【 TiDB 使用环境】线上环境
【 TiDB 版本】v5.3.4
【复现路径】暂时没有复现
【遇到的问题:问题现象及影响】
故障现象:SQL 运行时间超过20000s以上
故障影响:影响线上业务跑批调度继续运行
诉求:解释这种离奇现象,进一步加深对TIDB的了解!
日志现象:SQL开始运行时间 2024-11-5 04:17:59 (startTS解释而来)
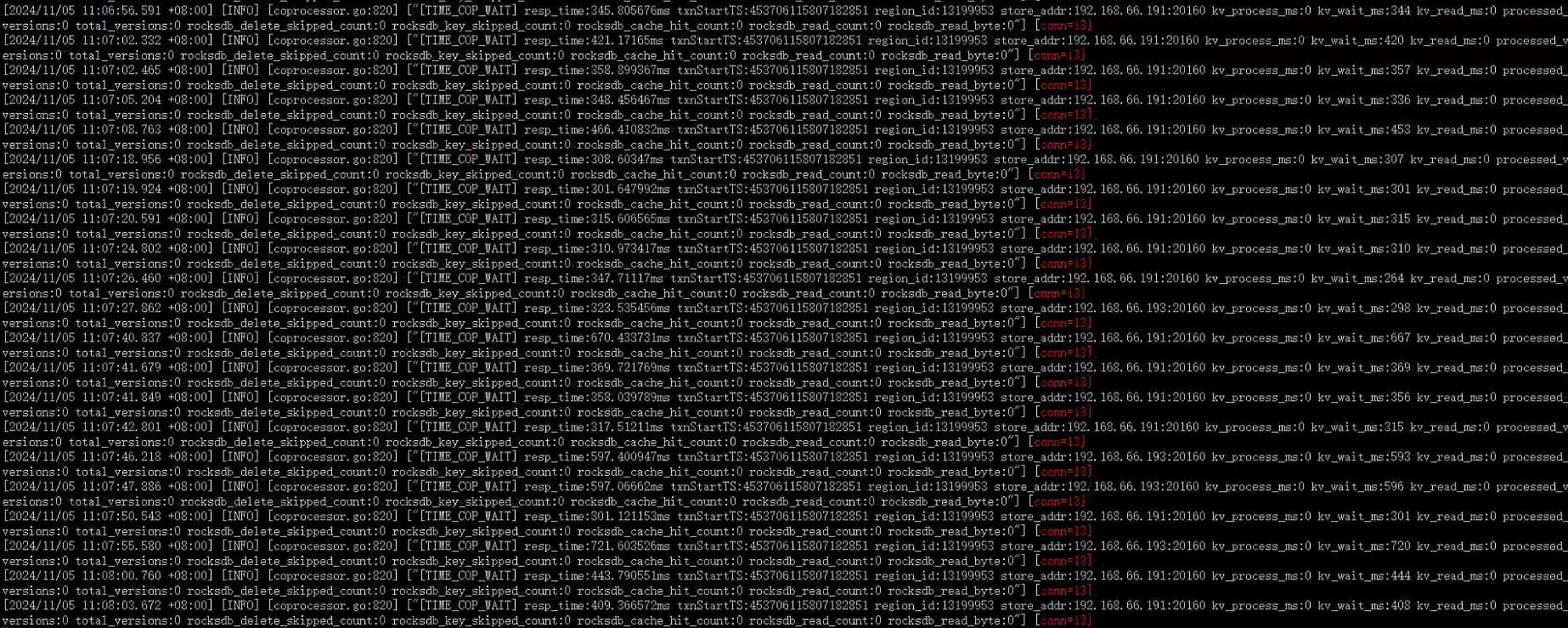
第一条空转日志:
其他空转日志:
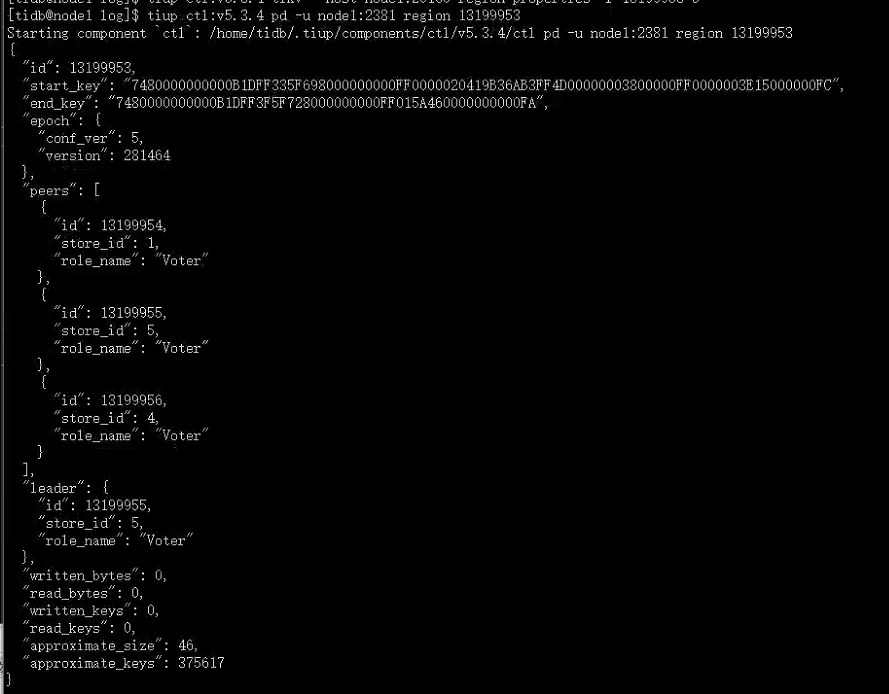
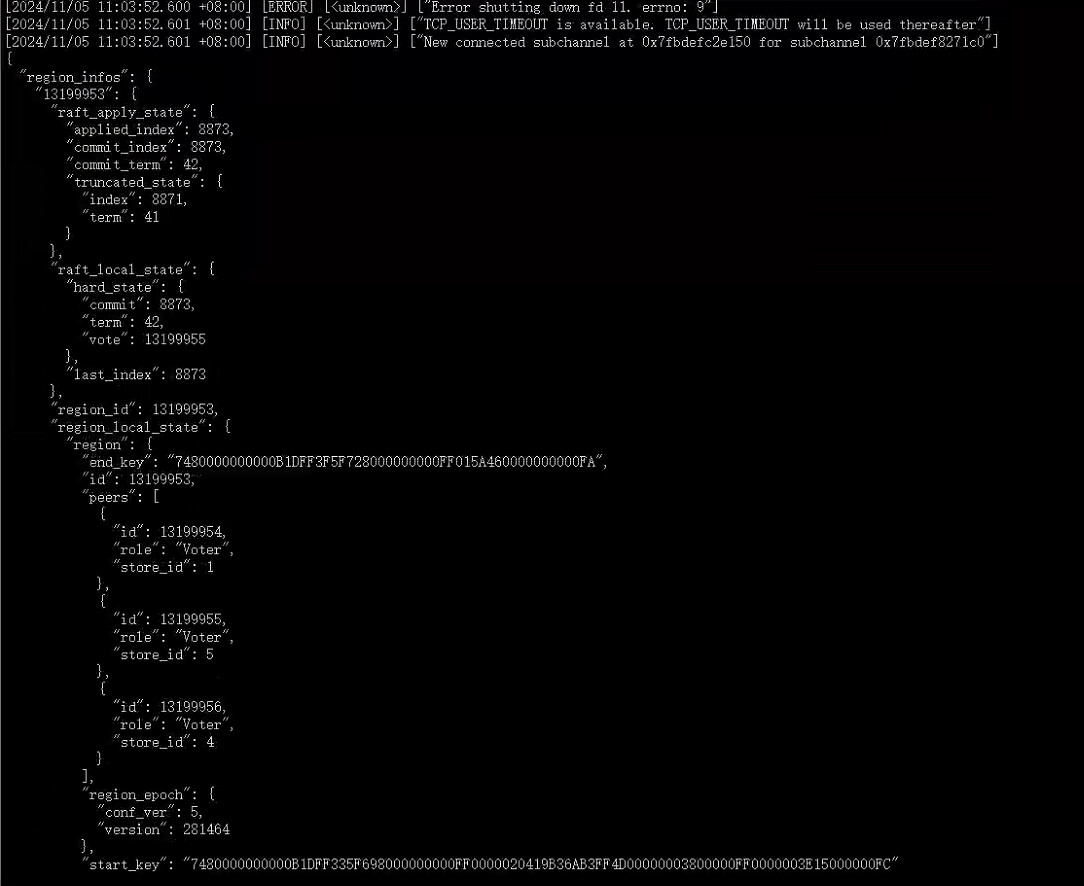
空转相关region 13199953 信息
其他尝试操作:
1、发现一直循环空读这个region,怀疑是region有问题。尝试手工split region后,发现新的region也开始循环空读,非常异常
2、尝试查询region中的表,发现select * 没任何异常,数据读取正常
3、尝试查询各个release版本BUG列表,无果(有可能漏了或者我不认识?)
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
xfworld
(魔幻之翼)
3
region leader 给迁移下试试(Region 的问题要从 PD 来排查了)
你的版本好低,不考虑升级么
这物理机好多内存,,哇~
版本升级是在进行中的事了,升级周期很长,估计得年后才能上线新版本啦。
我们线上所有版本都是5.3.4呢… 这个问题是第一次发生,挺奇怪的呢。
leader retransfer ,这个理论上我split后,会触发一次新region leader选举的。没留下截图 
