MrSylar
( Mr.Sylar)
2
我有另外一个方式,修改 tidb_isolation_read_engines,把 tiflash 移除掉,那么理论上 SQL 就不会用 tiflash 了,然后再 scale-in
1 个赞
了解。按您的方法来讲能快速scale-in tiflash么。
我这边整体计划是:
先scale-in AZ1的tiflash
再scale-out AZ2的tiflash
MrSylar
( Mr.Sylar)
4
那我理解的不对了,我以为咱们的最终目的是“不用 tiflash”。但目前看咱们的目的只是“快速缩容 tiflash”
是的,快速缩容。
之前想到,担心时效太慢(节点状态变为Tombstone太慢):
1、缩所有表副本=0
2、scale-in tiflash
3、scale-in tiflash --force
没试过这个 https://docs.pingcap.com/zh/tidb/v7.1/tikv-control#设置一个-region-副本为-tombstone-状态
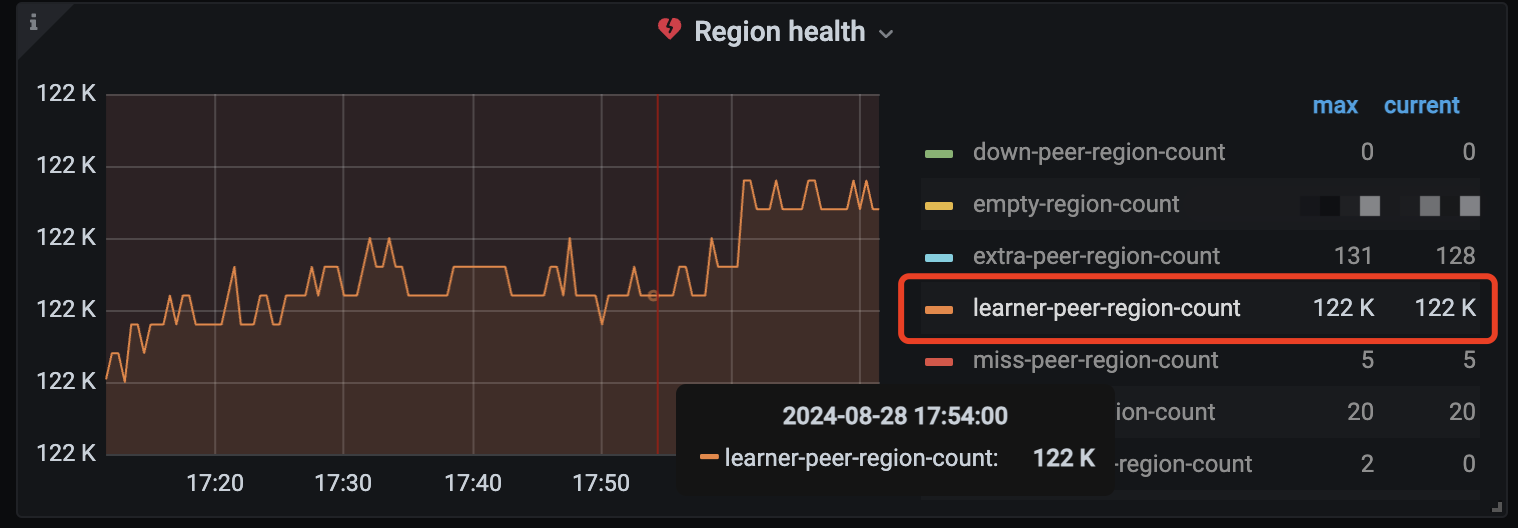
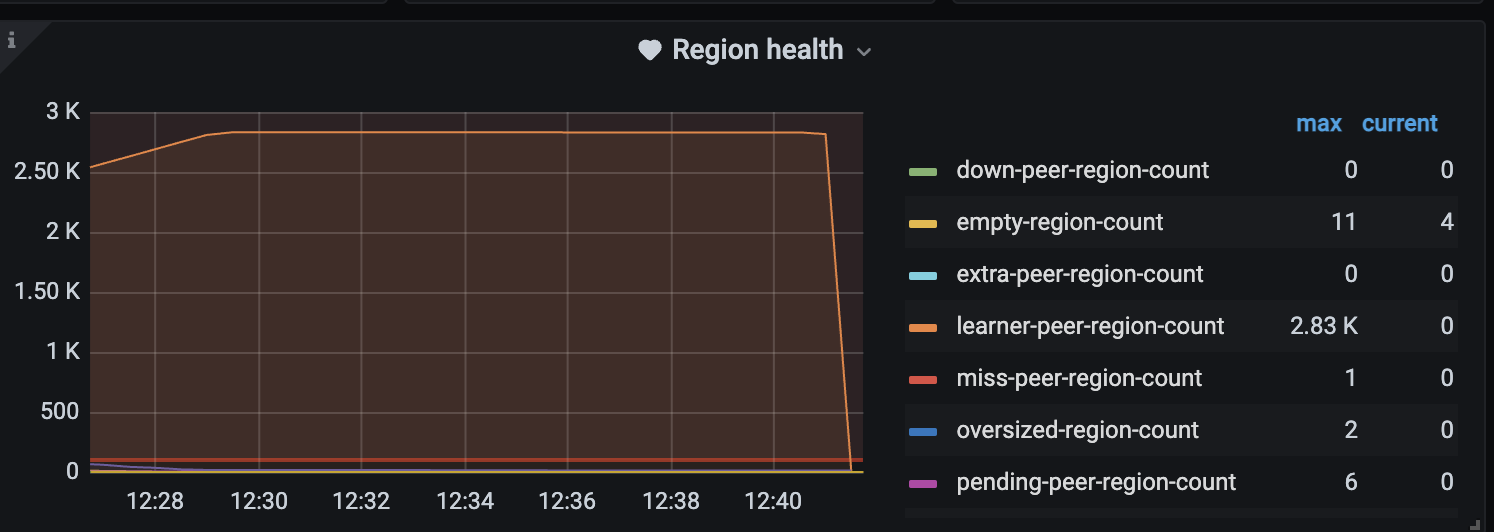
dev 环境测试,alter replicat 0;后 scale-in时候节点状态立刻变为 Tombstone。
个人猜测:
1、tiflash都是leaner,缩容很快。
2 个赞
有猫万事足
11
如果你的目的是把tiflash从az1迁往az2,我觉得应该先扩容,再缩容。
特别是开了mpp模式的情况下,因为mpp模式下所有tiflash节点都参与计算,如果先缩容,可能导致mpp的效率短期下滑,造成很多慢查询。影响系统稳定。
先扩容再缩容就好一些。
如果彻底不用tiflash的角度,我觉得 @MrSylar 的方案更好。