【 TiDB 使用环境】生产环境
【 TiDB 版本】 5.2.2
目前 5.2.2版本的集群两个server节点,没有做高可用,所以生产业务其实只配置连接到起作用个 192.168.1.32的节点,另外一个节点业务不适用,凌晨会有大数据过来查询一些数据。
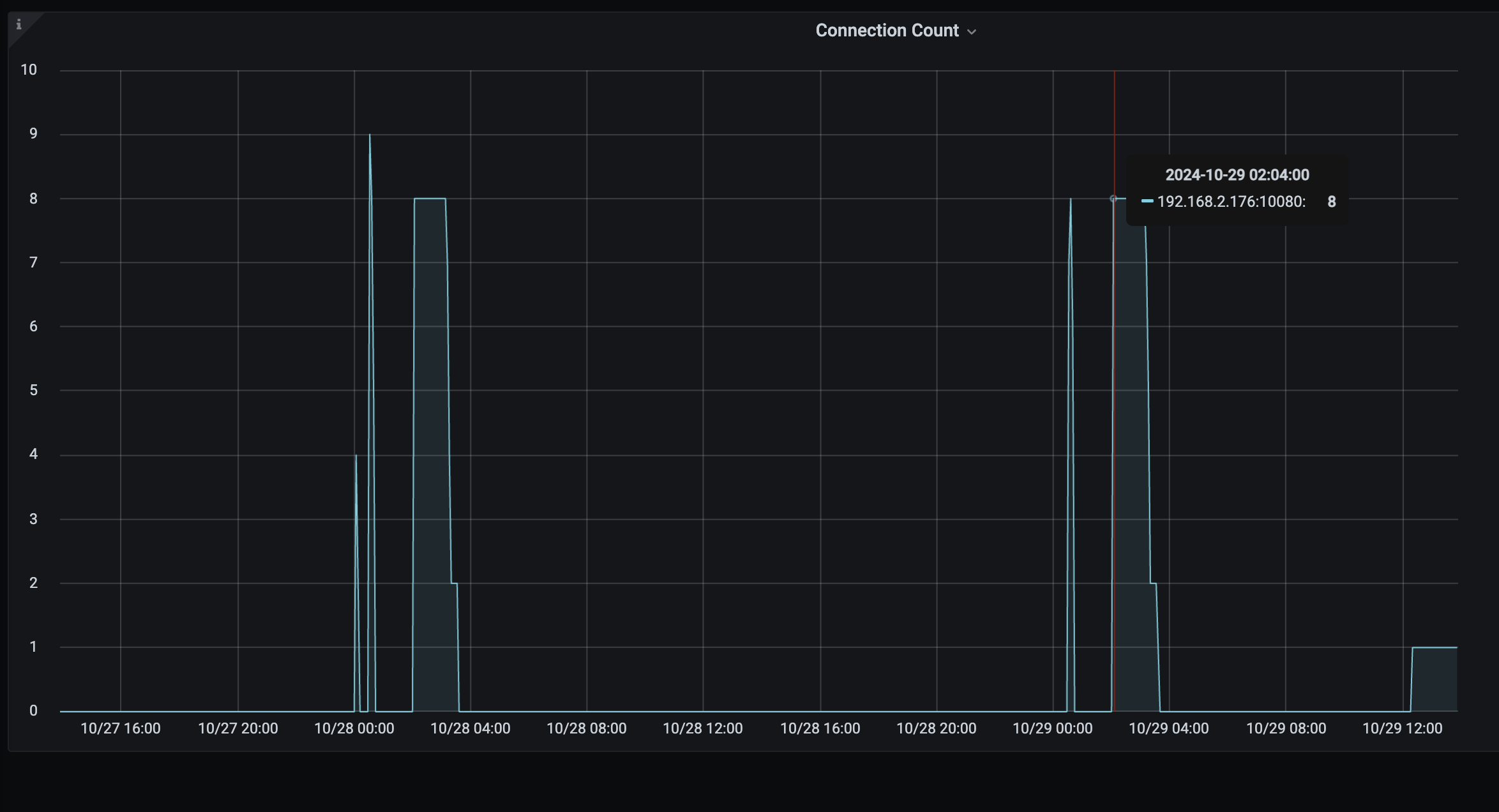
