【 TiDB 使用环境】生产环境
【 rawkv 版本】V4.0.5
【遇到的问题:问题现象及影响】
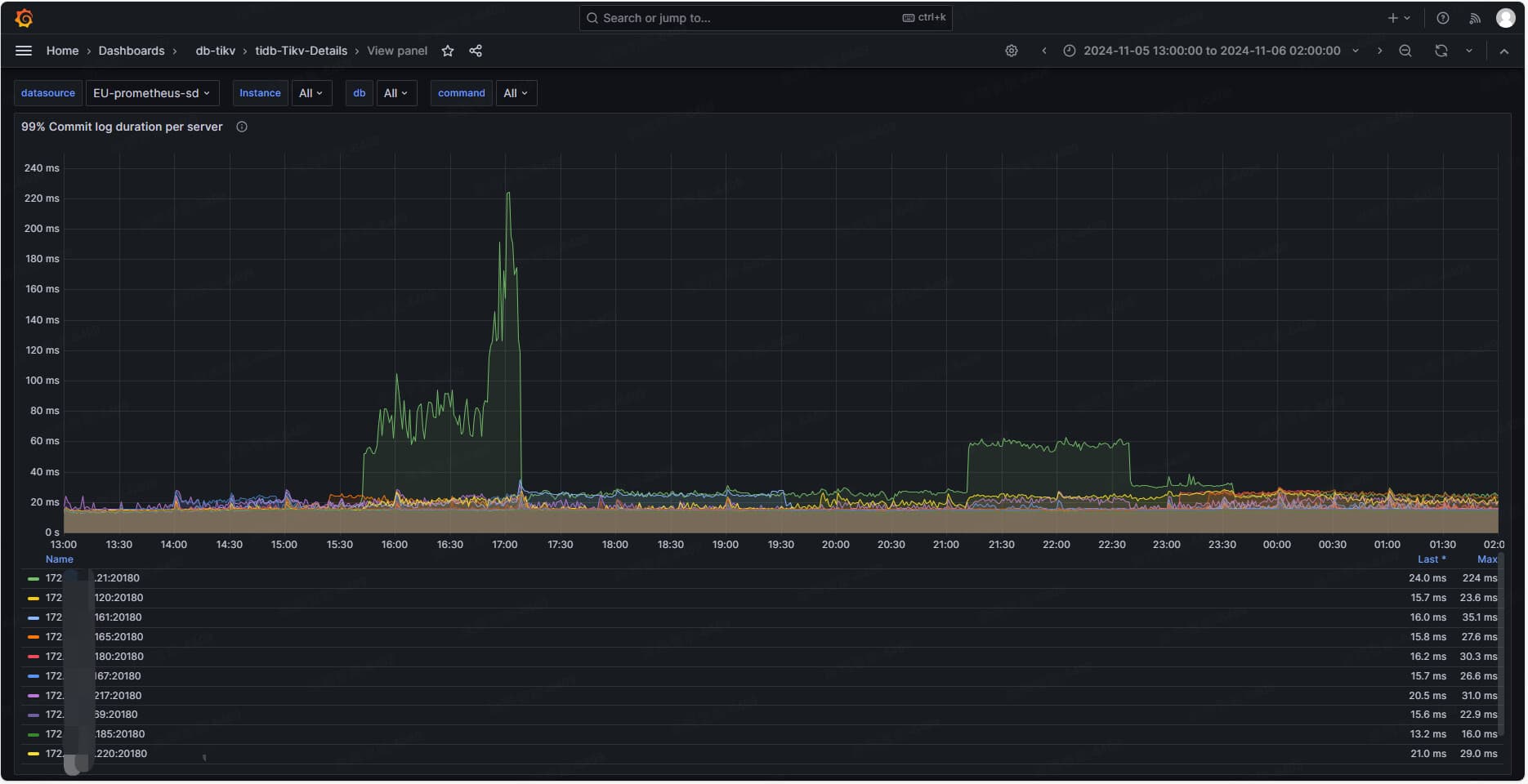
线上业务 gRPC message duration 经常变大,分析下来是 Commit log duration 变大的原因(基本 Commit log duration 涨多少 gRPC message duration 也涨多少),最后定位到是该 tikv 节点上 有 grpc server cpu 高于 90% 的原因。发现即便 grpc 整体 cpu 不高,但只要有其中一个 grpc server cpu 高于 90% 就会出现这个问题,且是稳定复现的

tikv 日志报错:
[2024/11/05 07:41:48.062 +00:00] [ERROR] [kv.rs:606] [“dispatch raft msg from gRPC to raftstore fail”] [err=RaftServer(Transport(Full))]
[2024/11/05 07:41:48.062 +00:00] [ERROR] [kv.rs:612] [“KvService::batch_raft send response fail”] [err=RemoteStopped]
[2024/11/05 07:41:48.138 +00:00] [INFO] [kv.rs:586] [“batch_raft RPC is called, new gRPC stream established”]
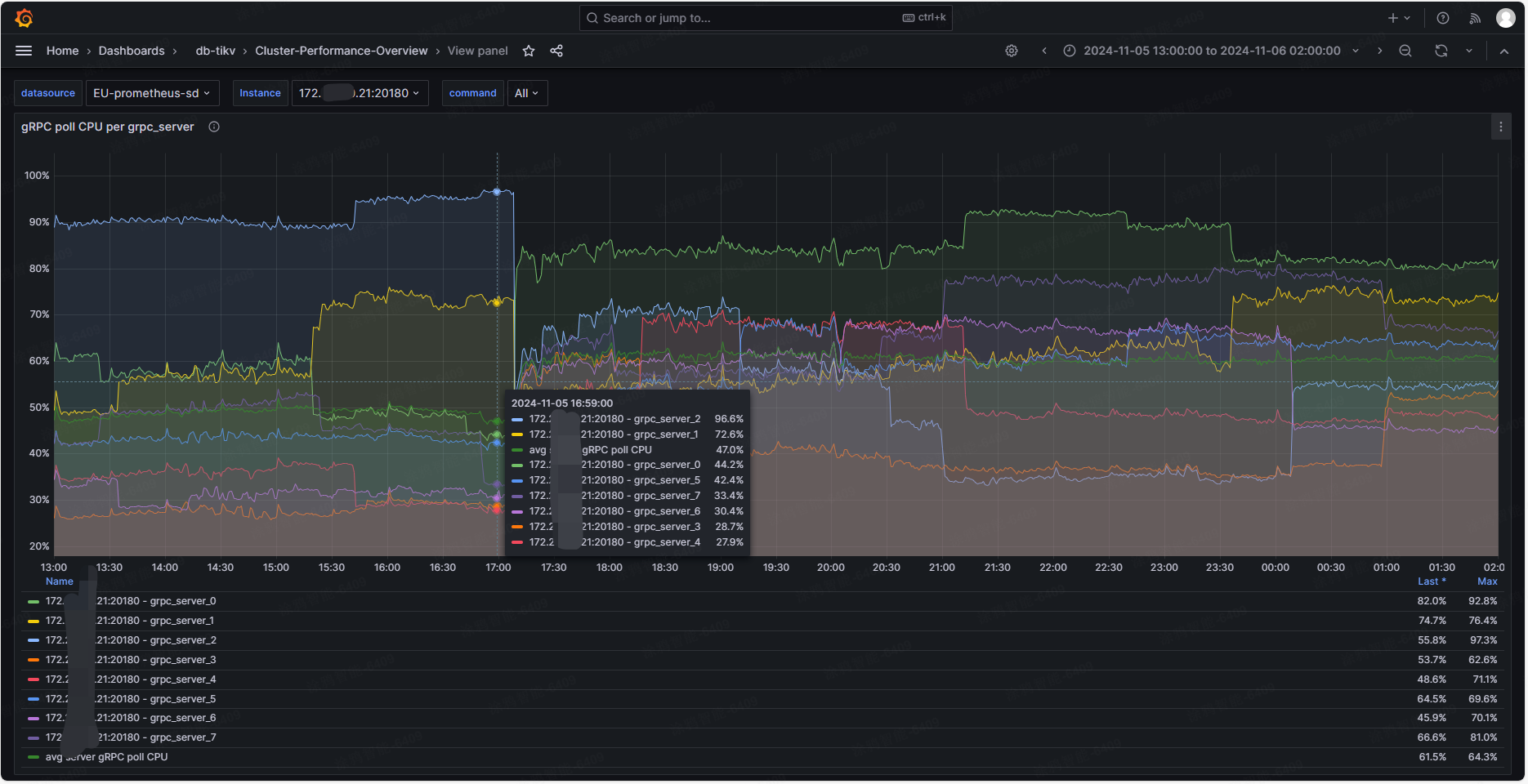
