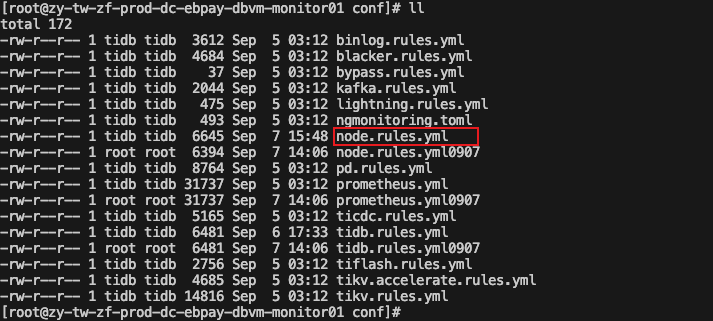
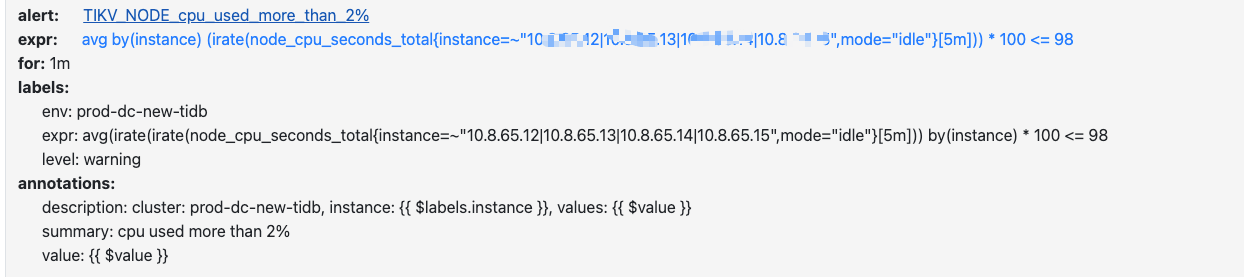
原监控文件
promethes.yml
- job_name: “tikv”
honor_labels: true # don’t overwrite job & instance labels
static_configs:
- targets:
- ‘192.168.25.2:20180’
- ‘192.168.25.3:20181’
- ‘192.168.25.4:20180’
- job_name: “pd”
honor_labels: true # don’t overwrite job & instance labels
static_configs:
- targets:
- ‘192.168.25.5:2379’
- ‘192.168.25.6:2379’
- ‘192.168.25.7:2379’
rule.yml
- alert: NODE_cpu_used_more_than_20%
expr: avg(irate(node_cpu_seconds_total{mode=“idle”}[5m])) by(instance) * 100 <= 80
for: 3m
labels:
env: prod-dc-new-tidb
level: warning
expr: avg(irate(irate(node_cpu_seconds_total{mode=“idle”}[5m])) by(instance) * 100 <= 80
annotations:
description: ‘cluster: prod-dc-new-tidb, instance: {{ $labels.instance }}, values: {{ $value }}’
value: ‘{{ $value }}’
summary: cpu used more than 20%
node_cpu_seconds_total 这个规则汇聚了tidb,tikv,pd等所有节点
问题
如何将tidb tikv pd 各自分割配置
这个metric node_cpu_seconds_total{mode=“idle”,instance=~“(10.0.74.222|10.0.74.228):.*”} 只有instance可以进行识别
up:up{group=“pd”, instance=“10.0.74.226:2379”, job=“tidb_port_probe”}
还有group可以判断
你是不是理解错了,tidb已经为你分割了告警配置,比如打开的就是pd的。如果需要,可以在pd.rules.yml添加你的告警项。测试的5版本也是这样:
我的意思是 有一个 系统cpu 的告警规则
node.rules.yml
- alert: NODE_cpu_used_more_than_30%
expr: avg(irate(node_cpu_seconds_total{mode=“idle”}[5m])) by(instance) * 100 <= 70
for: 1m
labels:
env: prod-dc-new-tidb
level: warning
expr: avg(irate(irate(node_cpu_seconds_total{mode=“idle”}[5m])) by(instance) * 100 <= 70
annotations:
description: ‘cluster: prod-dc-new-tidb, instance: {{ $labels.instance }}, values: {{ $value }}’
value: ‘{{ $value }}’
summary: cpu used more than 30%
这个文件会告警所有 node 节点的cpu
问题
向把这个cpu 告警进行分组,tidb tikv pd tiflush 各一组
那你就手动看每一个metric,有group这种就用group,没有就按默认的instance写死过滤ip,可以嘛
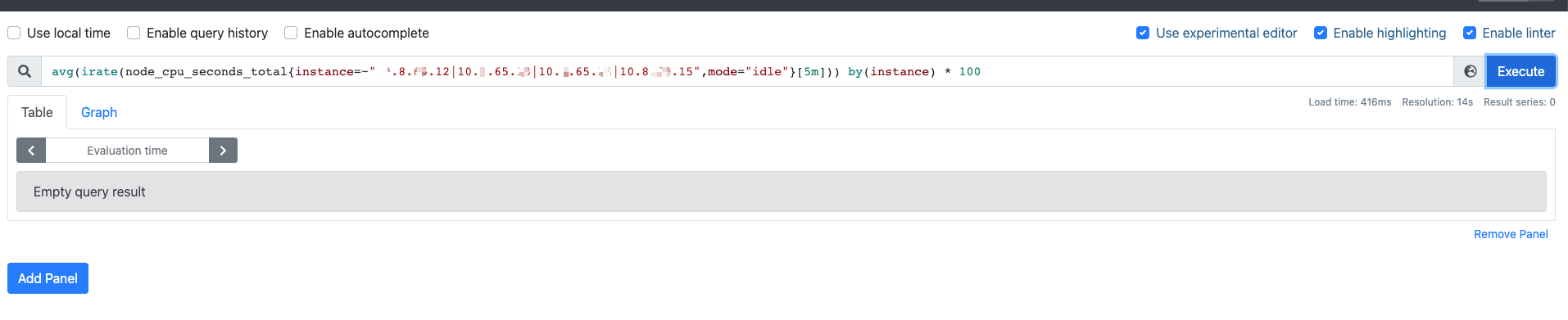
这是添加的 tikv 单独的cpu node 告警 没有获取到值
先把表达式放prome里查一下,看看有值没有,在这里填好表达式,再放配置文件
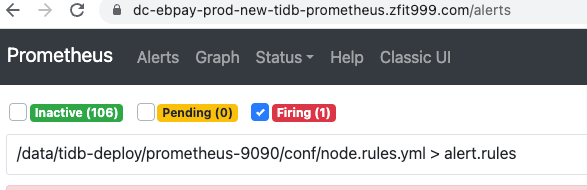
新的firing不是嘛?
prometheus修改了rules.yml,要热加载或者重启一下,其他的没有其他问题(解决了给个最佳啊)
看
里的规则,包含你信修改的项吗,不包含就是prometheus没有最新的文件,重启或热加载下
热加载过,还是获取不到 tikv 节点的cpu值
node.rules.yml
原配置所有node cpu的规则 正常
添加过滤 tikv 节点cpu 后的规则
正常了,获取到值了
system
(system)
关闭
12
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。