Data for AI Meetup 回顾

9月21日,一场专注于人工智能与数据的盛会——Data for AI Meetup在北京中关村圆满举行。这次活动由 Datastrato 主办,小米集团、LF AI & DATA以及北京智源人工智能研究院协办。会议荣幸地邀请到了来自腾讯云、Intel、Zilliz、PingCAP、Jina AI、JuiceData、蚂蚁集团和亚马逊云科技等顶尖企业的杰出代表和技术领袖,共同分享和探讨了他们在数据与AI领域的洞见和经验。
在此次 Meetup 上,PingCAP 副总裁刘松分享了题为《TiDB 面向 AI 和云的技术创新》的演讲,和现场的小伙伴一起探讨了生成式人工智能(Gen AI)如何塑造新的应用生态和软件行业趋势。下面就让我们一起来回顾精彩的分享吧!
资料下载
TiDB 面向 AI 和云的技术创新.pdf (3.6 MB)
 分享嘉宾
分享嘉宾

PingCAP 副总裁刘松
 分享内容
分享内容
Gen AI 发展概况:介绍了生成式人工智能(Gen AI)的发展历程,从2010年代的初期模型如AlphaGo、Transformer,到GPT-3.5、GPT-4/5的演变

Gen AI 对行业的影响:包括对数字化转型企业、泛金融产业、消费类行业、知识密集型行业、云计算和企业软件的影响。
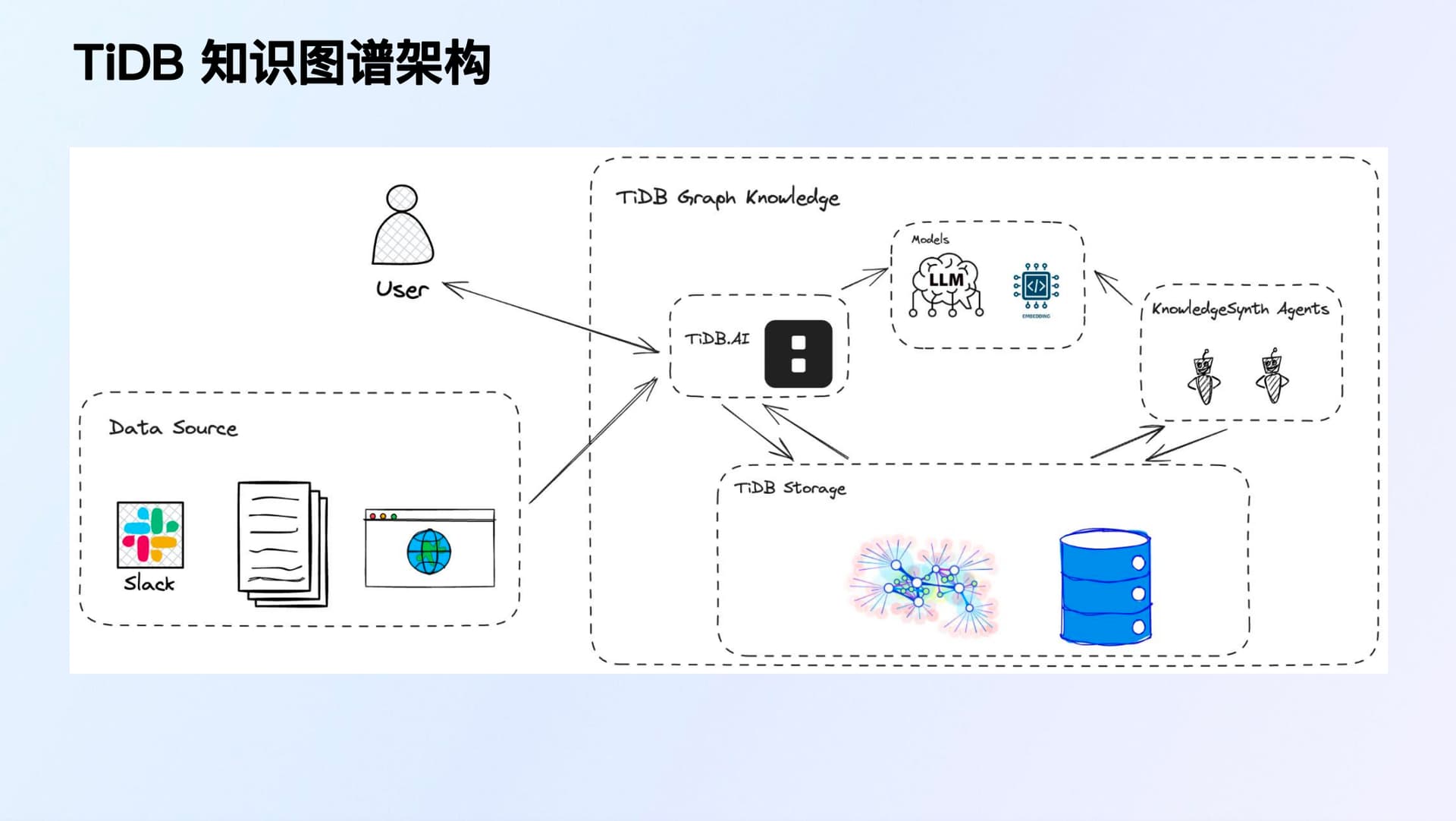
TiDB 知识图谱 架构:展示了TiDB知识图谱的架构,包括用户、数据源、存储和索引任务。

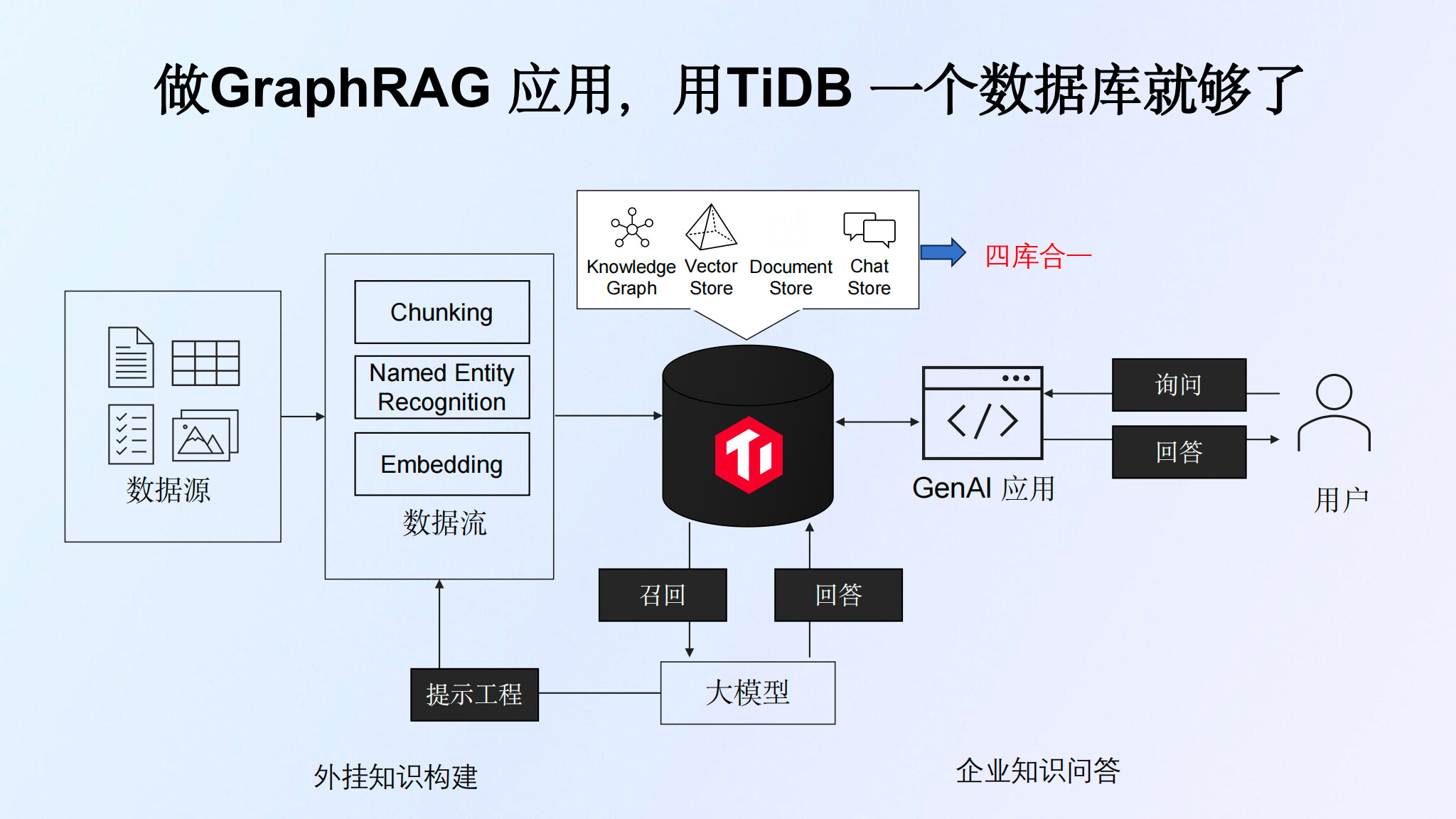
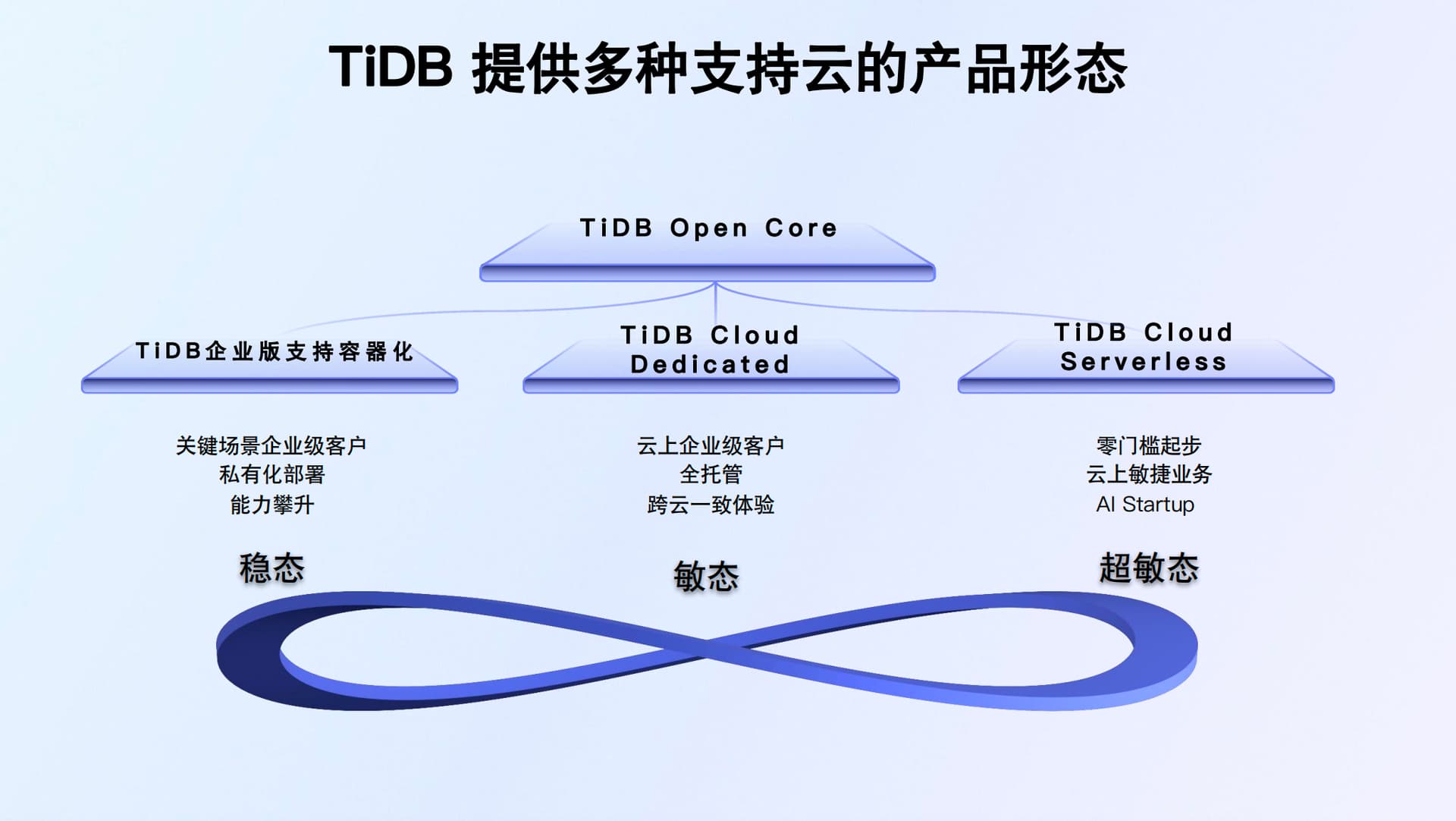
TiDB的产品形态:介绍了TiDB提供的不同云支持产品形态,包括TiDB Open Core、TiDB