【 TiDB 使用环境】生产环境
【 TiDB 版本】TiDB v6.5.0, TiDB-Operator v1.4.4
【复现路径】无
【遇到的问题:问题现象及影响】
TiDB和PD节点有时会重启,查看日志后发现是被信号kill掉了,但没有任何的升级等操作
TiDB当时的日志
[2024/10/22 08:55:23.090 +00:00] [Info] [2pc.go:1162] ["send TxnHeartBeat"] [startTS=453400928726810830] [newTTL=60000]
[2024/10/22 08:55:33.090 +00:00] [Info] [2pc.go:1162] ["send TxnHeartBeat"] [startTS=453400928726810830] [newTTL=70000]
[2024/10/22 08:55:43.090 +00:00] [Info] [2pc.go:1162] ["send TxnHeartBeat"] [startTS=453400928726810830] [newTTL=80000]
[2024/10/22 08:55:44.266 +00:00] [Warn] [pd.go:152] ["get timestamp too slow"] ["cost time"=42.060439ms]
[2024/10/22 08:55:44.818 +00:00] [Info] [signal_posix.go:54] ["got signal to exit"] [signal=terminated]
[2024/10/22 08:55:44.819 +00:00] [Info] [server.go:488] ["setting tidb-server to report unhealthy (shutting-down)"]
[2024/10/22 08:55:44.819 +00:00] [Error] [http_status.go:504] ["start status/rpc server error"] [error="accept tcp [::]:10080: use of closed network connection"]
[2024/10/22 08:55:44.819 +00:00] [Error] [http_status.go:499] ["http server error"] [error="http: Server closed"]
[2024/10/22 08:55:44.819 +00:00] [Error] [http_status.go:494] ["grpc server error"] [error="mux: server closed"]
[2024/10/22 08:55:44.821 +00:00] [Info] [manager.go:247] ["failed to campaign"] ["owner info"="[autoid] tidb/autoid/leader ownerManager kube-tidb-tidb-2.kube-tidb-tidb-peer.tidb-prod-02.svc:10080"] [error="context canceled"]
[2024/10/22 08:55:44.821 +00:00] [Info] [manager.go:228] ["break campaign loop, context is done"] ["owner info"="[autoid] tidb/autoid/leader ownerManager kube-tidb-tidb-2.kube-tidb-tidb-peer.tidb-prod-02.svc:10080"]
[2024/10/22 08:55:44.826 +00:00] [Info] [manager.go:272] ["revoke session"] ["owner info"="[autoid] tidb/autoid/leader ownerManager kube-tidb-tidb-2.kube-tidb-tidb-peer.tidb-prod-02.svc:10080"] []
[2024/10/22 08:55:44.826 +00:00] [Info] [server.go:835] ["[server] graceful shutdown."]
[2024/10/22 08:55:44.869 +00:00] [Info] [server.go:848] ["graceful shutdown..."] ["conn count"=5]
