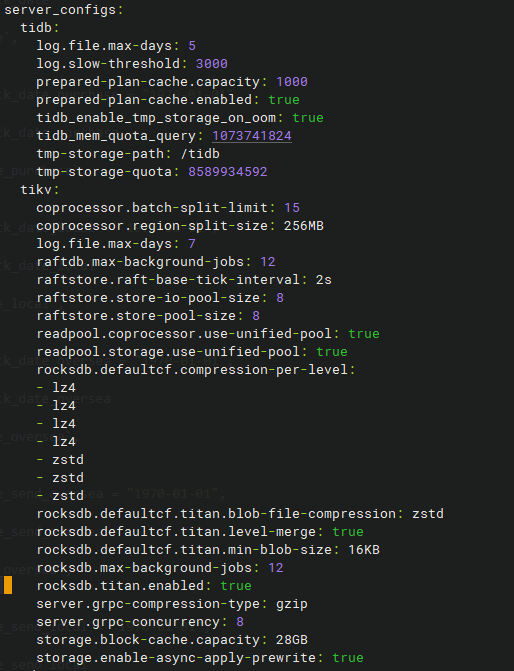
【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1.0
【查询sql】
SELECT
summer.parent_hash_id as hash_id,summer.com_id
FROM
normal_summer summer
INNER JOIN basic_detail LISTING ON LISTING.com_id = 9
AND LISTING.delete_flag = 0
AND summer.store_id = LISTING.store_id
AND LISTING.asin = summer.asin
WHERE
summer.com_id = 123
AND summer.delete_flag = 0
AND summer.node_type IN (1, 2, 3)
GROUP BY
summer.parent_hash_id,com_id
当前业务所涉及的sql都类似上述sql,较多做了连表查询
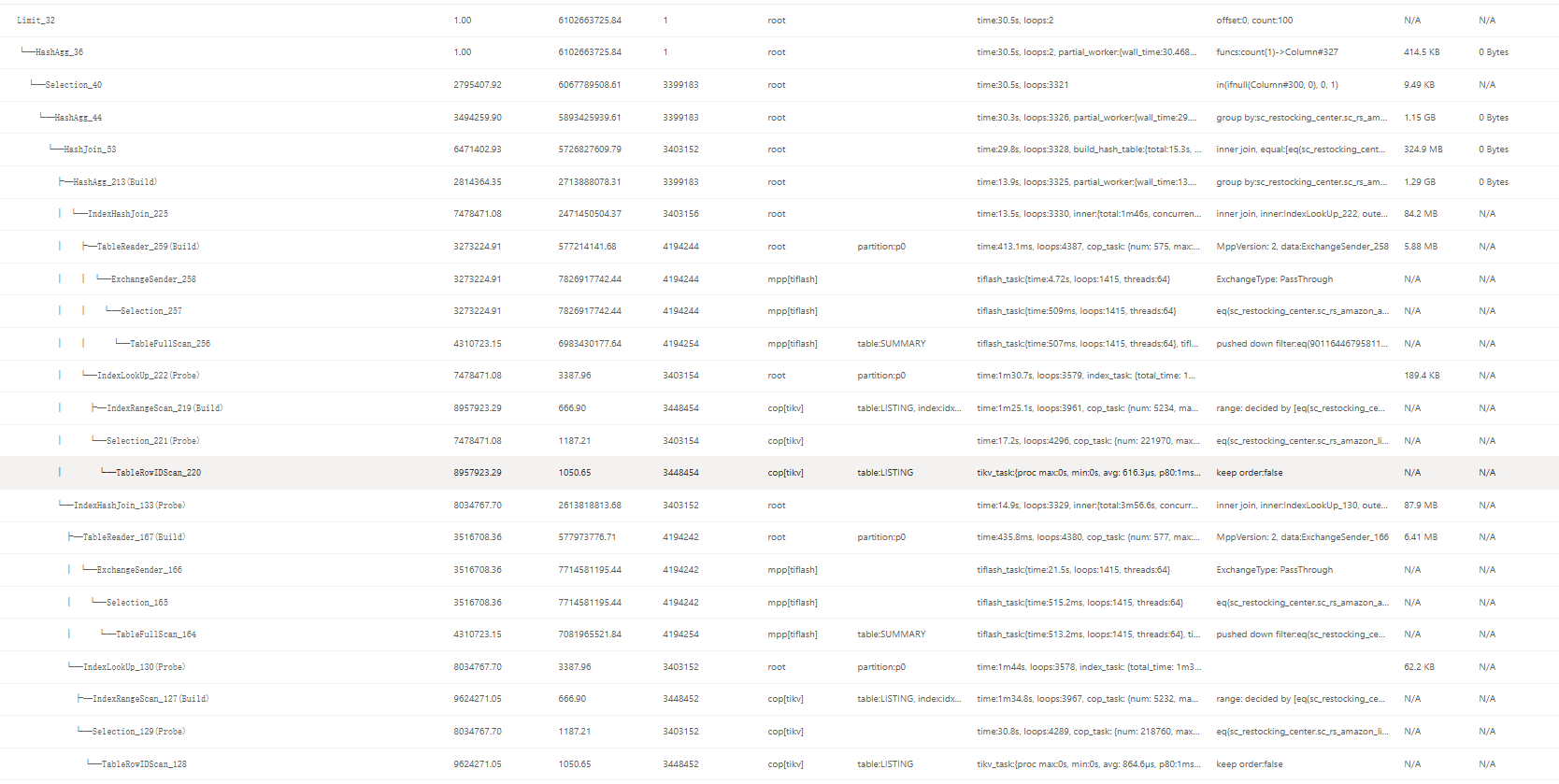
explain analyze SELECT
