【 TiDB 使用环境】 测试
【 TiDB 版本】V7.5.2
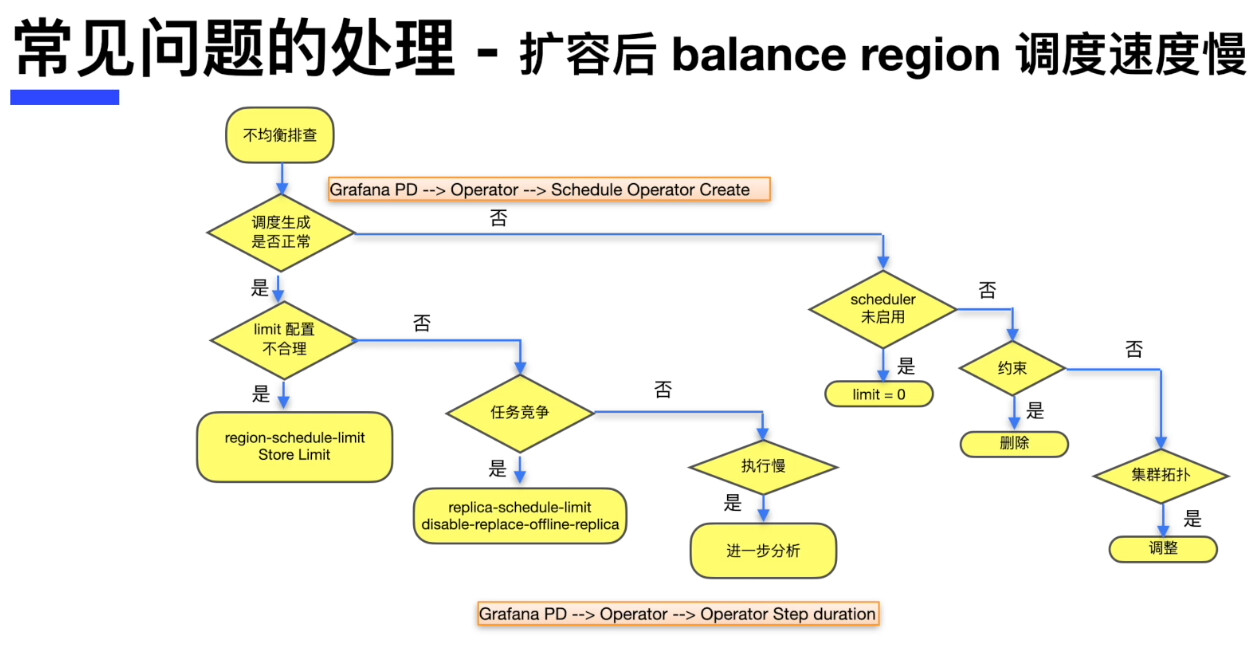
【复现路径】模拟tikv单个实例故障,待TIKV实例变成down状态后,重新scale-out一个新tikv实例发现region恢复速度比较慢,此时看pd的配置无异常【limit配置,store limit 是180】
【遇到的问题: 通过再次调整store limit 为160后,region恢复速度就升高了
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
store limit 180:

store limit 160后:
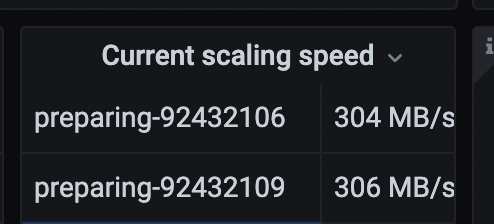
你两张截图的一个是remove,一个是prepare,两者并不一致;正常来说,你可以通过调整pd参数,加快balance的速度。可以参考下里面的调整pd参数加快balance速度的章节:专栏 - 生产环境TiDB集群缩容TiKV操作步骤 | TiDB 社区
tikv不会到瓶颈的,cpu, io, mem,网卡都很闲
看监控截图,感觉网络带宽最大可以到 100MB,是不是千兆网络?
kevinsna
(Ti D Ber P O Zcnp Ja)
11
能否具体说说,贴下比较详细的步骤如何造成这个问题的?
1 个赞
新扩容的tikv的store limit还是默认的15,需要在设置一下新扩容的store limit
验证过了,确实需要调整store limit all xx的限制才能加速恢复的速度
system
(system)
关闭
15
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。