[2024/10/22 08:55:46.940 +00:00] [Warn] [expensivequery.go:118] [expensive_query] [cost_time=360.526526022s] [cop_time=0.189881635s] [process_time=281.75s] [wait_time=3.132s] [request_count=7793] [total_keys=98654307] [process_keys=82161781] [num_cop_tasks=7793] [process_avg_time=0.03615424s] [process_p90_time=0.107s] [process_max_time=0.71s] [process_max_addr=kube-tidb-tikv-8.kube-tidb-tikv-peer.tidb-prod-02.svc:20160] [wait_avg_time=0.000401899s] [wait_p90_time=0s] [wait_max_time=0.381s] [wait_max_addr=kube-tidb-tikv-6.kube-tidb-tikv-peer.tidb-prod-02.svc:20160] [stats=subscription_analytics:453376524418023627,madhu_subscription_analytics_backup:453400848825319460] [conn_id=3983286535852908027] [user=partner] [database=partnerhubanalytics] [table_ids="[55850,44720]"] [txn_start_ts=453400850961793036] [mem_max="10785834790 Bytes (10.0 GB)"] [sql="/* ApplicationName=DBeaver 24.2.2 - SQLEditor <Script.sql> */ SELECT\n\t*\nfrom\n\tmadhu_subscription_analytics_backup msab\nEXCEPT\nSELECT\n\t*\nfrom\n\tsubscription_analytics"]
[2024/10/22 08:55:53.090 +00:00] [Info] [2pc.go:1162] ["send TxnHeartBeat"] [startTS=453400928726810830] [newTTL=90000]
[2024/10/22 08:56:03.090 +00:00] [Info] [2pc.go:1162] ["send TxnHeartBeat"] [startTS=453400928726810830] [newTTL=100000]
[2024/10/22 08:56:04.966 +00:00] [Warn] [pd.go:152] ["get timestamp too slow"] ["cost time"=77.959157ms]
[2024/10/22 08:56:05.066 +00:00] [Warn] [pd.go:152] ["get timestamp too slow"] ["cost time"=81.493909ms]
[2024/10/22 08:56:13.091 +00:00] [Info] [2pc.go:1162] ["send TxnHeartBeat"] [startTS=453400928726810830] [newTTL=110000]
[2024/10/22 09:02:52.851 +00:00] [Info] [cpuprofile.go:113] ["parallel cpu profiler started"]
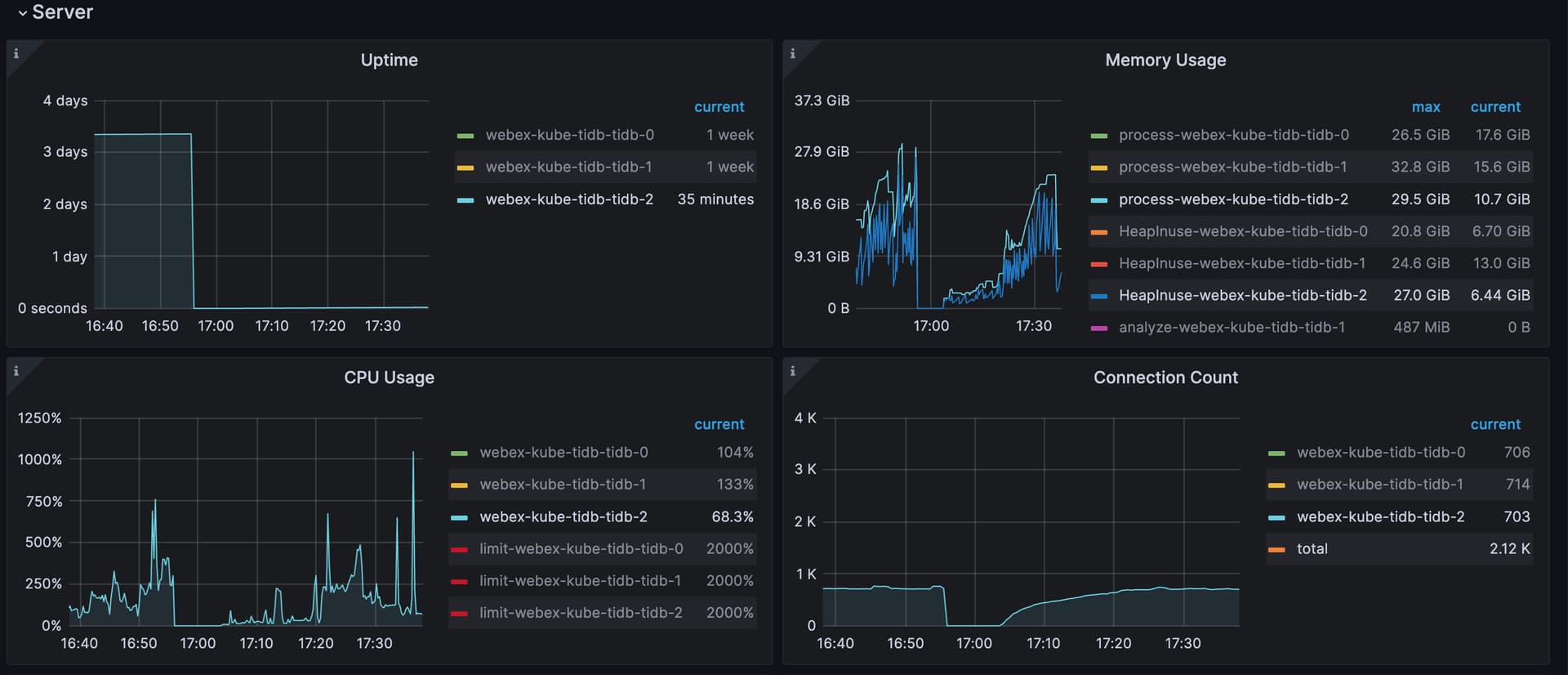
当时的CPU和内存监控
【资源配置】
TiDB的节点配置是
requests:
cpu: 16
memory: 96Gi
limits:
cpu: 20
memory: 104Gi
看起来并不像OOM或者崩溃,而是Operator错误的杀死了正常运行的Pod
补充
有一个类似的问题是Discovery不断重启(https://asktug.com/t/topic/1026104)
看到后面排查人员说是K8s内部署多个TiDB集群导致的,我这边的K8S环境中确实有多套集群,但我的discovery一直是正常的