yeminhua
2024 年8 月 26 日 04:59
1
【 TiDB 使用环境】生产环境
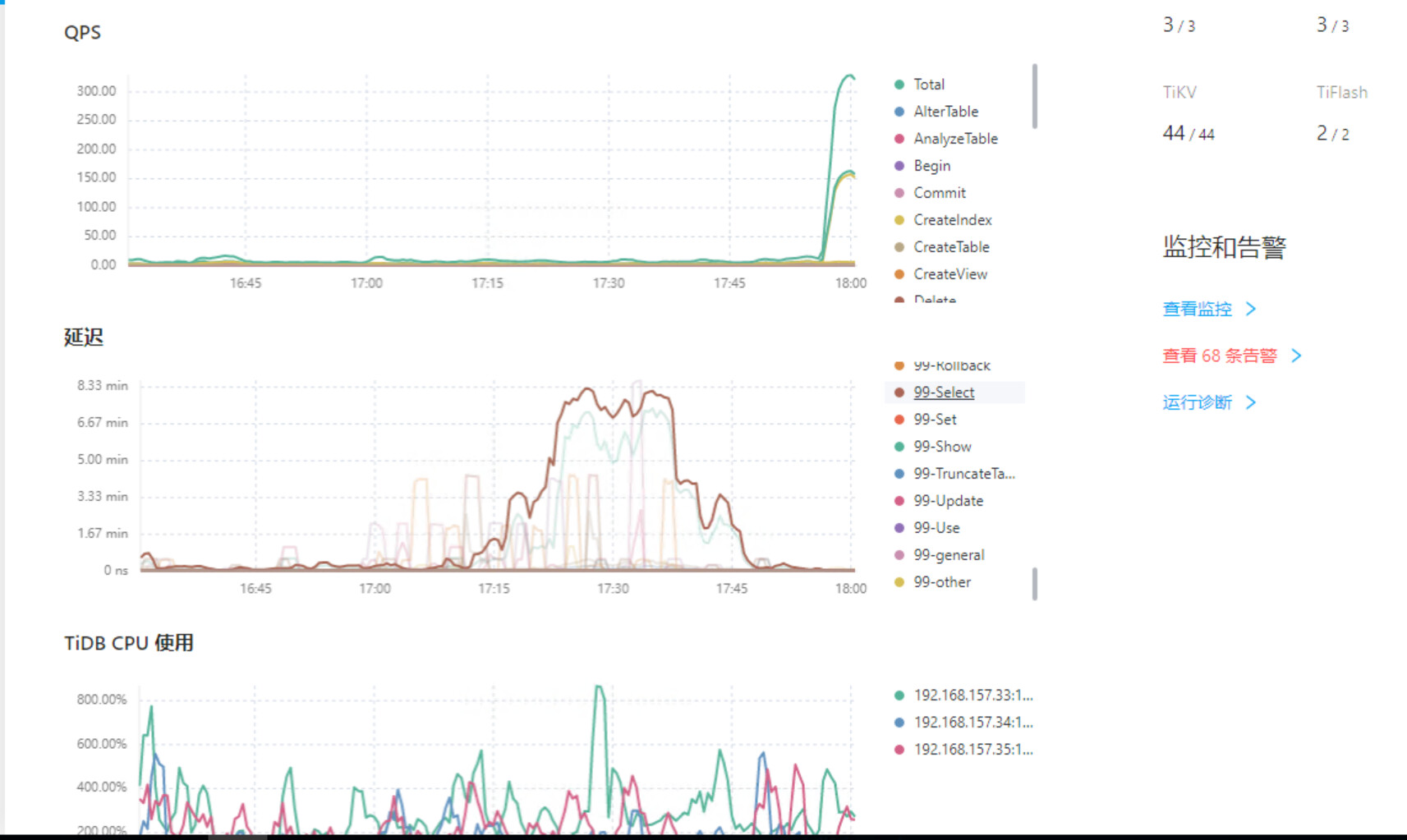
查询时间从几秒攀升到几分钟
日志中的warning是平时就有存在的,没有新的特殊的错误日志
不知道这问题该如何排查?