但是从监控发现 另外一个业务未使用的节点(192.168.2.176), 在每天凌晨2点到5点之间,存在连接数增长和内存的急剧增大。
连接数监控
内存监控
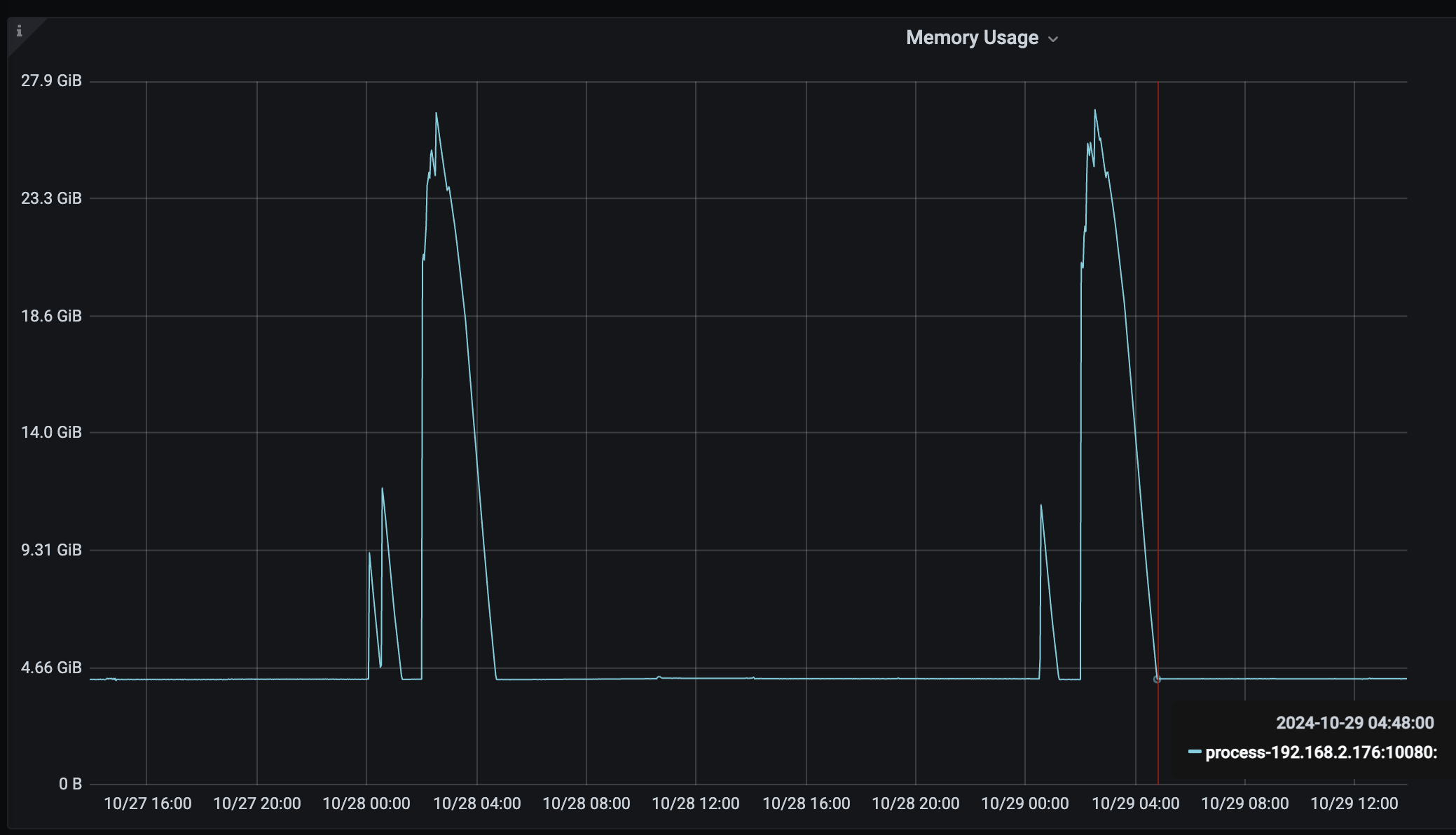
其中前面的小波峰是大数据查询数据导致。
通过自动脚本监控2点到5点之间的连接情况,发现期间存在大量的 127.0.0.1 