近期在使用tidb 时遇到的一些小问题的梳理总结,大部分版本都在6.5.6和7.5.2
1、limit 导致的扫描量过大的优化
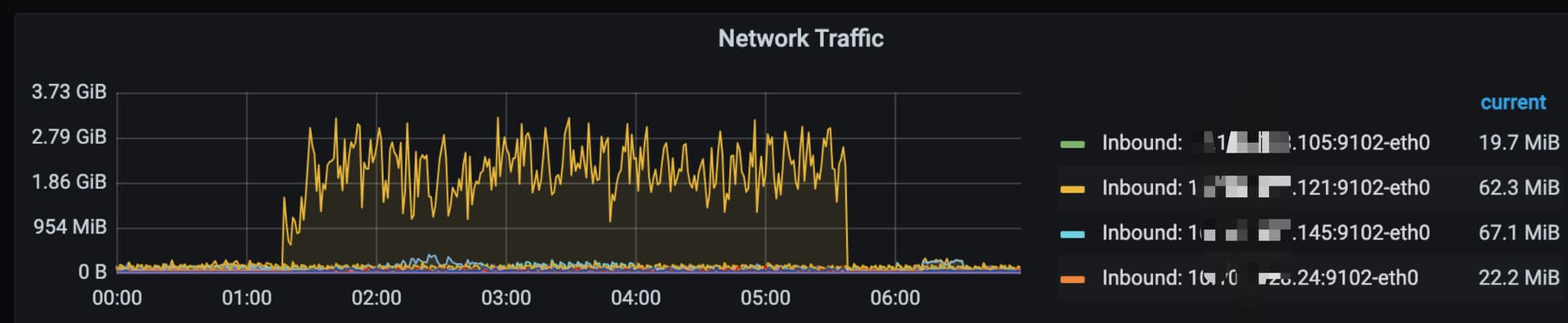
研发定时任务每天需要扫描大量数据,到时机器网卡被打满,严重影响集群性能。
这个sql 的主要问题在于:
a. ha3data 是text 字段 b. 虽然是limit 1000 但是实际上扫描的量远超过1000 条
SELECT utime, ha3Data FROM tblAdxxxx WHERE utime <= 1718804236 AND utime >= 1
AND (deleted = 0) ORDER BY utime DESC LIMIT 1000

解决办法:
1、将utime 时间范围缩短,但是研发人员认为修改成本高
2、修改tidb_opt_limit_push_down_threshold 的值大于1000
第二种方法官方老师推荐不要直接修改优化器的参数,可能会遇到未知问题,影响其他sql ,建议在语句里加hint