最后升级到6.5.10,确实稳定很多,升级后观察两周没再出现该问题,DDL锁的问题也基本没有了,感谢各位大佬。
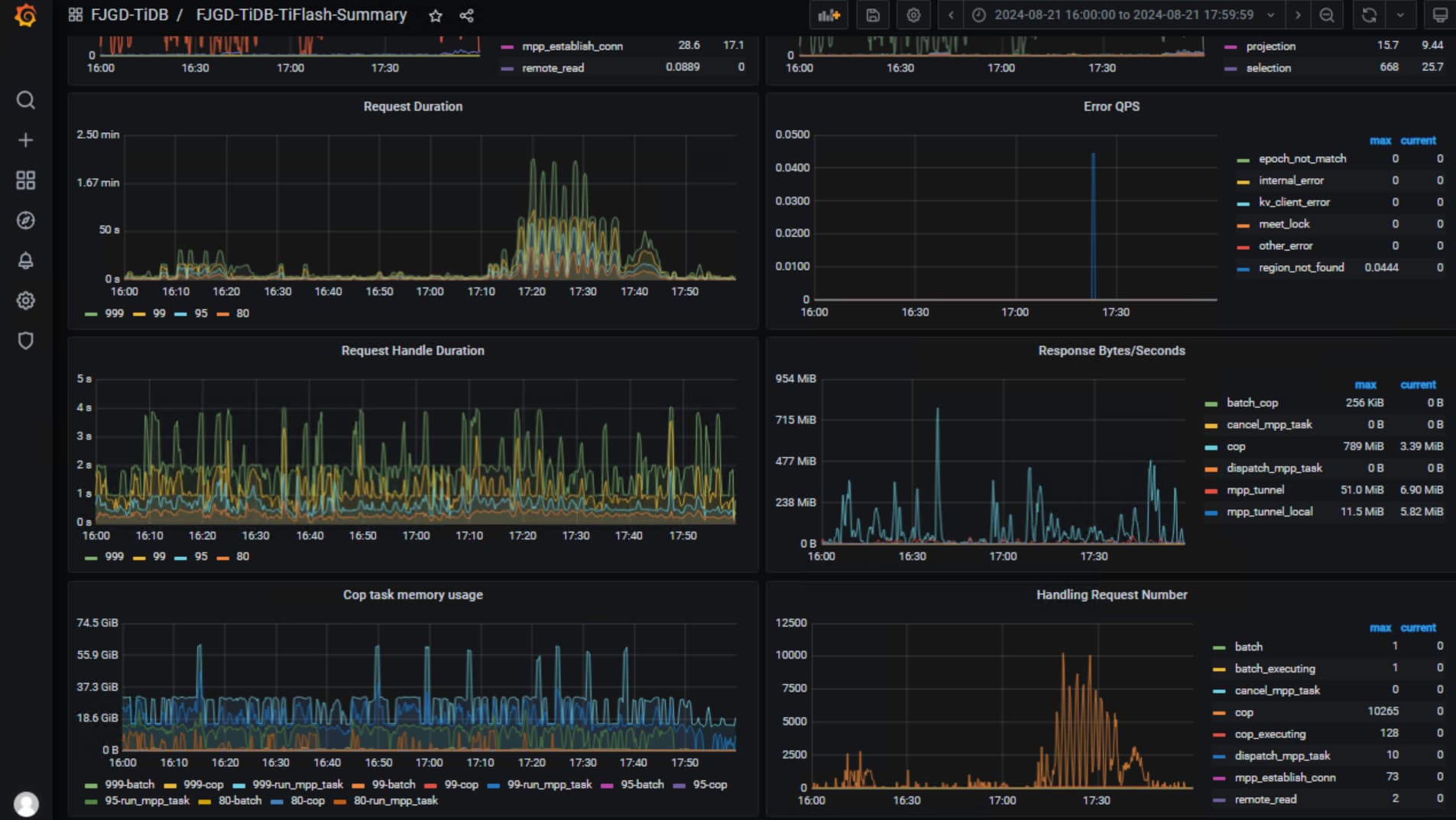
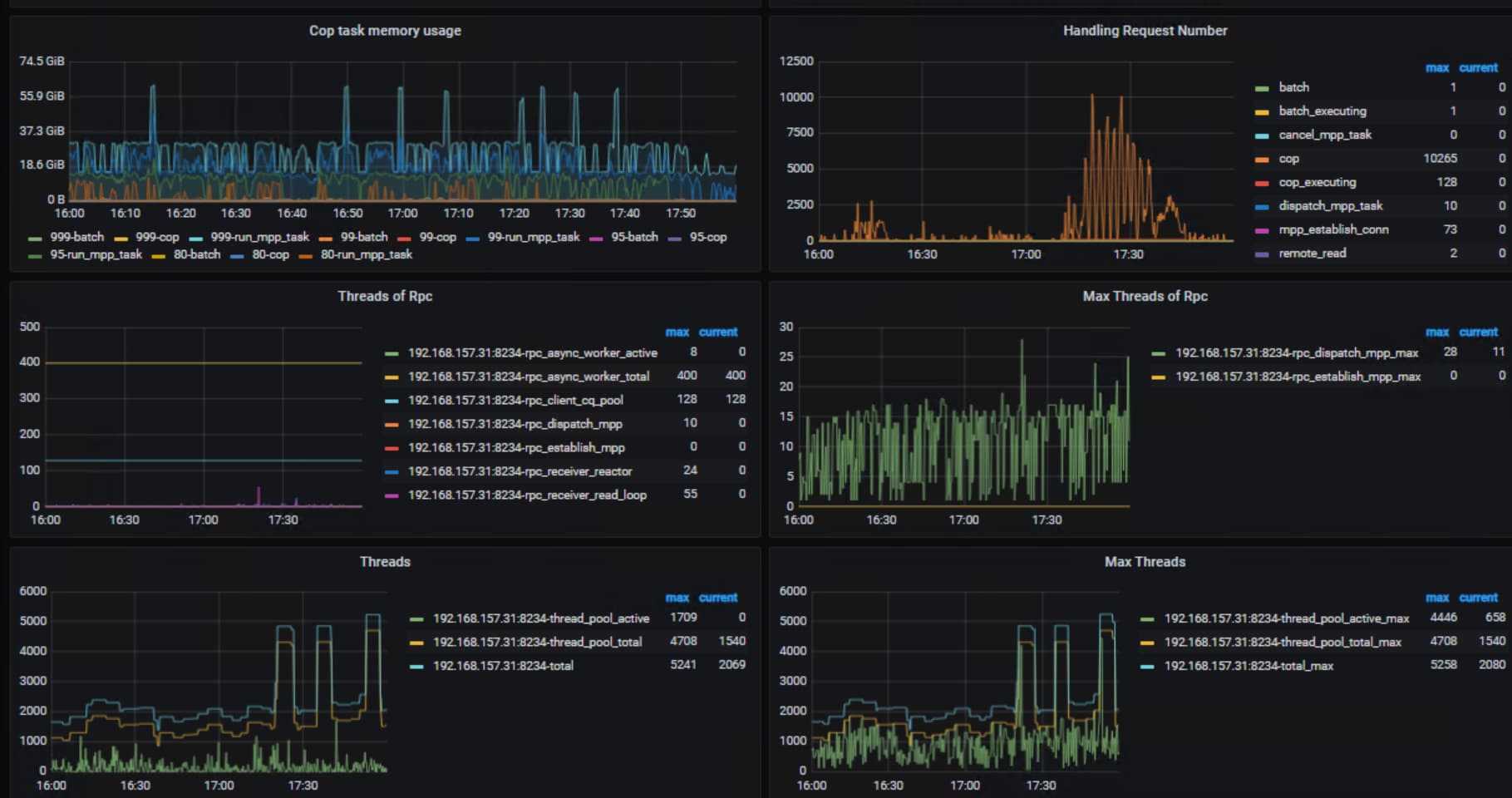
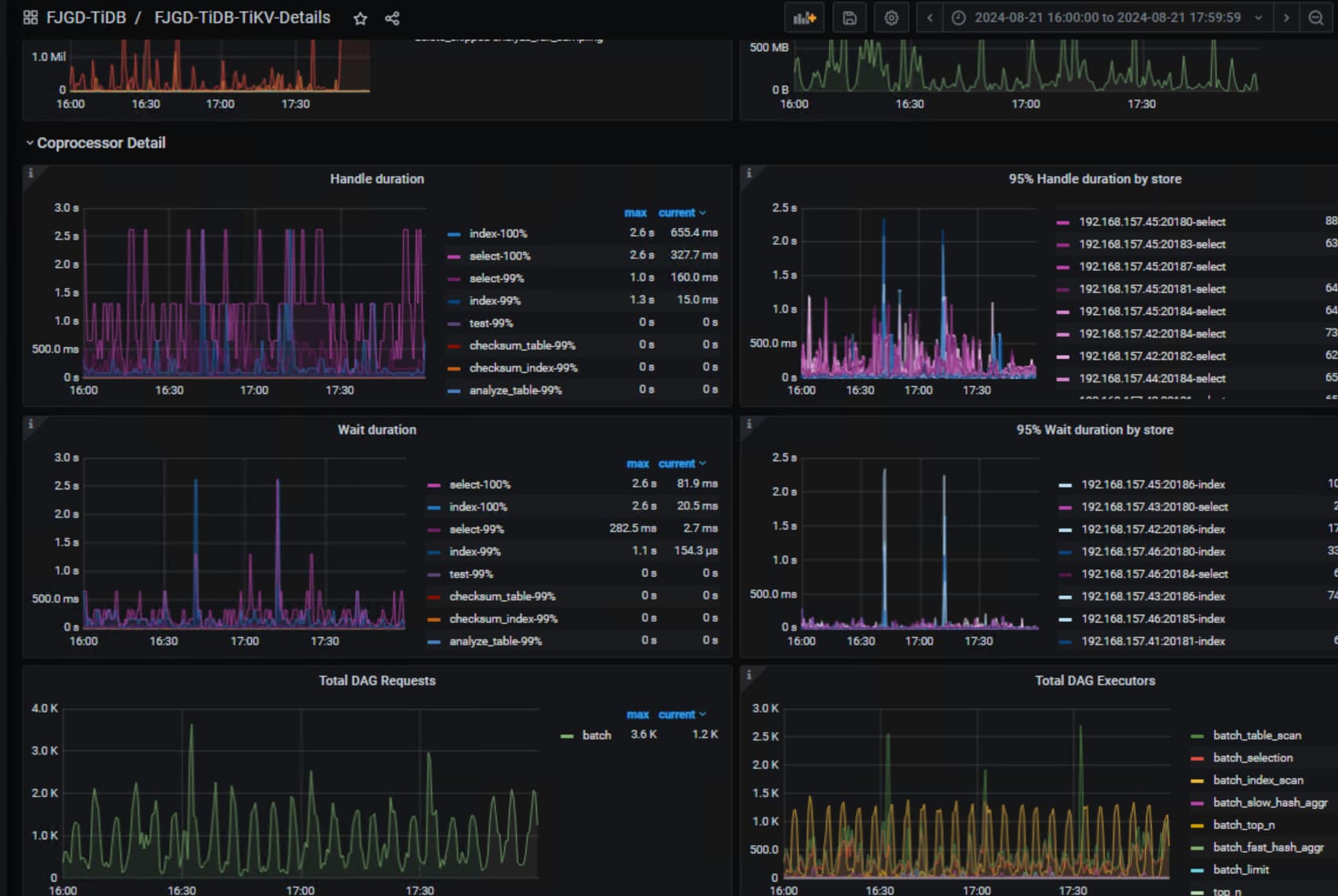
