1 问题
tispark2.5执行任务挺快,但是升级到tispark3.1.6后执行观察任务会花费30s到60s处理tidb的元数据,有什么方法能不执行这段操作么?
2 任务描述
一个insert into select类型的任务,输入表为hive表和tidb表,输出表是hive表。
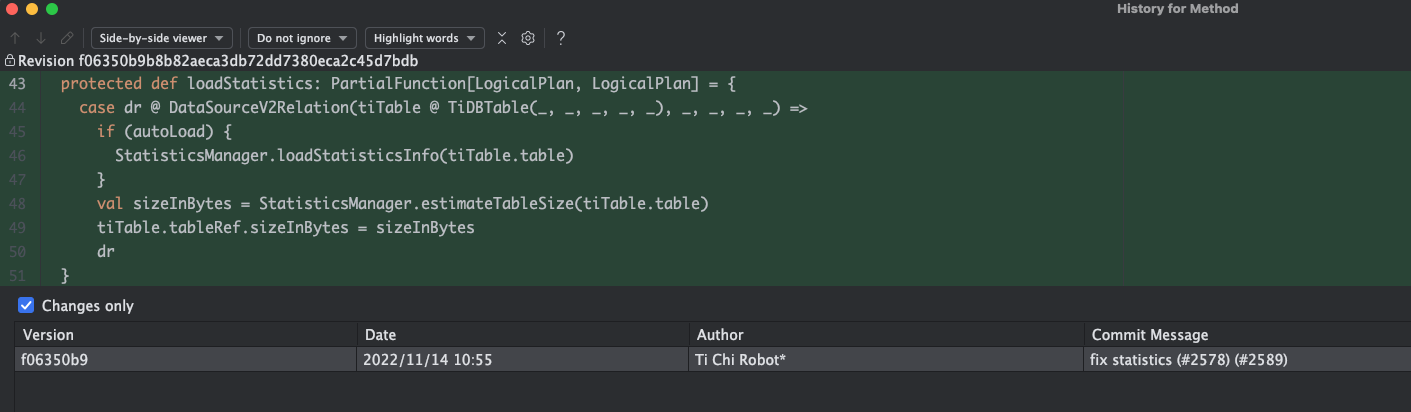
在tispark2和3执行的区别就是使用tispark3运行的任务语句中所有tidb的表加上了tidb_catalog前缀,tispark2没有加前缀。
tispark2版本组合:spark3.1.2+tispark2.5.2
tispark3版本组合:spark3.3.3+tispark3.1.6
tispark2执行时间:88s
tispark3执行时间:244s
两个都使用kyuubi1.9.0提交,资源参数设置都一致。
3. 问题日志
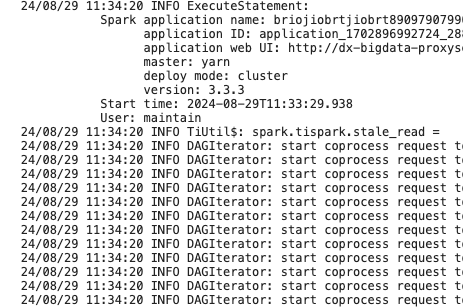
通过观察使用tispark3执行的日志可以发现有一些地方会花费将近一分钟的时间,例如11:14:
24/08/28 11:14:57 INFO ExecuteStatement:
Spark application name: briojiobrtjiobrt8909790799078
application ID: application_1702896992724_28754891
application web UI: http://server1-pm:8080/proxy/application_1702896992724_28754891
master: yarn
deploy mode: cluster
version: 3.3.3
Start time: 2024-08-28T11:13:47.633
User: maintain
24/08/28 11:14:57 INFO TiUtil$: spark.tispark.stale_read =
24/08/28 11:15:45 WARN KVErrorHandler: NotLeader Error with region id 4146387906 and store id 4138101747, new store id 26634932
24/08/28 11:15:45 WARN KVErrorHandler: Store Not Match happened with region id 4146387906, store id 26634932, actual store id 26634932
24/08/28 11:15:45 WARN KVErrorHandler: Failed to send notification back to driver since CacheInvalidateCallBack is null in executor node.
24/08/28 11:15:45 WARN RegionStoreClient: Re-splitting region task due to region error:to store id 4138101747, mine 26634932
但是在tispark2中没有这种情况,任务正常执行:
24/08/28 11:23:24 INFO ExecuteStatement:
Spark application name: ijgiojeiojgioerjhgio43
application ID: application_1702896992724_28755705
application web UI: http://server1-pm:8080/proxy/application_1702896992724_28755705
master: yarn
deploy mode: cluster
version: 3.1.2
Start time: 2024-08-28T11:23:12.320
User: maintain
24/08/28 11:23:29 INFO InMemoryFileIndex: It took 66 ms to list leaf files for 1 paths.
24/08/28 11:23:30 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
24/08/28 11:23:30 INFO SQLHadoopMapReduceCommitProtocol: Using output committer class org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
24/08/28 11:23:30 INFO CodeGenerator: Code generated in 64.830432 ms
24/08/28 11:23:30 INFO DAGScheduler: Registering RDD 6 (sql at ExecuteStatement.scala:99) as input to shuffle 0
24/08/28 11:23:30 INFO DAGScheduler: Got map stage job 0 (sql at ExecuteStatement.scala:99) with 101 output partitions
24/08/28 11:23:30 INFO DAGScheduler: Final stage: ShuffleMapStage 0 (sql at ExecuteStatement.scala:99)
24/08/28 11:23:30 INFO DAGScheduler: Parents of final stage: List()
24/08/28 11:23:30 INFO DAGScheduler: Missing parents: List()
24/08/28 11:23:30 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[6] at sql at ExecuteStatement.scala:99), which has no missing parents
24/08/28 11:23:30 INFO SQLOperationListener: Query [e3c5c291-f2e3-43b5-98b2-0f6b59d59cf5]: Job 0 started with 1 stages, 1 active jobs running
24/08/28 11:23:30 INFO CodeGenerator: Code generated in 27.225805 ms
24/08/28 11:23:30 INFO SQLOperationListener: Query [e3c5c291-f2e3-43b5-98b2-0f6b59d59cf5]: Stage 0.0 started with 101 tasks, 1 active stages running
24/08/28 11:23:30 INFO YarnAllocator: Resource profile 0 doesn't exist, adding it
24/08/28 11:23:30 INFO YarnAllocator: Driver requested a total number of 1 executor(s) for resource profile id: 0.
24/08/28 11:23:30 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 1 for resource profile id: 0)
24/08/28 11:23:30 INFO YarnAllocator: Will request 1 executor container(s) for ResourceProfile Id: 0, each with 1 core(s) and 4505 MB memory.