SELECT /*+ SET_VAR(tidb_opt_limit_push_down_threshold=2000) */ utime, ha3Data FROM
修改之后,网卡使用立即下降
2、为表增加ttl 属性自动删除过期数据导致的raft cpu 飙高
我们使用7.5.2 版本的主要初衷是使用自动过期,可以让研发不用手动清理数据,但是在使用的时候注意两点
a. 尽量在业务低峰时段进行ttl 的操作(通过参数设置) b. 调小ttl 相关的参数
MySQL [(none)]> show variables like '%ttl%';
+-----------------------------------------+-------------+
| Variable_name | Value |
+-----------------------------------------+-------------+
| tidb_ttl_delete_batch_size | 100 |
| tidb_ttl_delete_rate_limit | 0 |
| tidb_ttl_delete_worker_count | 2 |
| tidb_ttl_job_enable | ON |
| tidb_ttl_job_schedule_window_end_time | 07:23 +0800 |
| tidb_ttl_job_schedule_window_start_time | 23:11 +0800 |
| tidb_ttl_running_tasks | -1 |
| tidb_ttl_scan_batch_size | 300 |
| tidb_ttl_scan_worker_count | 2 |
+-----------------------------------------+-------------+

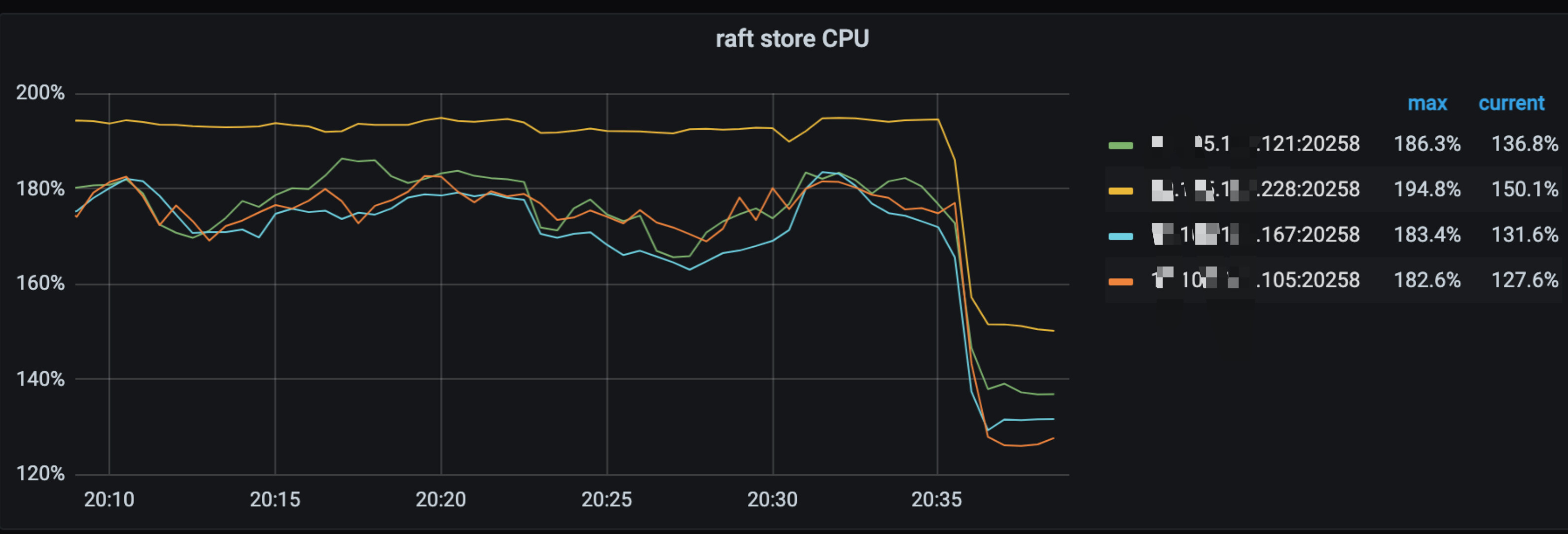
从tikv-details 的grpc 监控中可以看到有大量的ttl qps, 将ttl 的运行时间调整成半夜时间范围后,raft cpu 使用率明显下降
3、表的自增id 连续性问题的
