【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.5.0
【复现路径】做过哪些操作出现的问题
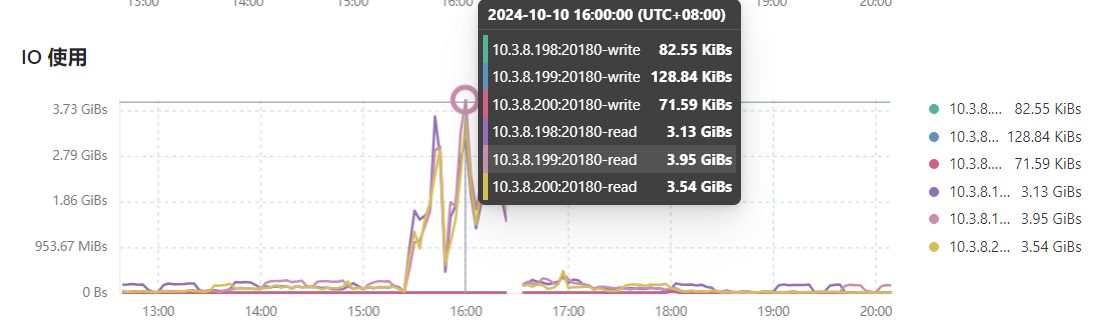
【遇到的问题:问题现象及影响】tidb集群存在热点读问题,tikv的3个节点在某个时间段内读流量高达3Gb问题,导致整个集群的性能变慢
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
和region相关的几个配置参数如下:
tikv:
coprocessor.region-max-size: 384MB
coprocessor.region-split-size: 256MB
raftstore.region-split-check-diff: 196MB
+-----------+----------------------------------+-----------+------------------+------------------+-----------+------------------+
| 数据库 | 表名 | 记录数 | 数据容量(GB) | 索引容量(GB) | total(GB) | 碎片占用(MB) |