发起的(也即是192.168.2.176)的全表查询
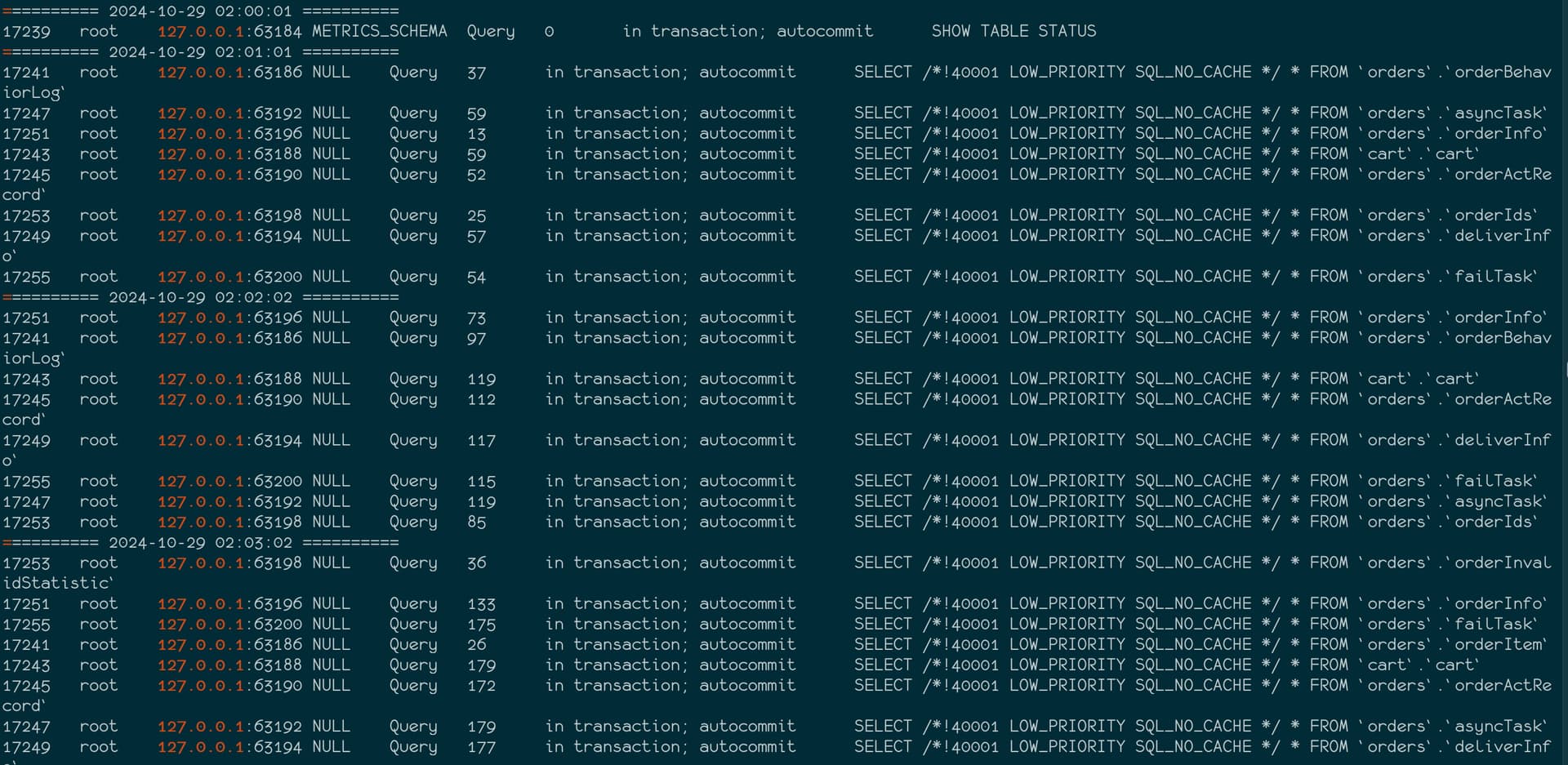
统计分析之后发现,这里的出现的表,并不是对应库下的所有表 ,
auto analyze 发生在 1.32节点上,并不在该节点上。 (通过show analyze status 来判断)
有人知道这是什么逻辑触发的?