可以看到该 tikv 节点 grpc-concurrency 配置的 8,平均 grpc_server cpu 使用率在 50% 左右,说明 grpc 压力不大,但 grpc_server 间 cpu 使用率极不均匀。grpc_server_2 能有 96.6%,grpc_server_4 才 27.9%,一旦有 grpc_server cpu 使用率高于 90%,commit log 就变大了。从原理分析的话感觉这个问题在其它高版本也会有,毕竟单核 cpu 满了确实处理不过来延迟就变大了
想请教下各位大佬,grpc message 是怎么分配的,什么原因导致 grpc_server cpu 使用率差距这么大,该怎么解决这个问题呢。
【复现路径】
复现方法:将 grpc_server 进行绑核,绑核后对绑定的 cpu 进行压测,这样 grpc_server 所在 cpu 负载高处理消息就会变慢,commit log 就变大了
获取 grpc-server pid,查看绑核情况,将其绑到 cpu0 cpu1 上
top -H -b -n 1 | grep grpc-server
taskset -pc 10960
taskset -pc 10961
taskset -cp 0 10960
taskset -cp 1 10961
stress cpu 压测,并将 stress 绑核到 cpu0 cpu1
/root/stress --cpu 2 --timeout 600
top -H -b -n 1 | grep stress | grep -v S
taskset -cp 0 11632
taskset -cp 1 11633

- 15:31 对两个 grpc_server 绑定的 cpu 加压
- commit log 延迟变大
- 15:33 取消 grpc_server_0 所在 cpu 的压测
- commit log 延迟由 28ms → 15ms
- 15:37 取消 grpc_server_1 所在 cpu 的压测
- commit log 延迟由 15ms → 1ms