Cloud、TiDB Cloud Dedicated和TiDB Cloud Serverless。

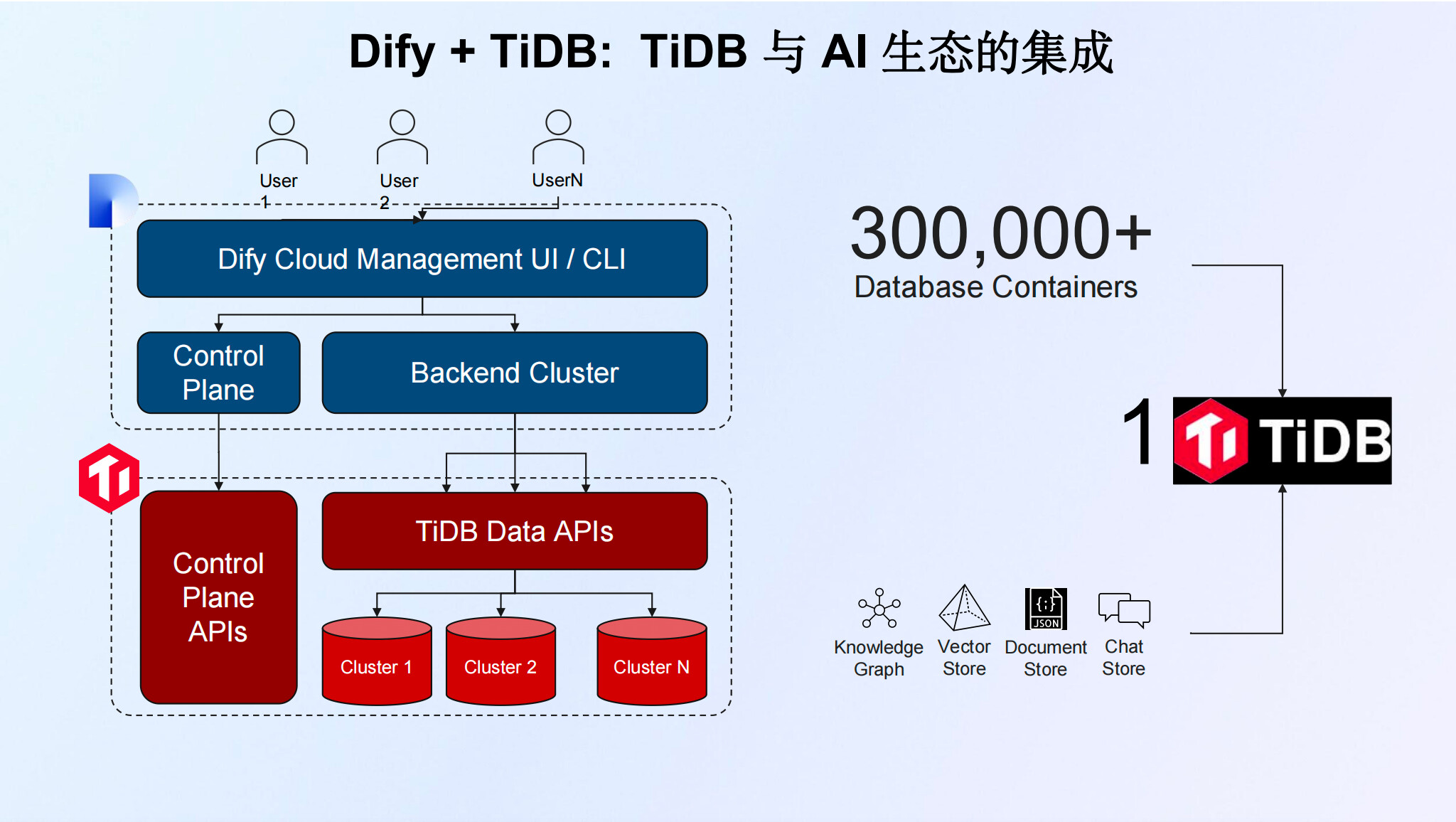
TiDB与 AI 生态的集成:展示了TiDB如何与AI生态系统集成,包括Dify Cloud Management、Database Containers、Control Plane、TiDB、Data APIs和Knowledge Vector Document等组件。
2024 CSDI Summit 回顾
9 月 20 日至 22 日,中国软件研发创新科技峰会( 2024 CSDI Summit)隆重召开,这是一场由国内顶尖咨询公司百林哲精心策划的行业领先会议。峰会汇集了来自国内外杰出软件和互联网公司的研发精英,共同探讨了包括人工智能、大数据、行业动向、技术进步、生态系统扩展、业务创新以及新商业模式在内的多个软件研发的核心议题。
在 9 月 22 日「大模型与数据库」的实践专场中,TiDB 开发者生态高级工程师王琦智,对下一代RAG技术进行了深入的介绍,包括它的理论基础、实际应用、以及如何通过知识图谱和TiDB Serverless来提升RAG的性能和效果,一起来看看吧!
