Zhen37
2024 年9 月 23 日 12:11
1
【 TiDB 使用环境】生产环境
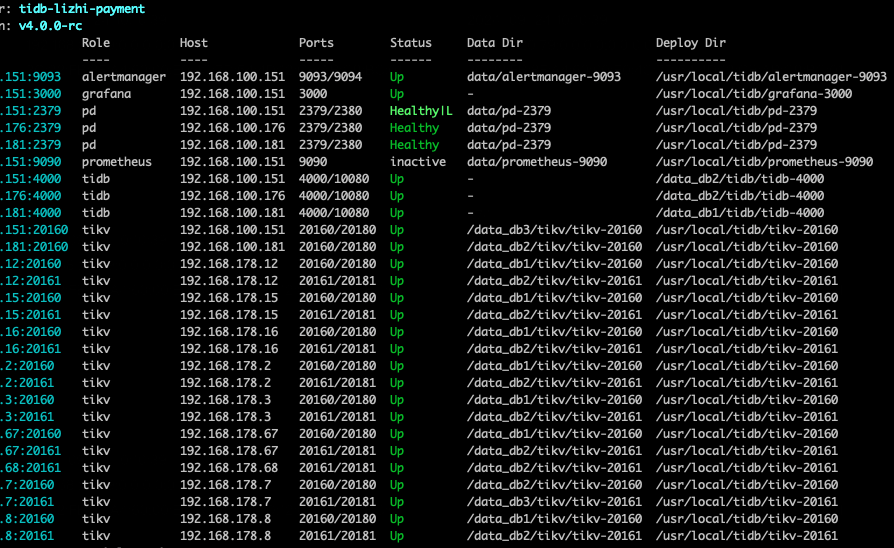
起因是集群中其中一个tikv节点的磁盘故障,故障的tikv节点id为 84033989
尝试删除故障节点,pd-ctl 执行store delete 84033989, 节点状态变为 offline
其他kv节点日志一直报错
[ERROR] [transport.rs:163] [“send raft msg err”] [err=“Other("[src/server/raft_client.rs:208]: RaftClient send fail")”]
执行 curl -X POST http://xxx:2379/pd/api/v1/store/84033989/state?state=Tombstone 以及 tiup ctl pd --pd http://xxx:2379 store delete 84033989 尝试删除 尝试将故障节点强制下线。修改成功后tiup display集群显示已无上述kv节点
查看发现仍然有大量的 pending-peer 和 down-peer ,其他kv节点日志中一直报错
[ERROR] [util.rs:356] [“request failed”] [err=“Grpc(RpcFailure(RpcStatus { status: 2-UNKNOWN, details: Some("invalid store ID 84033989, not found") }))”]
【遇到的问题:问题现象及影响】
目前集群还能正常使用,但其他kv节点一直在报错找不到已被删除的 store id
主要问题是异常节点的 pending-peers 和 down-peers 数量一直不变,集群没办法自动补充新的peer
现在该如何操作能使得故障节点的 down-peers 能在其他正常kv节点上面补全
小龙虾爱大龙虾
2024 年9 月 23 日 15:18
2
看下 PD 监控,看下调度生成情况,还有 checker 工作情况
你一共有几个tikv节点,三个的话,先扩容一个再说
Zhen37
2024 年9 月 24 日 02:13
4
kv 节点非常多,可以先不扩。主要是现在坏掉的store里面那一堆peer都没了,一直处于down-peers状态。pd里面已经把这个store给delete掉了,但其他kv一直还在报连不上这个故障节点
enable-remove-down-replica 用于开启自动删除 DownReplica 的特性。当设置为 false 时,PD 不会自动清理宕机状态的副本。
检查检查这几个配置
1 个赞
h5n1
2024 年9 月 24 日 02:25
6
pd-ctl store 84033989 这个还能看到吗,目前是什么状态?你强制设置tombstone了 试试
1 个赞
Zhen37
2024 年9 月 24 日 02:31
7
就是强制设置了Tomstone,设置成功后pd store 里面 和 tiup display cluster 都看不到这个kv和store了。但就是down-peers和 pending-peers还在,而且没有补充新的peer
h5n1
2024 年9 月 24 日 02:41
9
这个感觉不是查不到了 是报错了,你看pd-ctl region store 84033989 可以查到这个store上的region信息吗?目前想到的1、按上面的清理下tombstone 信息 2、针对store 84033989上的region 通过pd-ctl operator add remove-peer的方式手工添加调度
还有个 enable-remove-down-replica 这个选项。
h5n1
2024 年9 月 24 日 02:51
12
可以参考下面脚本,手工做下调度:
store_list='xxx'
for i in $store_list
do
for j in `pd-ctl region store "$i" | jq ".regions[] | {id: .id}"|grep id|awk '{print $2}'`
do
pd-ctl operator add remove-peer $j $i
done
pd-ctl store $i
done
Zhen37
2024 年9 月 24 日 02:57
13
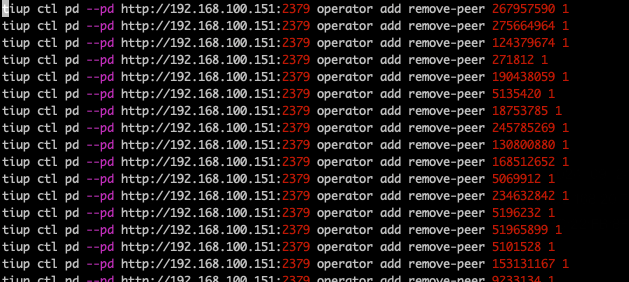
好的,我尝试一下。 其实我已经在check down-peer 里面生成了类似语句,但还没执行,我试试你的脚本看看是否出来的结果一致
tiup ctl pd --pd http://192.168.100.151:2379 region check down-peer |grep -B 1 "start_key" |grep '"id":'|awk '{print "tiup ctl pd --pd http://192.168.100.151:2379 operator add remove-peer "$NF" 1"}'|sed s/,//g
Zhen37
2024 年9 月 24 日 02:59
14
都是开着的,我想大概是我某些操作顺序不当导致出现的这种情况
还有就是这个集群版本确实比较旧了,之前没出问题就一直没去动它
如果你就坏了一个节点,你这个操作没什么问题,尽快修复吧,否则再坏一个就不能提供服务了。至于是用h5n1大神的手动修复还是看看pd抽什么风,都可以,尽快修复是王道。我是感觉最好看看pd为什么不能自动修复这种情况,把问题解决下,否则未来再有副本的丢失的话,pd不能自己干活,纯靠人工无法做到7x24。
缩容tikv建议使用官方提供的步骤;专栏 - TiKV缩容下线异常处理的三板斧 | TiDB 社区
1 个赞
这样的话,感觉还真是你的pd是有点问题的,没有自动补充region的副本到其他节点。。。应该是版本太老的问题
Zhen37
2024 年9 月 24 日 03:28
18
好的,我这边今天操作一下。如果有其他问题再来请教各位
Zhen37
2024 年9 月 24 日 05:11
19
目前已经在执行remove-peer中,请问remove掉坏的peer之后,集群会自动补全peer吗。目前我找了一个region看是剩下2个peer的
得补,你这个pd肯定是有问题了,不能自动修复问题。