【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1.0
【复现路径】观察监控平台的kv节点
【遇到的问题:问题现象及影响】部分kv的leader经常降到0 ,然后再恢复正常
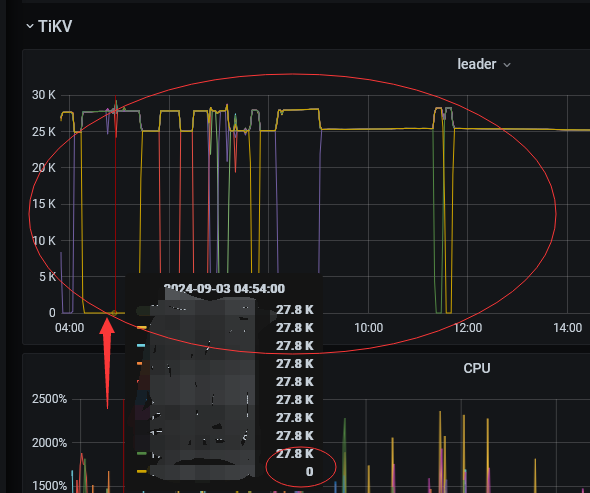
能看到 prometheus 的日志上有 pull metrics 异常的信息吗?从掉 0 到恢复的时间有点断,猜测是不是 拉取的时候发生问题了
kv有重启吗?
出现这种情况,说明tikv节点大概率在反复重启,通常出现这个问题是大SQL查询大量数据或者是block Cache设置不合理或者是单机部署了太多tikv节点导致的。
请确认下机器是否有反复重启,也确认tikv的内存监控、tikv节点启动时间监控情况。
1 个赞
你看下是不是业务行为导致leader被驱逐
这种情况我遇到过,我一般重启对应服务器问题就不再发生,我出现问题的版本为v3.1.0
集群tikv不断重启(概率大),或者网络丢失会出现这样的情况
看看tikv是不是重启了