+-----------+----------------------------------+-----------+------------------+------------------+-----------+------------------+
| maindb | es_charge_settle_accounts_detail | 8303620 | 3.51 | 1.46 | 4.97 | 0.00 |
+-----------+----------------------------------+-----------+------------------+------------------+-----------+------------------+
1 row in set (0.25 sec)
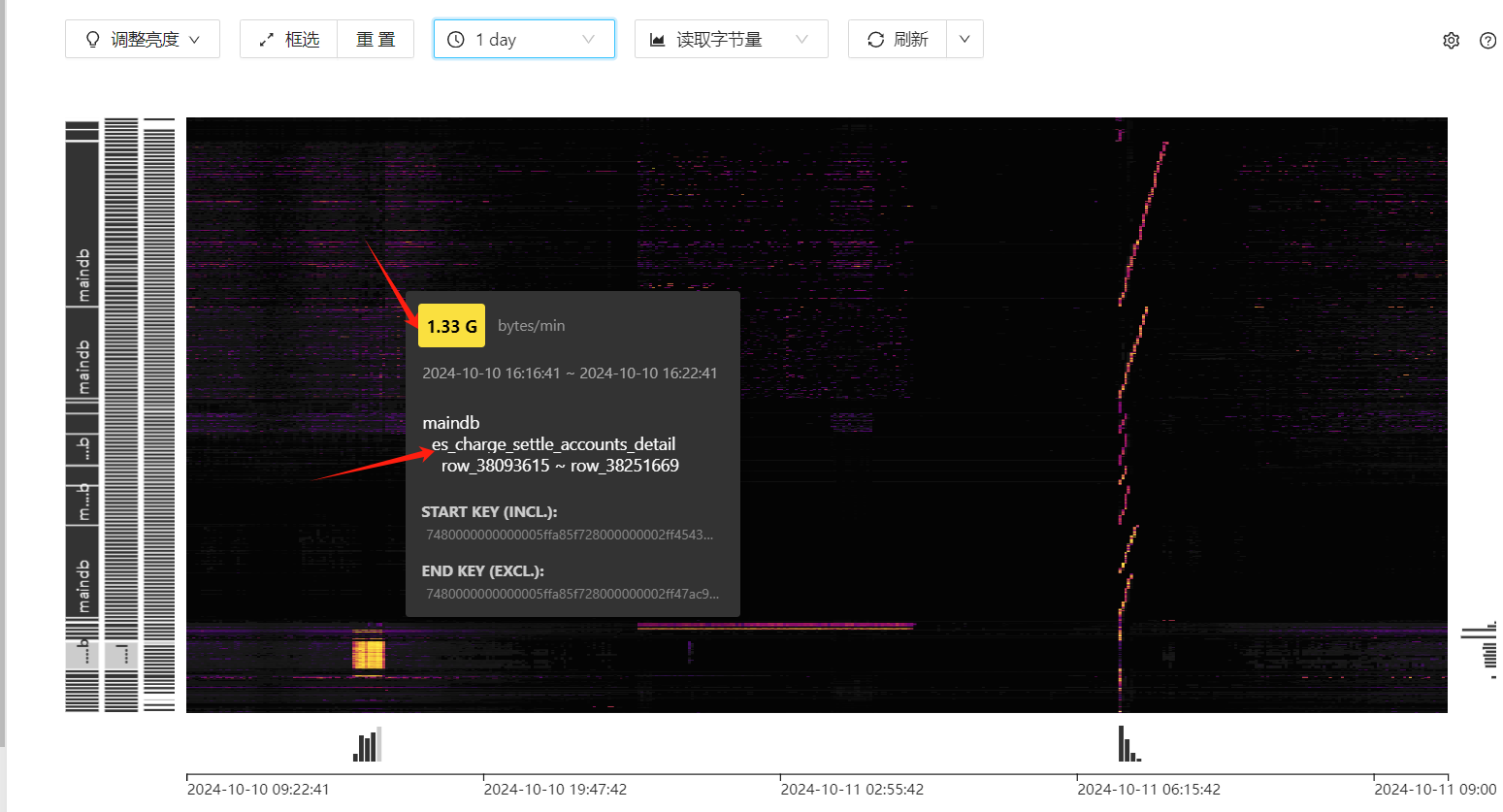
表的记录数和占用空间大小情况
应该让表妹给宣传下,看看有没有大佬能解决
已经告知表妹了,哈哈
一共几个kv节点??
3个kv节点。
那你这个不是热点读写,是这个detail表有大规模的读写压崩了数据库,得优化sql
dashboard慢查询页面看下这个表的对应sql及执行计划,是不是全表扫了。