SUMMARY.parent_hash_id as hash_id,SUMMARY.company_id
FROM
normal_summary SUMMARY
INNER JOIN basic_detail LISTING ON LISTING.company_id = 1
AND LISTING.delete_flag = 0
AND SUMMARY.id = LISTING.id
AND LISTING.a = SUMMARY.a
WHERE
SUMMARY.company_id = 1
AND SUMMARY.delete_flag = 0
AND SUMMARY.node_type IN (1, 2, 3)
GROUP BY
SUMMARY.parent_hash_id,company_id
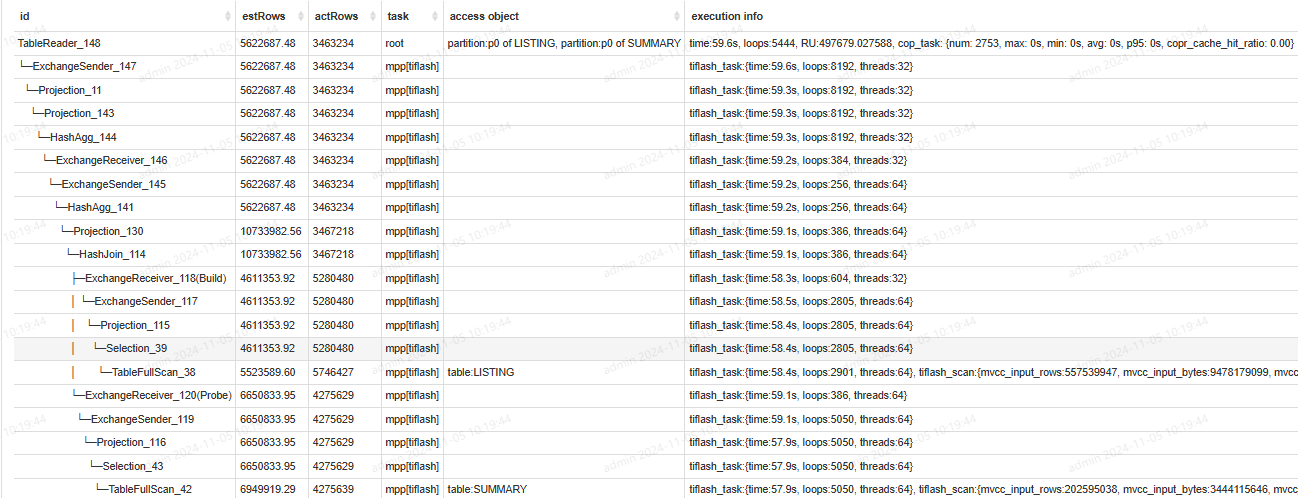
demo: select * from a inner join b on a.userId = b.userId where userId='xxxx' and 其他 order by id ; 其中表a数据量1亿,表b数据量6亿,分区键用userId,分64个分区,耗时2秒;但是表a数据达到2亿时,该语句耗时变成30秒;
将分区键userId 改成id,是否有效果