业务反馈表的自增id 不够连续,每次都是增加2 个步长,研发人员担心涨的过快超过下游业务消费时出现类型溢出的问题,想要实现mysql 那样的连续递增
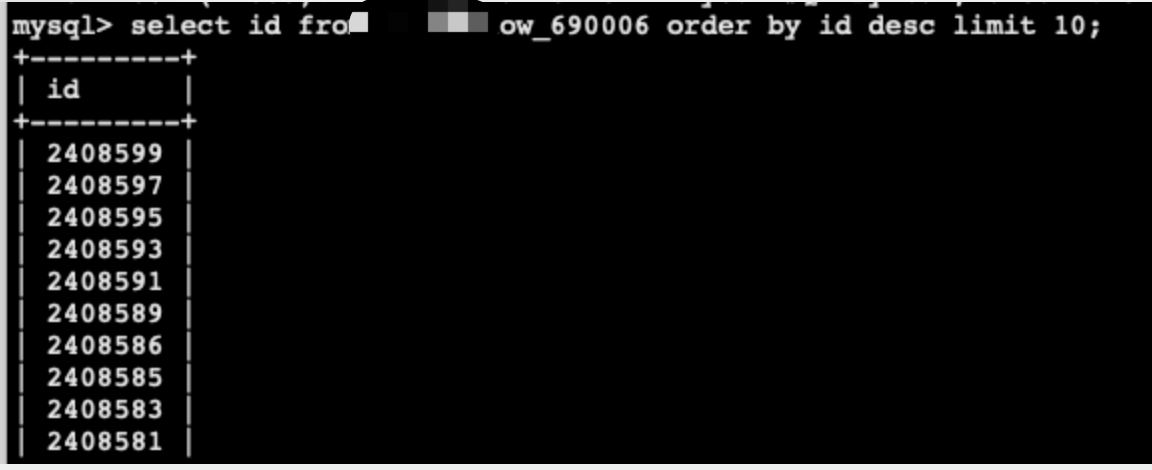
解决办法:为表增加AUTO_CACHE_ID
注意:据社区小伙伴反馈,7.5.1 这个属性有bug ,并且7.5.1 还有cdc 相关的配置不兼容6.5.x 的bug,
需要升级到7.5.2 之后, 但是7.5.2 发现了在fast-ddl 模式下增加索引卡住的情况
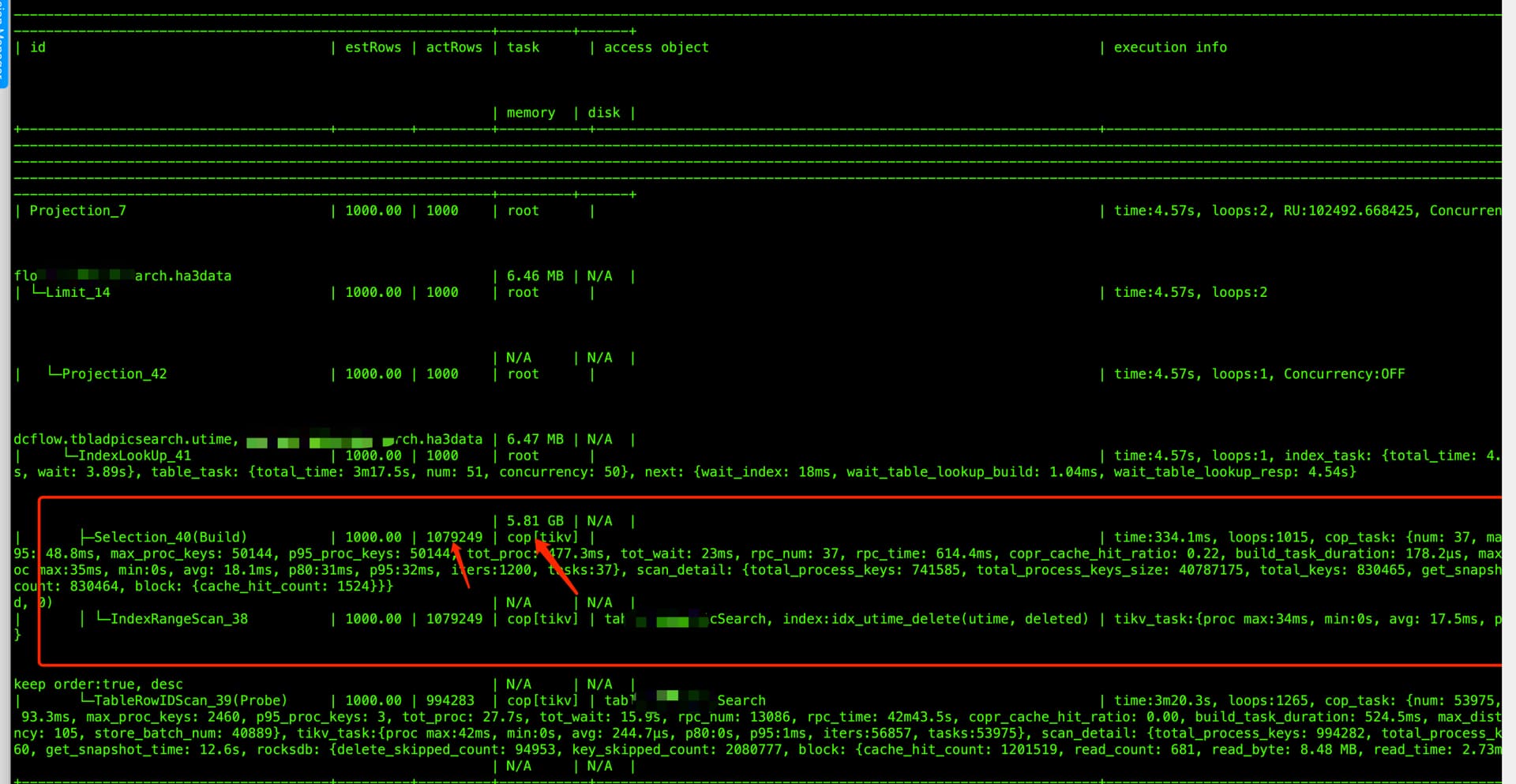
4、频繁删除数据导致越来越慢的问题
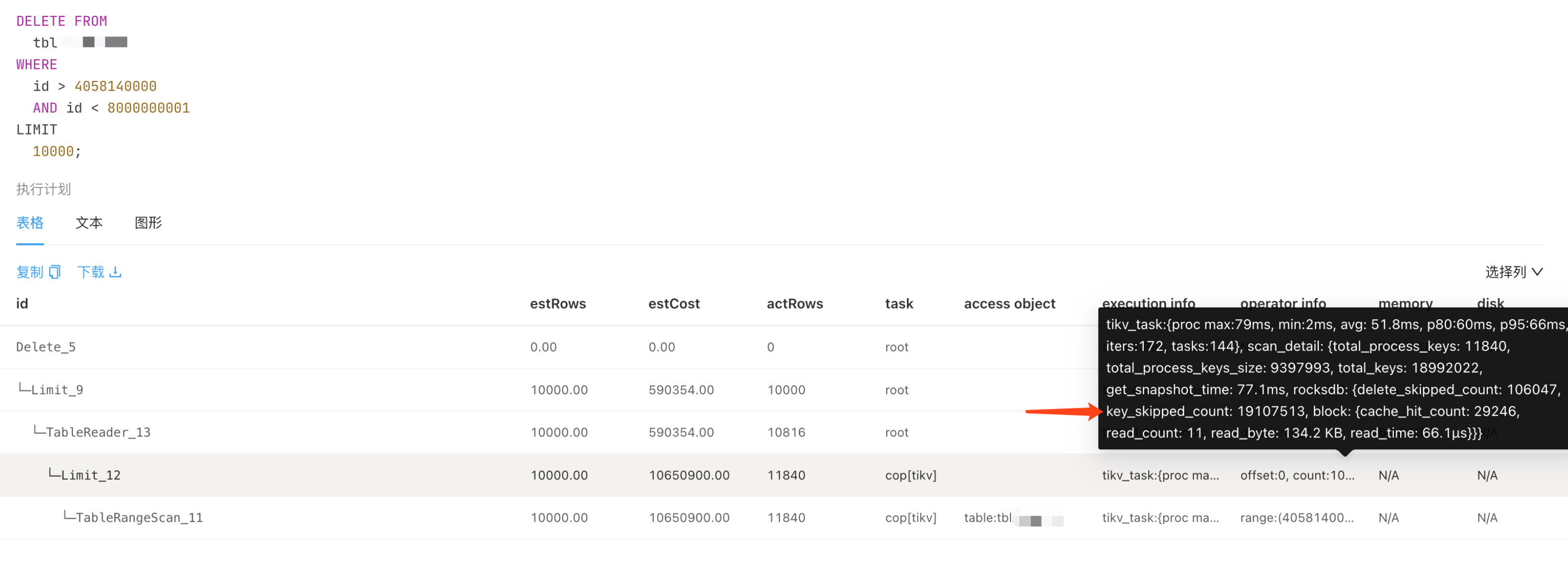
问题原因: 在删除数据后有大量的过期版本,但是rocksdb compact 不够及时,导致后续删除的时候会扫描大量的过期版本而越来越慢,key_skipped_count 会特别大
解决办法:
1、删除的时候尽量控制条件的范围比如使用id 或者时间字段做小范围的限制
2、等待8.x 版本的新功能每天增量compact