看下两个tiflash节点在对应时间点的cpu使用情况,就在summary界面看下就行,另外看下coprocessor
yeminhua
2024 年8 月 26 日 08:47
3
tidb菜鸟一只:
coprocessor
另外一台监控漏了,但是主机上的cpu使用情况差不多
tiflash机器上cpu128核?看你用了大概用了50核的样子,看着tiflash的负载确实不算高, tidb_max_tiflash_threads这个SHOW GLOBAL VARIABLES LIKE '%tidb_max_tiflash_threads%'看下设置是-1吗,当时是仅仅tiflash类的请求慢吗?你看下没有用tiflash的sql是不是也很慢
yeminhua
2024 年8 月 27 日 02:28
5
设置的是-1,从tikv看,17点-18点没什么延迟或特别慢的
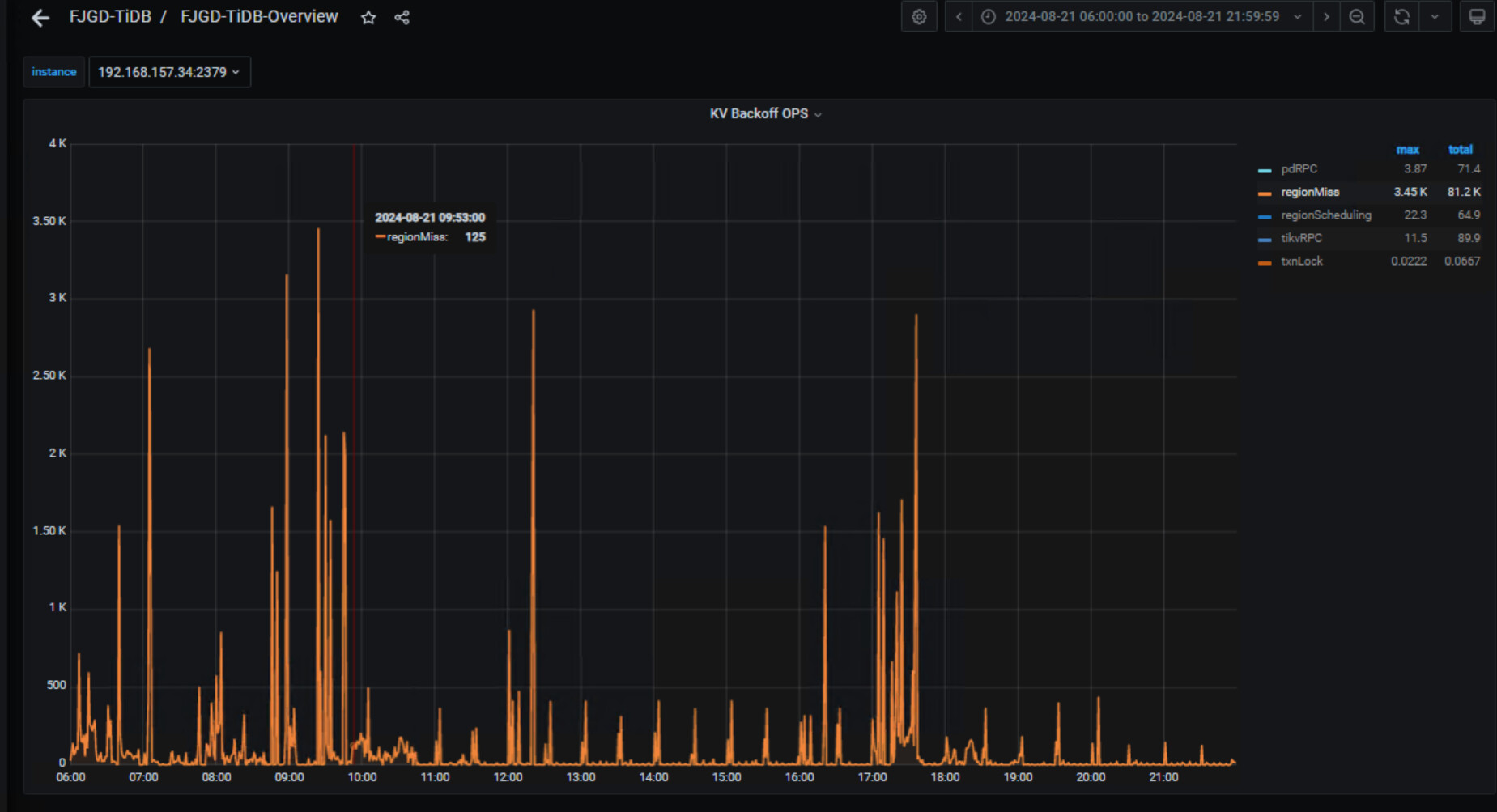
对应时间点garafana监控里面overview→tidb→KV Backoff OPS,这里看下有rpc异常重试吗?
yeminhua
2024 年8 月 27 日 06:46
7
有的,regionMiss是一直都是比极高,tikvRPC当时很高,其它日期最高不超过1,这个主要表示什么问题?
