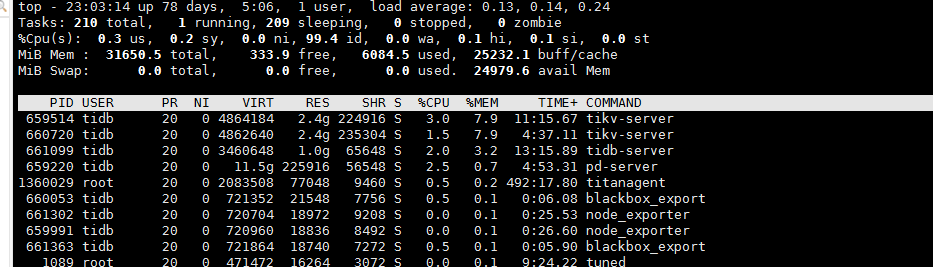
四台32g服务器,混合部署两套tidb集群,配置中限制tikv节点内存使用,基本没效果。
之前对服务器A的一个tikv节点迁到服务器B上面,服务器A的buff/cache降到12g左右
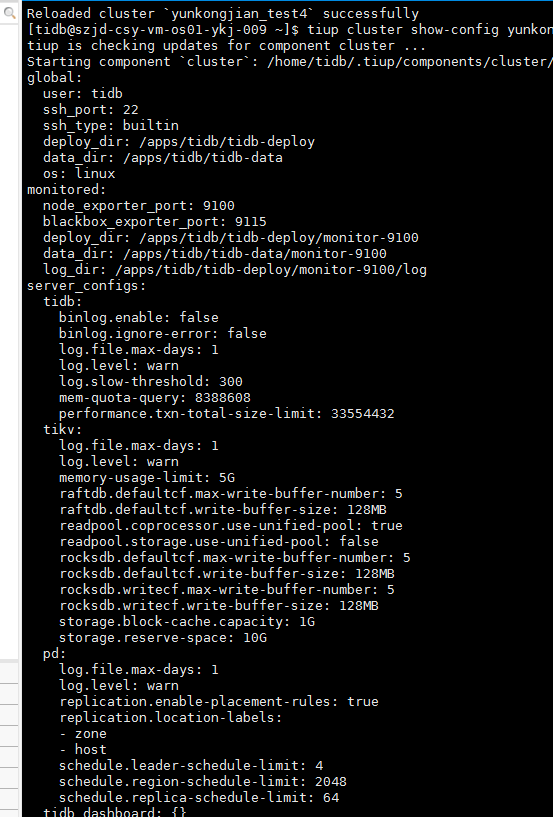
应该怎么调整呢
四台32g服务器,混合部署两套tidb集群,配置中限制tikv节点内存使用,基本没效果。
之前对服务器A的一个tikv节点迁到服务器B上面,服务器A的buff/cache降到12g左右
应该怎么调整呢
这又不影响啥, buff/cache 是可释放的吧,就是读写缓冲吧
宕掉的日志呢?不是因为内存宕掉的吧
tikv里面就是各种超时,感觉就像服务没响应了
其他节点呢,感觉这个节点是连不上远程节点了,看下 pd leader 日志呢
上面那个就是leader
内存有swap么
有没有防火墙这些
PD 几个节点的进程都没有重启吗
pid为1360029跑的是什么
内存该加还得加
感觉资源不够用
内存就是太小了,tidb很吃内存,你不要在一个配置不高机器上混合部署这么多节点
先从/var/log/message里看下是否是因为内存oom导致的
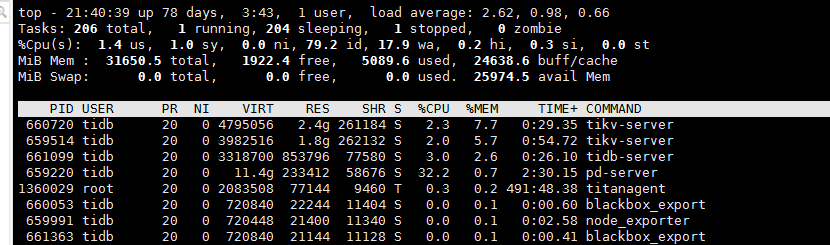
cpu和内存占用都很低,报错也集中在网络问题上,还是要从网络的方向查一查。
buff/cache 的内存占比大概率不是问题所在,如果看不惯可以调整按照上面这个文档调整一下。再尝试一下。
看官方文档适当调整一下吧
linux里面buff/cache里面占用的内存都是可以使用的内存,可以把他当成free就可以,就你现在的资源使用来看,内存肯定不是你这个机器的瓶颈。你的pd报错也是提示请求etcd失败,大概率是pd和tikv之间的网络有问题,往这个方向排查下吧。。。
日志中显示 connection refused 错误,这通常意味着 PD 服务没有在预期的端口上监听,或者网络配置阻止了连接。检查 PD 服务是否在预期的 IP 地址和端口上运行,并且网络配置(如防火墙规则)允许从其他节点到 PD 的连接。
没有oom