【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.0
【遇到的问题:问题现象及影响】
我们Tidb生产集群规模较大,在线滚动升级时,总是会超时,启停一次集群需要大概6小时左右,不想停集群升级,是不是可以将一个节点停掉,升级后再拉起来
5台tidb+pd服务器,tidb和pd混合部署,3台为256g内存,2台512g内存混合部署了两个cdc,9台tikv服务器全部512g内存,挂了3块2T SSD ,每台部署3个tikv节点,这样部署是否合理,有没有更优化的部署方案
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
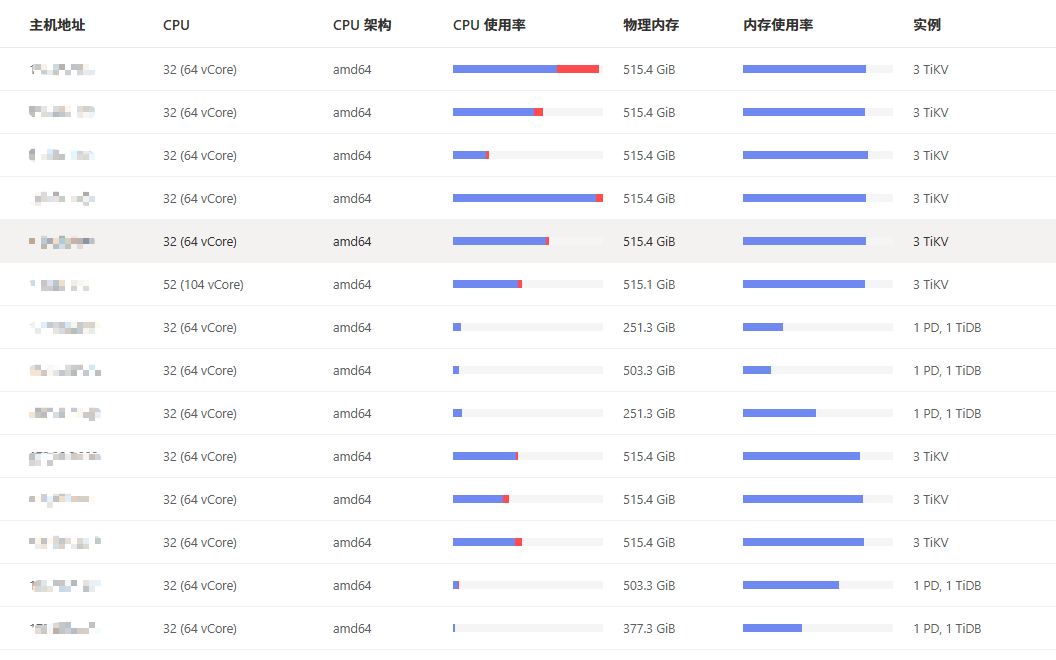
应该还好吧,我们2套集群跟你配置差不多,一套直接在线滚动升级,一套挺集群备份还原升级,没有遇到超时的问题,具体日志啥的有么,发来让大佬们诊断一下
–transfer-timeout=15 加一个这个参数可以加快升级速度,业务会有抖动
这个参数可以加快升级速度嘛,我去查一下,不过他都在线升级了,肯定会通知相关业务方,有抖动应该也在可接受范围内
强制切leader的,可以加快很多。不用等都迁移完。有说明的,默认比较长
tiup cluster upgrade --help
–transfer-timeout uint Timeout in seconds when transferring PD and TiKV store leaders, also for TiCDC drain one capture (default 600)
我们还得评估下,记得第一次升级时加过这个,还是有重启失败的,最后是加的 --force 忽略错误强制重启成功的
重启失败就调大一点,是不是pd那里卡住了?
结果第一列为 audit-id
tiup cluster audit |tail -10
继续执行指定的命令
tiup cluster replay
升级中,如果升级到一半失败,可以用这个方式继续执行,避免重复操作。
重启一次五六个小时?要这么久吗,,
忽略错误,强制重启,对数据有没有影响啊