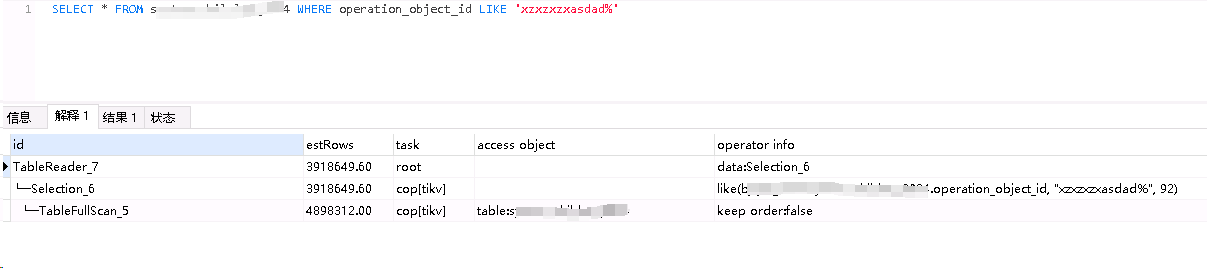
where条件like不走索引使用=可以正常走索引
表结构如下
1、从estrows看,select 过滤后 比 full scan 少不了多少。但如果走二级索引,因为查询条件是select * ,所以会有一个回表的过程,因此优化器更倾向于选择直接全表扫描。
2、首先确认二级索引的可选择率 distinct(substr(…))/table_rows;如果可选择率高,那么应该是统计信息更新不及时,重新更新统计信息即可。如果索引本身的可选择率就比较低,那说明该列不适合建索引或者以常规方式建不合适,可以考虑以逆序建索引。
使用 explain format=“verbose” 对比全表扫和use_index(operation_object_id)成本即可得知。
没啥问题吧,就是选择度太差。一共近500w数据有400w都符合你这个like条件,走索引回表400w次效果不是更差。
能like出8成的数据,还走什么索引啊,直接全表还比较快。
大点的表,如果sql查询数据占全表10%到20%以上通过索引筛选出来,数据库会倾向于走全表扫描
你这个语句应该是执行的explain select * from ,这个是预估的执行计划,
改为执行explain analyze select * from 试试,这个是实际的执行计划,有时候这两个还是有差异的。
另外楼上的大佬们说的也是对的,选择器会进行一个最优的选择,有的时候走索引不一定是最优解。