资料下载
下一代 RAG - TiDB 社区 - 王琦智.pdf (76.5 MB)
分享嘉宾

王琦智|TiDB 开发者生态高级工程师,7 年编程与架构经验
分享内容
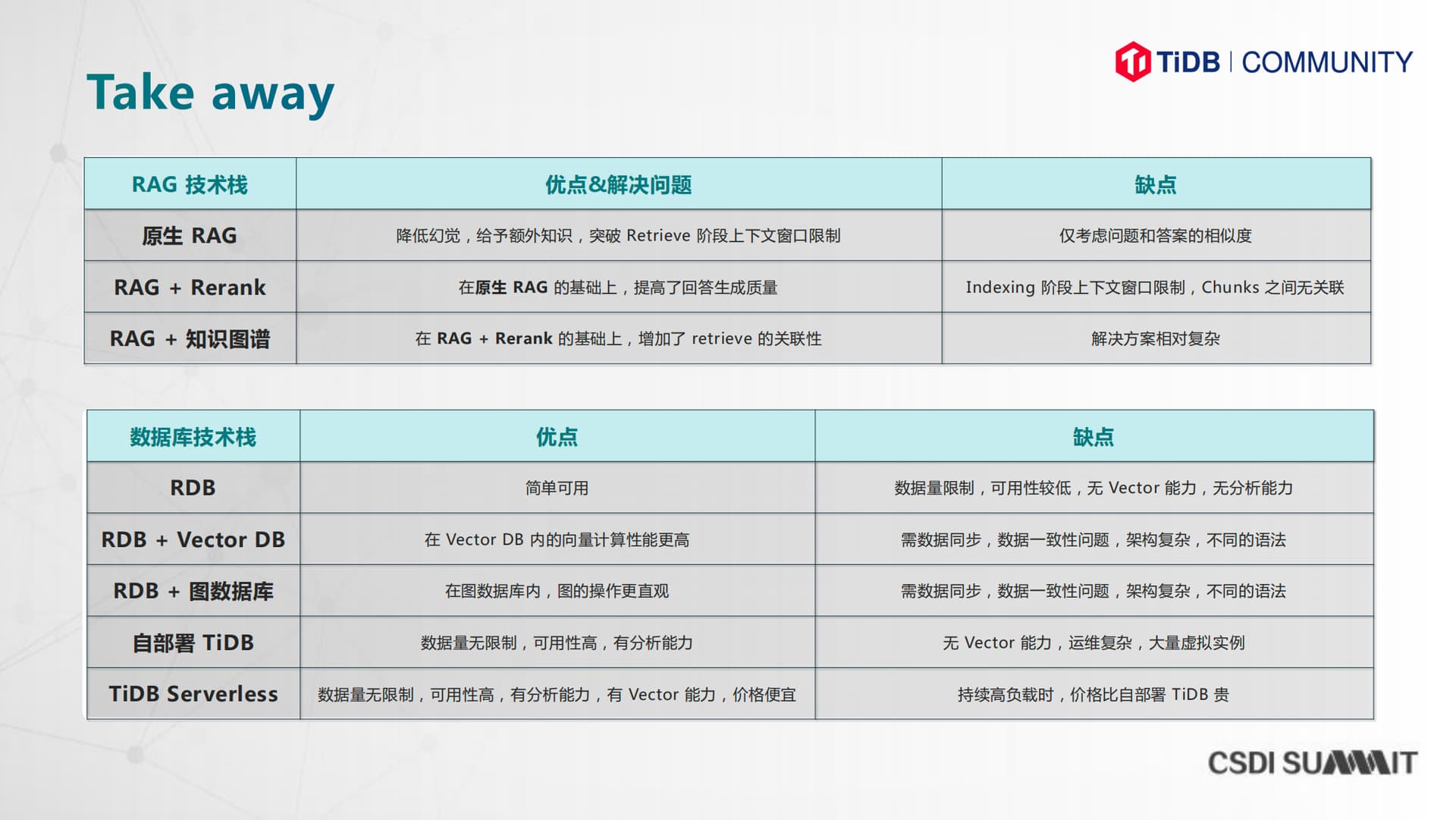
RAG技术介绍:介绍了RAG(Retrieval-Augmented Generation,检索增强生成)的基本概念,以及它如何解决上下文窗口限制、降低幻觉和提供额外知识的问题。