你就3个tikv,那就没啥热点,3个看起来都高,找慢查询看看sql为啥取那么多数据
1、前几个月的时候,也出现过类似的情况。当时,是因为某张业务表的健康度过低。做了analyze收集后,就解决了。
2、后来,我们专门对业务表,进行了一个定时自动进行低健康度的表信息收集。
3、这次的问题现象虽然和上次很像,但是,这次的表的健康度为100%。
4、目前,查看到的象是产生了热点读,但是,这张表只有800w数据。
看下你的这个表的慢sql呢,是不是执行计划走偏了
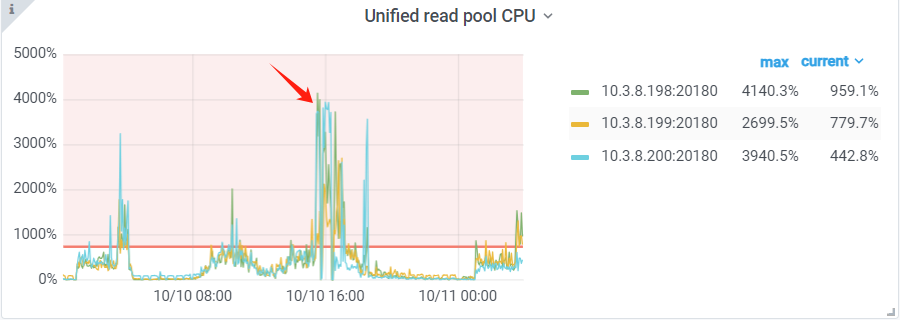
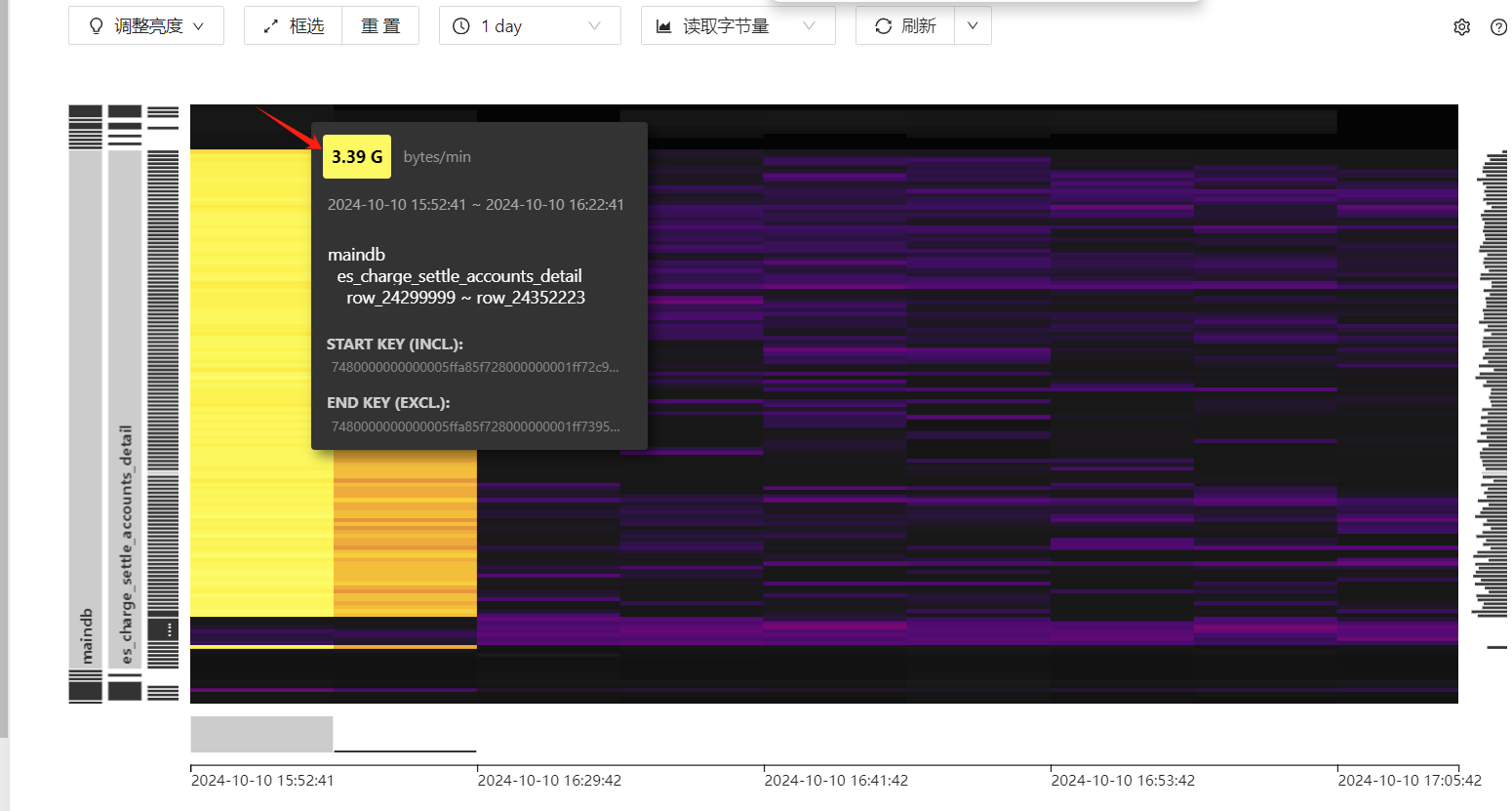


这个图看上去确实像是读热点。
不过大表读热点确实可用的手段比较少。
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#打散读热点
使用副本读是一种方式。不过看介绍这个需要7.1.
还有就是通过top sql看看这台tikv上当时运行的sql是什么。如果是和聚合计算相关的sql,考虑使用tiflash。比使用tikv硬算要快很多。
这种热点主要是异常SQL导致的,建议先看下慢日志
问题挺复杂,学习了。