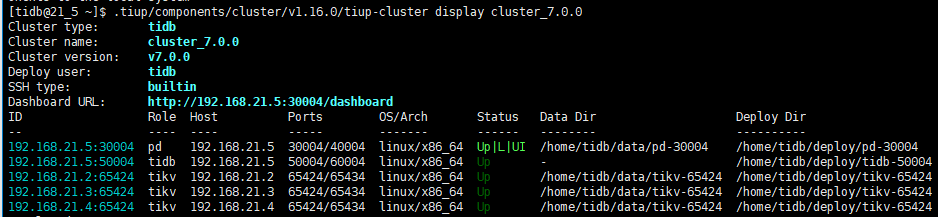
【 TiDB 使用环境】测试
【 TiDB 版本】v7.0.0
【复现路径】做过哪些操作出现的问题
全量备份完成后,开始运行日志备份任务(为防止日志备份因为gc的原因失败,事先将tidb_gc_run_interval设置为了240h),然后停掉日志备份任务,drop掉除系统库以外的所有数据库,将tidb_gc_run_interval再设置为10m,gc一直未正常运行(tikv的数据目录一直未减小)。
【遇到的问题:问题现象及影响】
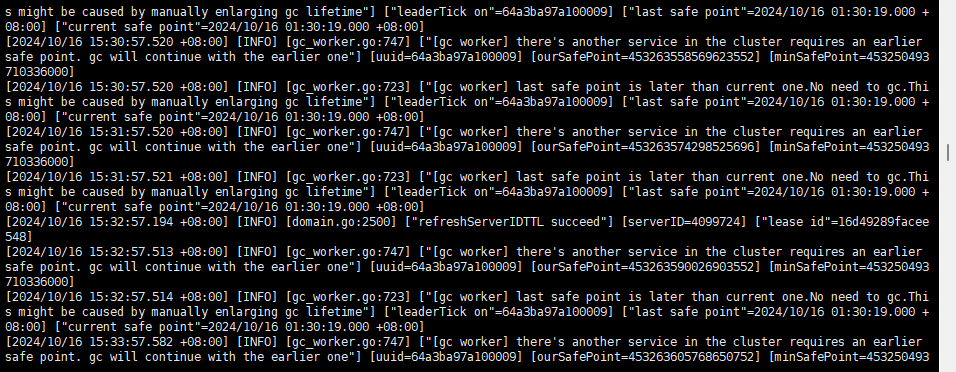
查看tidb-server日志发现两条gc相关日志:
1.there’s another service in the cluster requires an earlier safe point. gc will continue with the earlier one.
2.last safe point is later than current one.No need to gc.This might be caused by manually enlarging gc lifetime"] [“leaderTick on”=64a3ba97a100009] [“last safe point”=2024/10/16 01:30:19.000 +08:00] [“current safe point”=2024/10/16 01:30:19.000 +08:00]
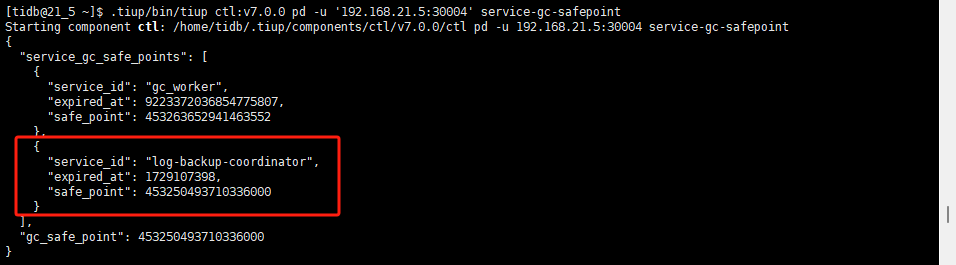
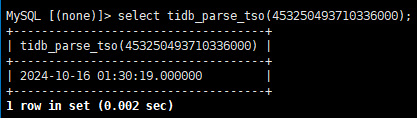
因为log-backup-coordinator的safe_point转换以后即为2024-10-16 01:30:19.000000,所以我推测是因为这个log-backup-coordinator导致了gc运行失败。
学习了, there’s another service in the cluster requires an earlier safe point. gc will continue with the earlier one. 这条日志表明集群中存在另一个服务需要一个更早的safe point,因此GC会使用这个更早的safe point继续进行,如果其他服务(如TiCDC)需要一个更早的safe point,GC将不能删除这些旧数据,以确保这些服务能够正确地读取数据