为什么需要Rerank:讨论了Rerank(重新排序)的重要性,以及它如何通过考虑查询和文档之间的深层交互来提高搜索结果的相关性。

知识图谱 助力RAG:介绍了知识图谱如何增强RAG能力,包括理论基础、简易架构和实际操作。
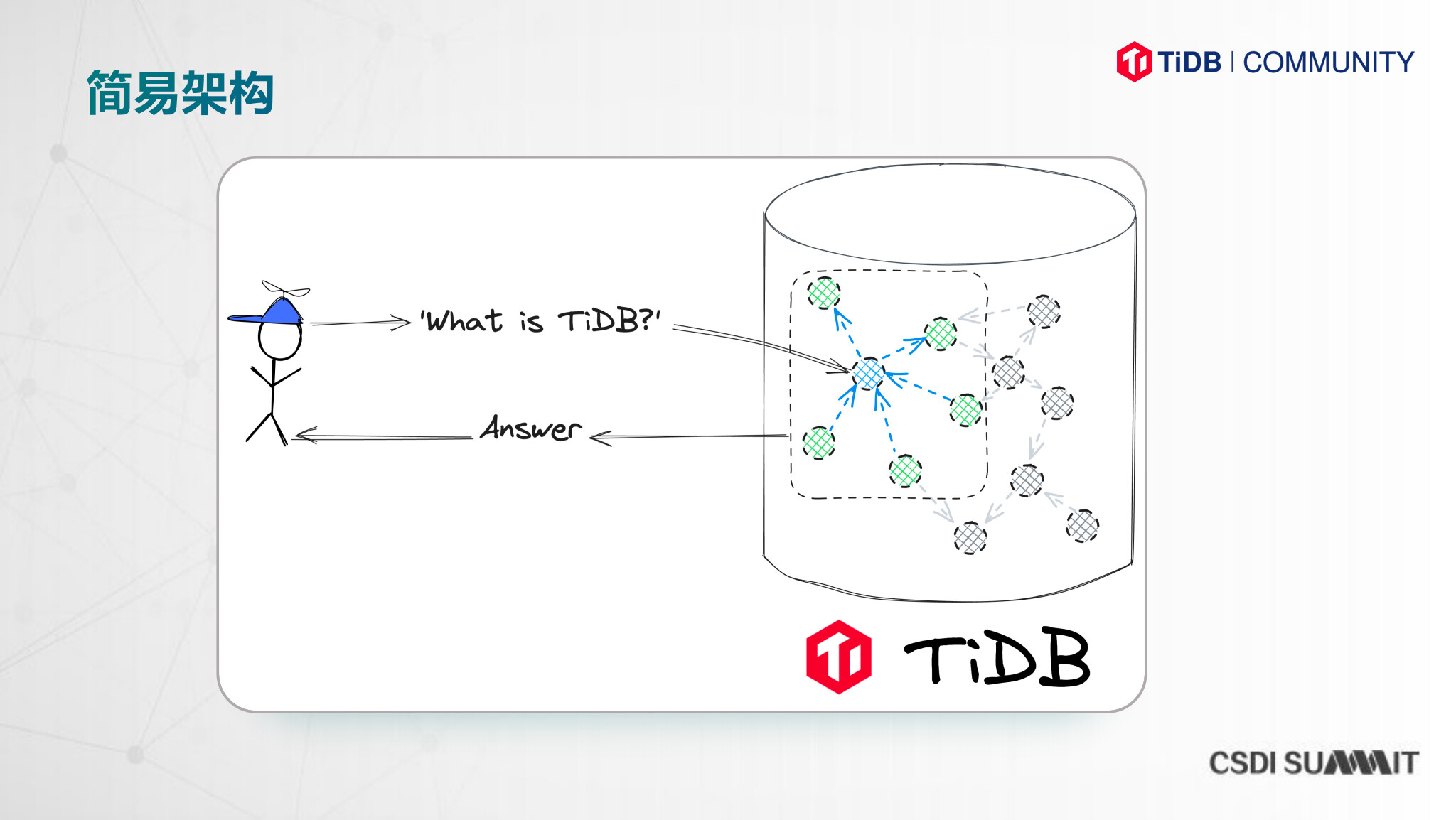

知识图谱的节点构建

All in one数据库:强调 TiDB Serverless 是如何帮助开发者减轻负担,并提供了一个简化的架构和成本效益。

一张图总结 TiDB Serverless 的优劣、与其他技术栈的对比