你的regionmiss很高但是问题点出现之前也有这情况,这个可能就是你的集群写入并发量太大了,reigon一直在分裂调度,导致tidb-server从pd获取的region信息报错而重试。感觉你的tikv应该很忙啊,但是你问题点的时候tikv又没问题。。。。你看下tidb的日志,在对应时间点有报错吗?
h5n1
2024 年8 月 27 日 09:28
10
yeminhua:
涉及tiflash的查询都变的很慢
有那些应该访问tiflash的SQL的完整执行计划吗
yeminhua
2024 年8 月 27 日 10:32
11
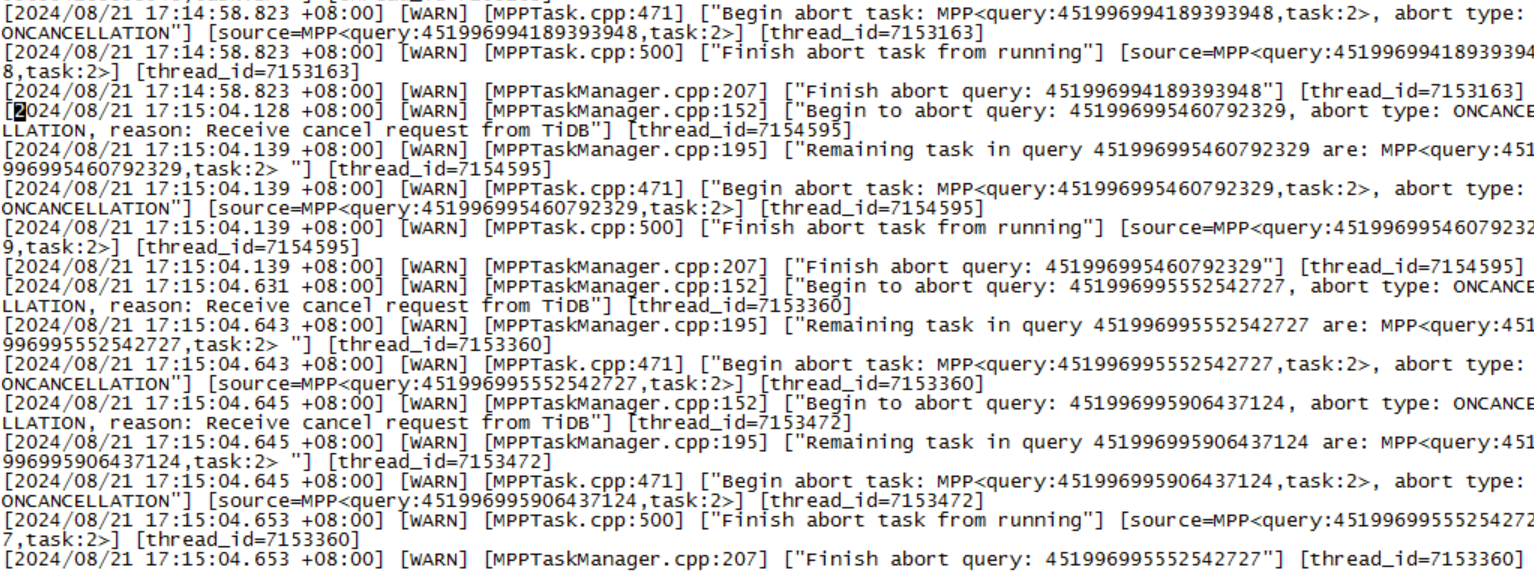
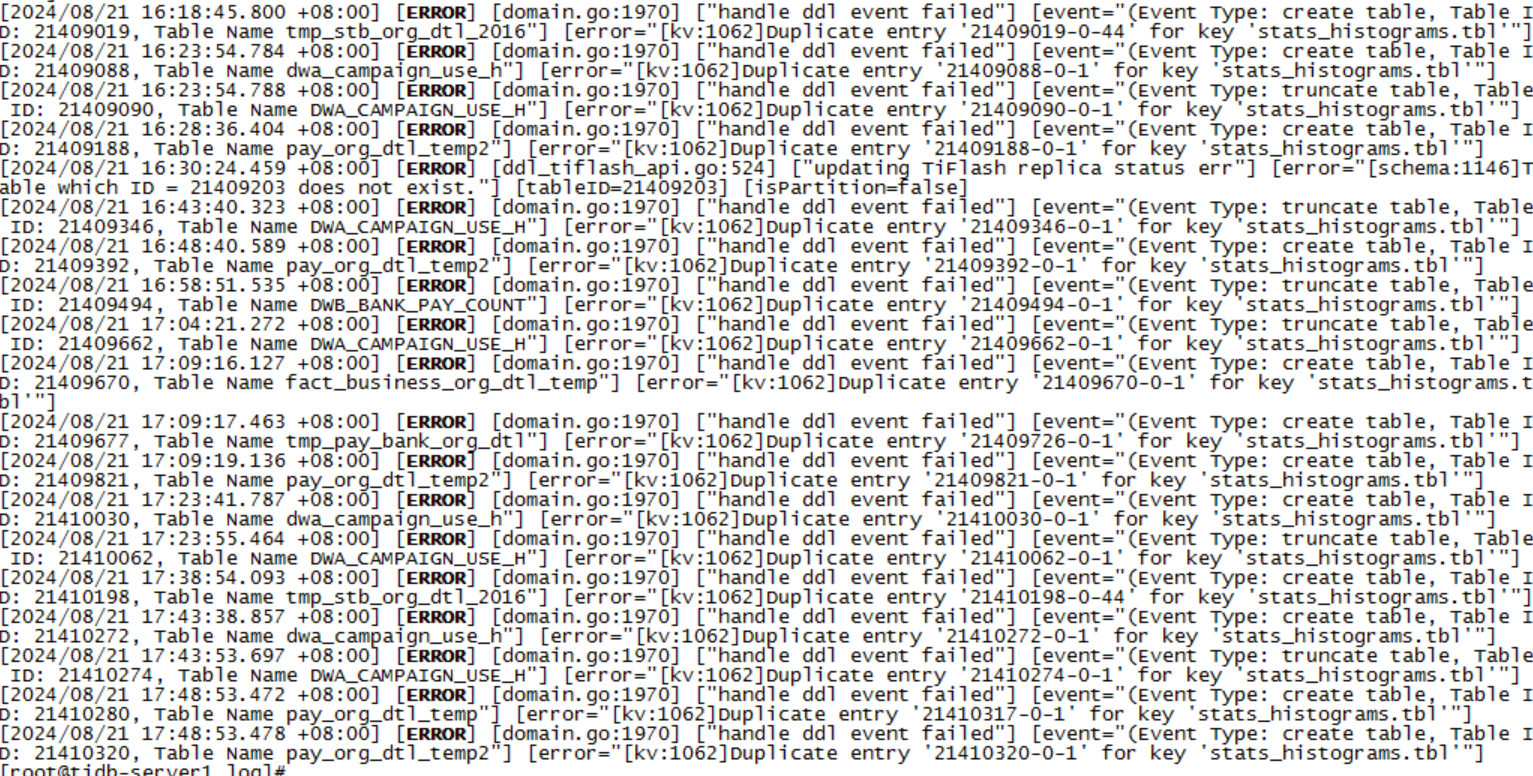
