【 TiDB 使用环境】 测试
【 TiDB 版本】v7.5.3
【复现路径】tidb集群日常的监控报警是如何配置的呢?
系统层:
cpu利用率, mem利用率, net带宽,磁盘利用率,服务器存活
实例层:
tidb进程【端口存活】,读写qps,thread连接数等
pd进程【端口存活】
tikv进程【端口存活】
对这些的监控报警大家都是如何托管的呢
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
xfworld
(魔幻之翼)
2
托管是个什么概念?
告警一般采用默认配置就可以了,如果环境中有一些状态就需要手工调整阈值,或者频率了
是的,假如配置的报警达到某个阈值后会通过短信方式发出来
这里介绍不了我
(持续学习)
13
定时去查Prometheus的api 再根据设定的阈值去决定是否告警
郑旭东石家庄
(Ti D Ber Xh Hfy Sc H)
14
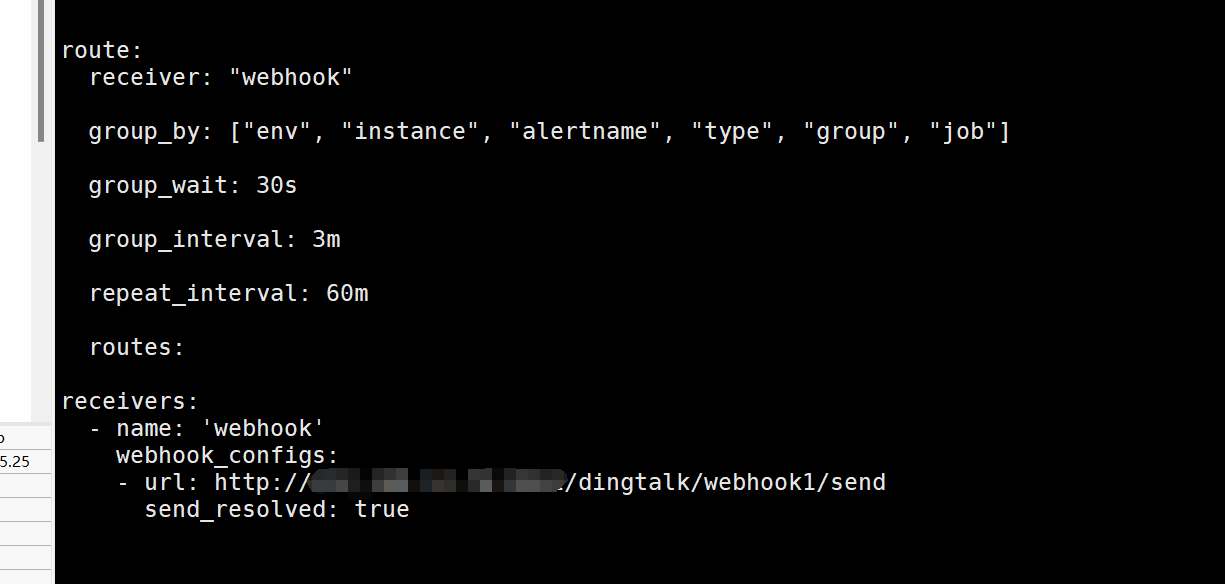
可以设置钉钉报警使用webhook,在alertmanager.yml配置文件中设置,参考下面内容
system
(system)
关闭
16
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。