【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
有一个v4.0.8 的集群打算升级,在做 tiup cluster check xxx --cluster 预检查时,发现有5个 pending-peer ,这个应该如何处理
有副本的raft log有延迟吧,等几分钟再检查下呢
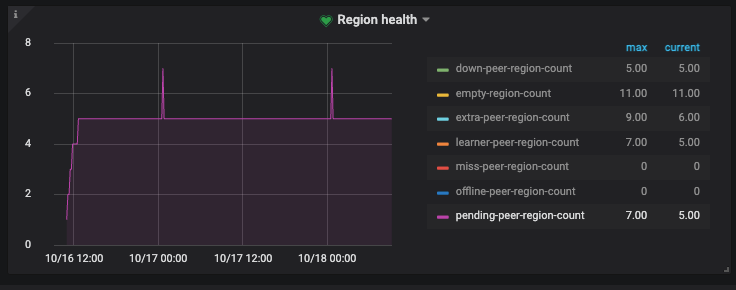
可以观察一下grafana中pd-region health里面的pending-peer-region-count,降为0就是正常了。
Pending 表示 Follower 或 Learner 的 raft log 与 Leader 有较大差距,Pending 状态的 Follower 无法被选举成 Leader。
![]() 我觉得没有减少是因为那5个都down了。
我觉得没有减少是因为那5个都down了。
看过这个监控了,这个 pend 的 region 有什么处理方法吗
是不是tiflash的问题?有tiflash么?
这个集群没有 tiflash
![]() learner-peer-region-count就是tiflash的。是以前有过,然后缩容了么?
learner-peer-region-count就是tiflash的。是以前有过,然后缩容了么?
这个倒不清楚,也是接手前任大哥留下的集群。
执行这个看看有没有tiflash副本?
SELECT * FROM information_schema.tiflash_replica
另外display一下集群,看看集群状态和组件
现在通过 pd-ctl 找到了 pend 的region id ,从状态看是 down 状态的,我想直接 remove 掉 ,在用
tiup ctl:v4.0.8 pd -u xxx:yyy operator add remove-peer 136571147 130872539
的时候,提示 Failed! [500] “region 136571147 not found”
感觉是之前强制下线遗留的问题。
解决了-,-其实就是上面的 remove-peer ,开始看错了,把 peer id 当成 region id 传进去了,所以一直在报错
![]()
![]()
![]() 为你点赞,能接盘的都是大难
为你点赞,能接盘的都是大难
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。