只有几个DDL的error日志,warn的大部分都是record table item load status failed due to not finding item
yeminhua
2024 年8 月 27 日 10:36
12
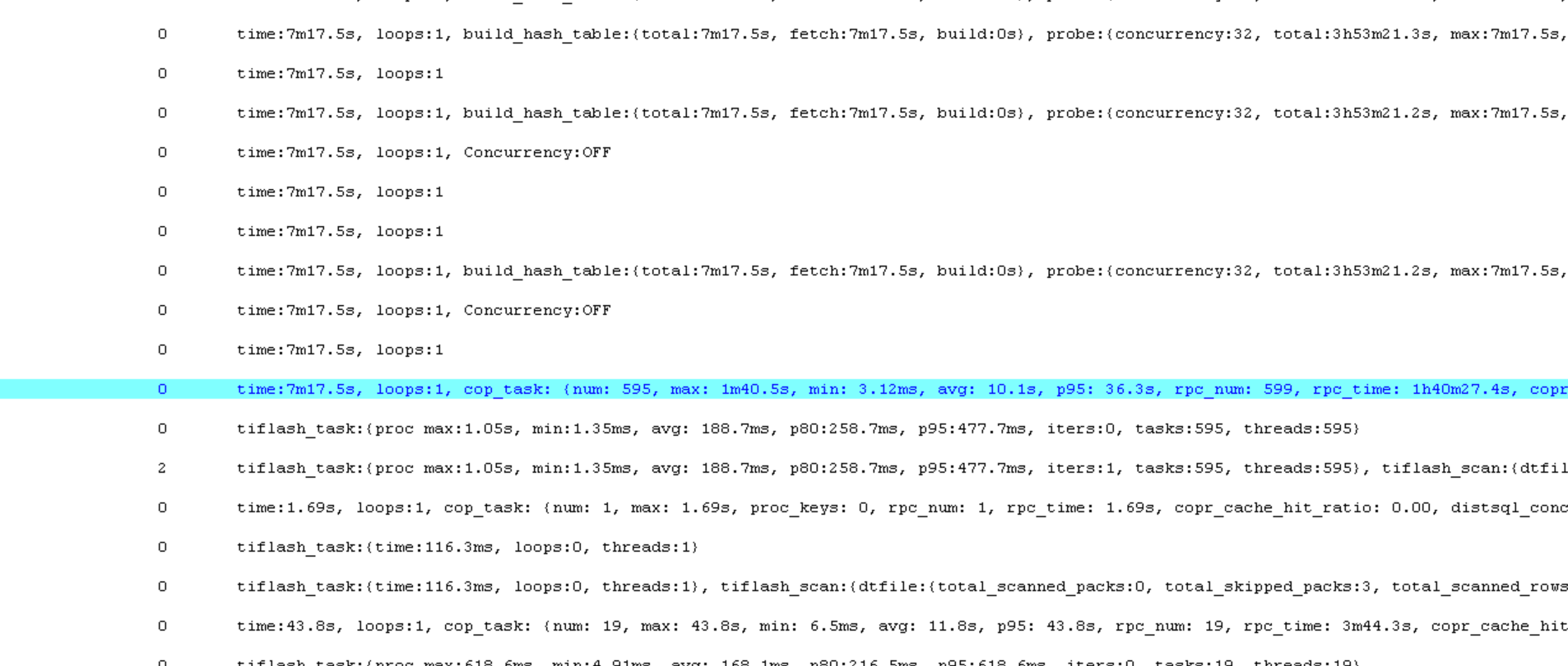
快.txt (4.2 MB)慢.txt (4.2 MB)
你这执行计划全是pseudo关键字啊,要不先把表的统计信息收集下呢。。。。
yeminhua
2024 年8 月 28 日 07:38
16
收集了执行计划还是有pseudo字眼,执行计划和平时快的时候差不多,这个分区表全表就3000多万数据,也不算太大。
个人猜测 1.Tiflash是fork ClickHouse开发的虽然没有直接沿用LSMTree存储引擎 而是重写了更适合HTAP 场景的列存引擎DeltaTree 但是类比CK 的LSMTree数据Merge过程中会存在数据不可用情况 外在表现就是Hang住了一般
1 个赞
yeminhua
2024 年8 月 30 日 09:58
18
只有两个tiflash节点,tiflash两副本,数据没有明显倾斜。在集群变慢时,从主机资源来看反而似乎都空闲下来了。目前只能把所有tiflash表的统计信息健康度低于70的都定时收集下,再跟踪几天看下。
1 个赞
有猫万事足
2024 年8 月 30 日 14:36
19
yeminhua
2024 年9 月 2 日 01:37
20
我们也打算这周升到6.5.10,到时候再看下,感谢
1 个赞
Jasper
2024 年9 月 2 日 03:43
21
现在问题解决了吗? 从监控看能明显看到 cop 的 request 增加了很多,建议可以从 sql 入手看下对应时间段有没有异常sql大量访问 tiflash 节点