【 TiDB 使用环境】生产环境
【 TiDB 版本】v8.1.1
【复现路径】
无额外操作,部署完毕后即投入线上使用。
【遇到的问题:问题现象及影响】
【资源配置】
集群拓扑如下,通过 JuiceFS 直连pd。
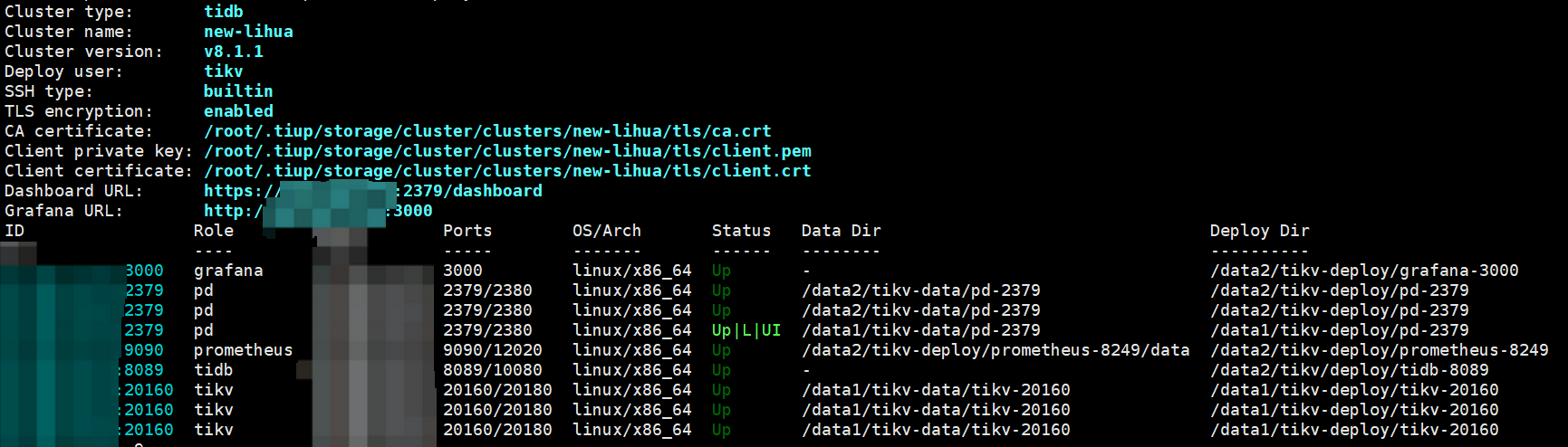
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v8.1.1
【复现路径】
无额外操作,部署完毕后即投入线上使用。
【遇到的问题:问题现象及影响】
【资源配置】
集群拓扑如下,通过 JuiceFS 直连pd。
有其他的异常情况么
JuiceFS 用的 client-go 是什么版本?
应该统计的是 gRPC Context.request_source,由 client-go 填入。
一些客户端偶有慢请求日志,比如获取TSO缓慢(200ms左右),或者是getTS超时。
这个要看网络配置和磁盘配置情况,可以查下 IO
TSO 获取后面的版本是batch 的方式获取的,而且是异步的,不会阻塞
单纯这个指标对集群状态没有参考价值吗?
如果要判断集群整体请求响应时间,参考哪个指标会比较有价值?
v2.0.4
看这个吧,内容会更全
pd跨子网了?到pd ping值多少?
tso慢一般来说就是网络不行,pd leader和其他什么组件混合部署了,导致cpu时间不够。
时延在1ms以内,我也不确定tso和这个监控指标之间的联系。
我现在的核心问题之一就是这个unknown的指标到底是什么含义?为什么会出现这个指标呢?
之前也有用过 juicefs+tikv 的架构,但就没出现过这个unknown的指标。当时的版本貌似才5.几的样子。
JuiceFS 有没有调用 KVTxn.SetRequestSourceType 设置 source?如果没有的话,client-go 就会上报 unknown,也就是在 TiKV 的监控里看到的 unknown
我在JuiceFS源码里目前没有看到。
所以我应当如何理解 gRPC request sources duration 这个指标呢?可以认为是tikv在某一时刻,所接收到的请求,从接收到处理完毕所花费的服务端总时长吗?
这个指标的意思是每秒 TiKV 处理这种类型请求的总时长。用于观察不同请求的占比
跟单个请求的处理“延迟”或者“耗时”是不同的概念
明白了,感谢。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。
