【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.9
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
收到prometheus的tikv的TiDB_tikvclient_backoff_seconds_count告警,tidb在10分钟之内访问tikv发生错误时发起重试的次数超过10次,tikv的日志告警信息如下所示,这个问题要如何定位?通过tiup cluster display 集群名字看都是up:
[2024/10/12 16:53:16.817 +08:00] [WARN] [endpoint.rs:782] [error-response] [err=“Region error (will back off and retry) message: "EpochNotMatch current epoch of region 7929 is conf_ver: 5 version: 680, but you sent conf_ver: 5 version: 679" epoch_not_match { current_regions { id: 7929 start_key: 7480000000000007FF2900000000000000F8 region_epoch { conf_ver: 5 version: 680 } peers { id: 7930 store_id: 1 } peers { id: 7931 store_id: 4 } peers { id: 7932 store_id: 5 } } current_regions { id: 8245 start_key: 7480000000000007FF2700000000000000F8 end_key: 7480000000000007FF2900000000000000F8 region_epoch { conf_ver: 5 version: 680 } peers { id: 8246 store_id: 1 } peers { id: 8247 store_id: 4 } peers { id: 8248 store_id: 5 } } }”]
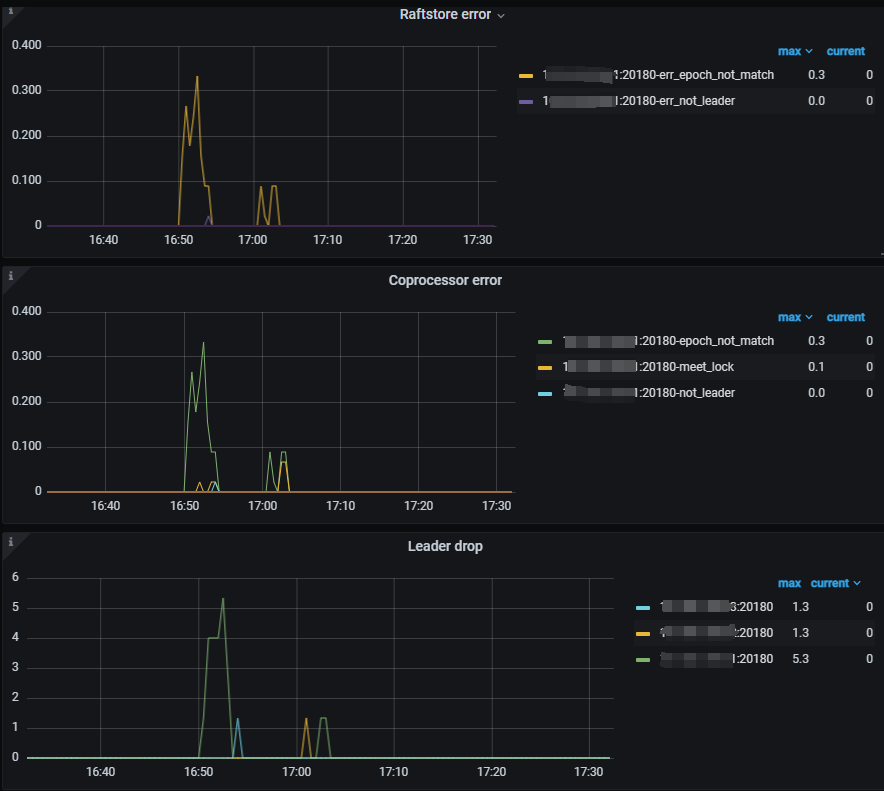
没啥影响,官方给的告警阈值太低了,你改大些或者关闭都行
1 个赞
你好,这个是什么原因导致的?


TiDB Backoff type 主要原因?
TiDB-server 与 TiKV-server 随时进行通信,在进行大量数据操作过程中,会出现 Server is busy 或者 backoff.maxsleep 20000ms 的日志提示信息,这是由于 TiKV-server 在处理过程中系统比较忙而出现的提示信息,通常这时候可以通过系统资源监控到 TiKV 主机系统资源使用率比较高的情况出现。如果这种情况出现,可以根据资源使用情况进行相应的扩容操作。
pd有产生了调度,是不是有些dml操作呢
还有没有类似一些这样的告警的阈值默认是比较小的,现在使用的告警阈值是来自官方文档中的
看实际需求吧,主要看目前有哪些不需要关注的告警频繁。像backoff这个我们阈值调整成1000,还有node_disk_write_time_seconds_total这个我们调整成只对nvme盘生效了。
可以看tidb的slow log,找到backoff次数比较多的sql。然后通过该sql分析具体原因,比如热点?高并发?还是什么,再具体去解决该问题
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。