【 TiDB 使用环境】测试
【 TiDB 版本】7.5.3
【复现路径】做过哪些操作出现的问题
系统部署好后,就放着,周末没有其他操作
【遇到的问题:问题现象及影响】
系统放置一个周末后过来查看tikv 的内存不断上涨,达到了17G左右
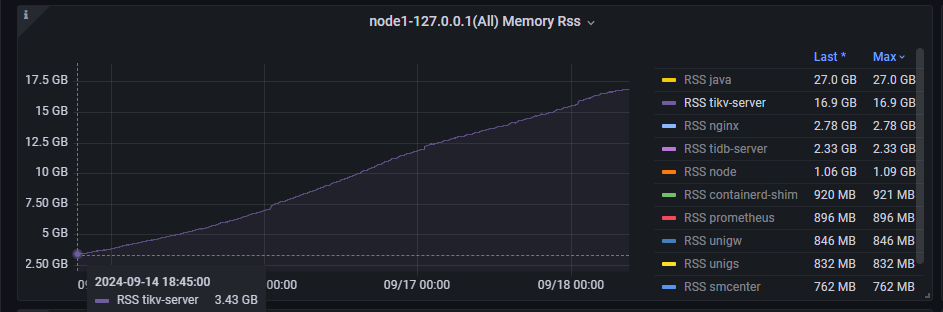
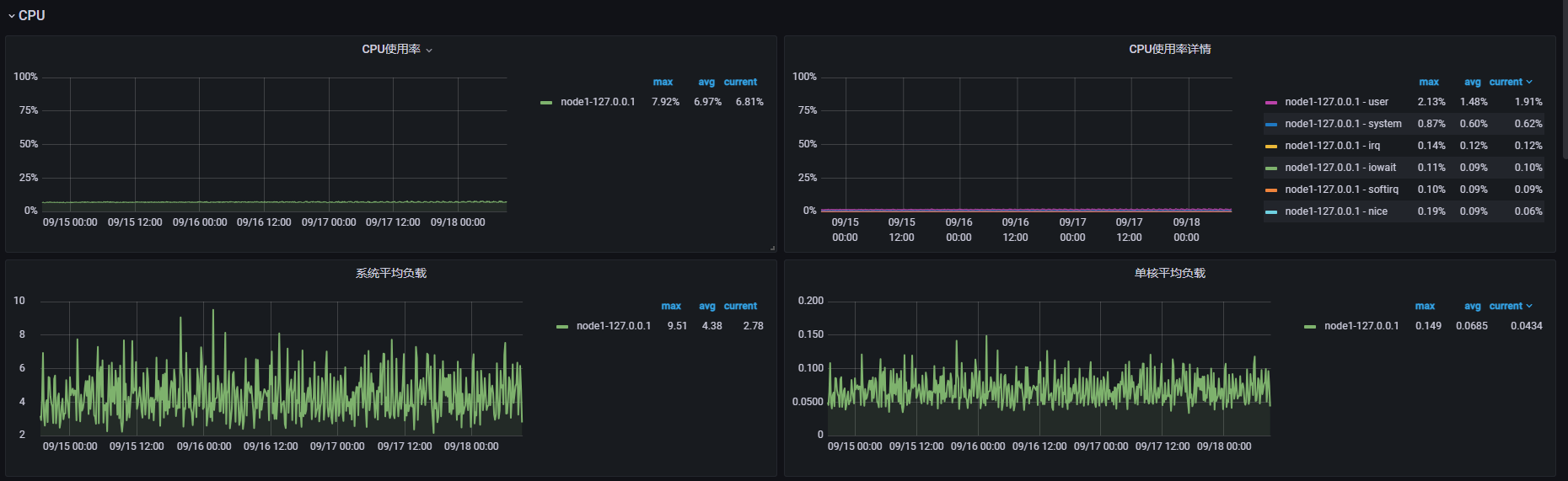
此期间整套系统并没有其他测试任务或操作
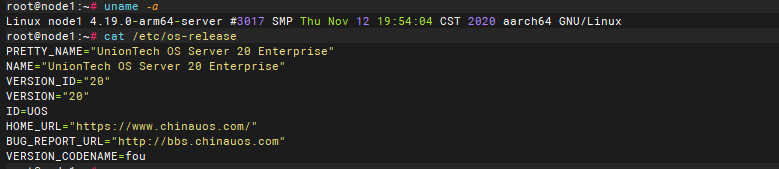
操作系统为UOS的arm系统
THP已关闭

TiKV配置如下
# TiKV config template
# Human-readable big numbers:
# File size(based on byte): KB, MB, GB, TB, PB
# e.g.: 1_048_576 = "1MB"
# Time(based on ms): ms, s, m, h
# e.g.: 78_000 = "1.3m"
log-level = "info"
log-rotation-size = "30MB"
log-rotation-timespan = "1h"
[readpool]
[readpool.coprocessor]
high-concurrency = 64
low-concurrency = 64
normal-concurrency = 32
use-unified-pool = true
[readpool.storage]
normal-concurrency = 10
use-unified-pool = true
[readpool.unified]
auto-adjust-pool-size = true
[pessimistic-txn]
enabled = true
pipelined = true
[server]
grpc-concurrency = 16
grpc-raft-conn-num = 16
[storage]
[storage.block-cache]
capacity = "13043MB"
shared = true
[pd]
# This section will be overwritten by command line parameters
[metric]
[raftstore]
apply-max-batch-size = 1024
raftdb-path = ""
store-max-batch-size = 1024
[coprocessor]
[rocksdb]
max-background-flushes = 4
max-background-jobs = 16
use-direct-io-for-flush-and-compaction = true
wal-bytes-per-sync = 128
[rocksdb.defaultcf]
compression-per-level = ["lz4", "lz4", "lz4", "lz4", "zstd", "zstd", "zstd"]
level0-slowdown-writes-trigger = 64
level0-stop-writes-trigger = 64
[rocksdb.lockcf]
level0-slowdown-writes-trigger = 64
level0-stop-writes-trigger = 64
[rocksdb.writecf]
compression-per-level = ["lz4", "lz4", "lz4", "lz4", "zstd", "zstd", "zstd"]
level0-slowdown-writes-trigger = 64
level0-stop-writes-trigger = 64
[raftdb]
use-direct-io-for-flush-and-compaction = true
[raftdb.defaultcf]
compression-per-level = ["lz4", "lz4", "lz4", "lz4", "zstd", "zstd", "zstd"]
[security]
数据目录大小 9G
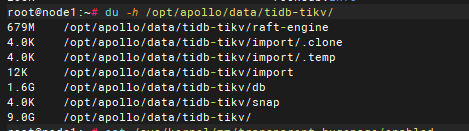
看之前的帖子arm内存高主要是 THP 导致的, 但是已经关闭了,当前几个升级了tidb7.5.3 版本的测试环境 tikv 内存占用都挺高 ,不清楚是不是有什么参数要修改之类的, 各位大佬有没有什么建议的排查方向, 或者有没有对应的经验分享一下。 本人对tidb 还不是很熟悉,不知道该怎么排查了
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
profile文件
profile (199.7 KB)