JOJO_DB
(Ti D Ber Bp09o D Co)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.30
【复现路径】暂无
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
tidb server自动重启、检查log后发现以下报错、已经持续半个月了,随机性的再不同节点上出现。
检查发现每次出现问题都会有以下SQL语句。不太清楚具体是什么原因造成的。
select HlGH_PRlORITY table_id, is_index, hist_id, count, repeats, lower bound, upper_bound, ndv from mysql.stats_buckets order by table_id, is_index, hist_id, bucket_id;
Kongdom
(Kongdom)
3
 随机重启不同节点?看看节点重启前的内存使用,如果特别大就是有OOM了,检查一下OOM日志吧。
随机重启不同节点?看看节点重启前的内存使用,如果特别大就是有OOM了,检查一下OOM日志吧。
JOJO_DB
(Ti D Ber Bp09o D Co)
4
监控那边查过~内存、cpu负载都不高、还很低。而且几乎都是非生产时间出现的问题。
JOJO_DB
(Ti D Ber Bp09o D Co)
6
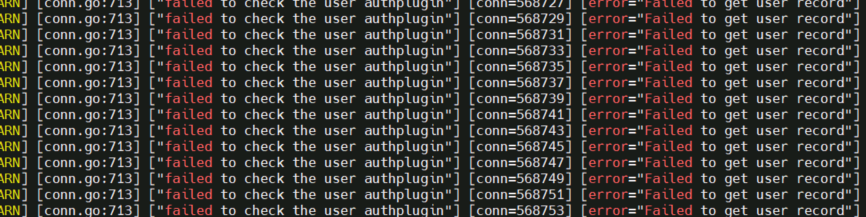
这边都检查过~没有发现过异常  不过tidb.log里有这些错误。
不过tidb.log里有这些错误。
Kongdom
(Kongdom)
9
 有位遇到类似的同学,但是直接升级解决,没有找到最终问题。
有位遇到类似的同学,但是直接升级解决,没有找到最终问题。
JOJO_DB
(Ti D Ber Bp09o D Co)
10
这个时间段没人操作、不是人为执行的。而且上面除了监控其他啥都没了。
JOJO_DB
(Ti D Ber Bp09o D Co)
11
谢谢~我看了下这个帖子。感觉是非常的像。看来也只能升级了。
Kongdom
(Kongdom)
12
出现这个问题之前,服务器配置上有调整么?感觉不应该无缘无故就出现问题。
lemonade010
(Ti D Ber Sd Dr Zqk O)
16
我记得Oracle 好像有一个这样的问题,改一下系统参数,