小龙虾爱大龙虾
(Minghao Ren)
5
谢大佬指点。
这个当时看了,大概几百行的执行计划…SQL很庞大。所以我优先去分析的这个conn=13对应的 tidb/tikv输出的日志信息,发现仅有 上边截图的 rocksdb_read_byte 这些全为0 的信息,且已经无限循环了好几个小时。
我也想看看是什么sql,这个应该是执行计划生成的不对吧。贴下执行计划。
这个有没有看Region的调度状态和相关日志信息,有无Leader选举失败、Region分裂或合并失败等异常情况
这个确认过了,在term 42后,就稳定保持,leader恒定状态了。 没有region分裂和合并事件发生。 手动触发split,也一切正常。
已经通过 pd-ctl tikv-ctl 查看了region相关的信息,split尝试切割region。 v5.3.4 版本 我看也没有其他可以对region进行的操作了 
xfworld
(魔幻之翼)
12
找到region 相关的表,新建一个表,把数据迁移到新的,删除旧的表,这样这些region 就会被回收掉了…
这个方式可以解决你的问题么?
这个方法没用过。如果近期复现的话我试试!
region相关的表只有9800行,理论全部放入内存都不至于。
现象有点像是,读不出来… 但是服务器io也挺空闲的。
不知道有没有人遇到类似的BUG 。 我也是头一次遇到这么诡异的现象。
WalterWj
(王军 - PingCAP)
14
sql 执行慢的话,可以提供 plan replayer 发出来大家看看。
如果怀疑是 bug ,有什么地方夯住了,可以先执行 sql 再执行过程中,抓个 tidb debug zip,里面有 goroutine 内容,可以看到卡哪个线程,如果觉得是执行器问题、tikv 执行慢就再往下查。