【 TiDB 使用环境】生产环境
【 TiDB 版本】7.5.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
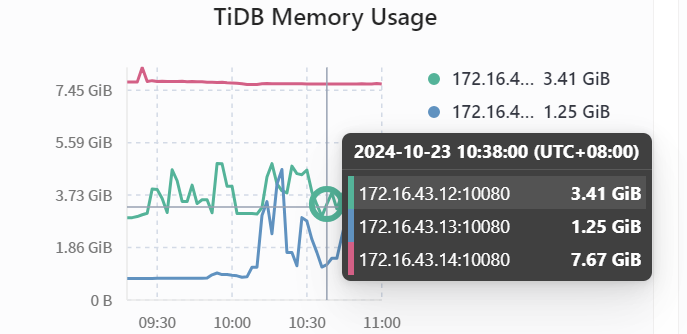
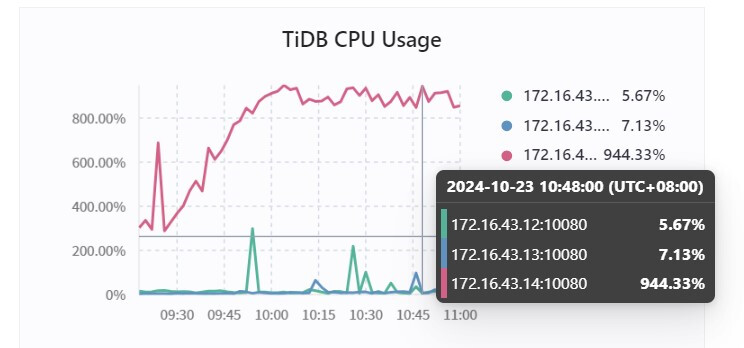
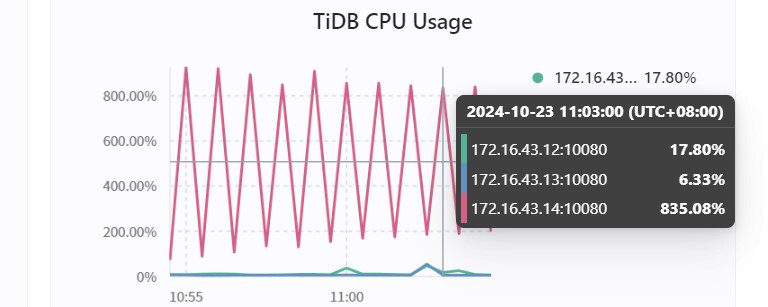
三个节点的集群,32G内存,采用混部的方式部署,三个tidb实例中其中一个实例CPU每分钟周期性的使用率增加,后面定位到是该实例内存超过了tidb_server_memory_limit * tidb_server_memory_limit_gc_trigger 从而触发gc动作导致CPU增加。目前已经避免将SQL请求转发到该tidb实例,但是该实例还是每分钟触发gc,导致cpu增大。虽然可以通过调整tidb_server_memory_limit_gc_trigger 以及tidb_server_memory_limit 来避免GC,但是一旦后续SQL请求转发到节点,还是会导致该节点内存使用超过tidb_server_memory_limit * tidb_server_memory_limit_gc_trigger ,进而继续触发gc。
疑问:1.tidb实例内存gc不会释放内存使用率吗,为何即使没有SQL请求了,还会不断触发内存gc。
2.即使调整参数或者增加内存,但是访问量增加还是会导致触发gc,导致cpu负载增加,有没有其他什么方式避免频繁内存gc。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
Saved profile in /root/pprof/pprof.tidb-server.samples.cpu.004.pb.gz
File: tidb-server
Build ID: 06544e279eb4143741ccbe837cfc00f33a0f042d
Type: cpu
Time: Oct 23, 2024 at 10:57am (CST)
Duration: 9.07s, Total samples = 24.86s (274.13%)
Entering interactive mode (type “help” for commands, “o” for options)
(pprof) top30
Showing nodes accounting for 23.19s, 93.28% of 24.86s total
Dropped 363 nodes (cum <= 0.12s)
Showing top 30 nodes out of 109
flat flat% sum% cum cum%
4.14s 16.65% 16.65% 4.41s 17.74% runtime.findObject
4.08s 16.41% 33.07% 12.78s 51.41% runtime.scanobject
1.68s 6.76% 39.82% 1.76s 7.08% runtime.(*gcBits).bitp (inline)