【遇到的问题:问题现象及影响】


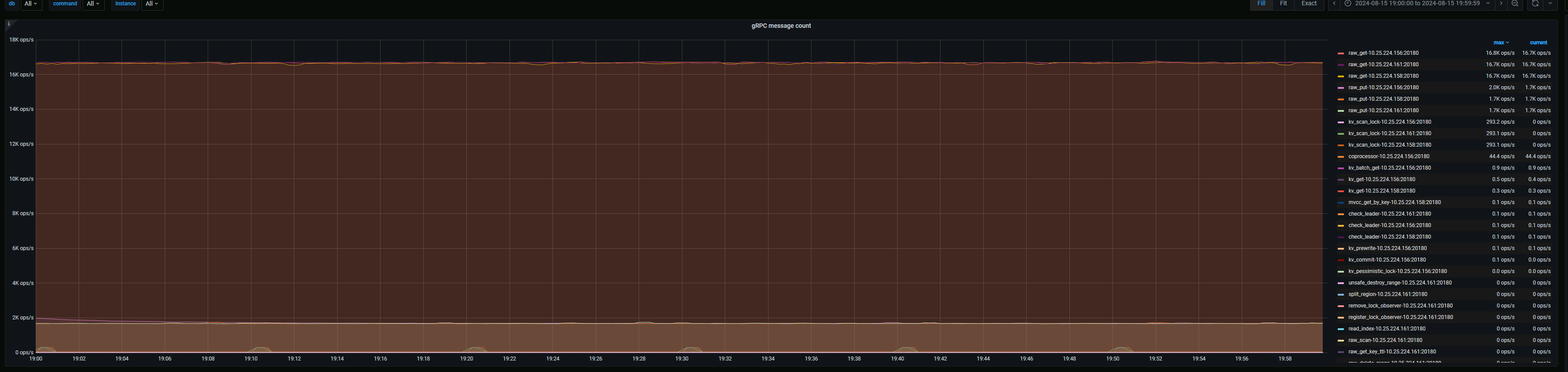


这个就是说明打到这个机器上的请求多呗,也就意味着有热点。
看看region的调度算法中 balance-hot-region-scheduler 开没开。
下面那个图 不能表示打到3台机器请求量差不多?
1.首先确认下每台机器的资源配置是否相同;
2.然后可以到tikv的面板里看看leader和region的数据分布是否均衡;
3.其次再去确认下是否每个tikv节点的其他资源如IO、内存的使用情况是否有类似的现象,如果是大概率有热点问题。
4.另外也可以到Dashboard热力图看看集群访问情况。
根据排查到的情况再制定下一步计划。
看看是不是有写偏斜
两张图的时间段不一样
选一样的看看
另外 gRPC message count 的 prom sql 改了吗。默认应该是 group by type
贴一下 prom sql
1 个赞
按类型也看看,楼上说的也对,时间也不匹配。
不太确认是否有人改了
sum(rate(tikv_raftstore_message_recv_by_store{k8s_cluster=“$k8s_cluster”, tidb_cluster=“$tidb_cluster”, instance=~“$instance”}[1m])) by (instance, store)
时间点已对齐
type类型的图截了
1.机器资源配置一致
2.leader和region分布均匀
3.内存使用基本一致 我暂时认为不是热点问题
看请求数目差不多,确实比较奇怪。grpc还包括tikv之间的raft通讯,在上面按类型的里面体现不出来。
你看看raft相关的图,有没有这台机器明显高的地方。
另外就是log一下看看,这个机器有没有在大量的输出什么日志。别的我暂时想不到什么了。
1 个赞
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
看一下,你们是不是混布了

混合部署的,好像很容易出现着这种问题
请把 gRPC 和 Thread CPU 两个 panel 的其他监控都提供一下
或者用 clinic 把所有指标都采集一下。参考 【SOP 系列 22】TiDB 集群诊断信息收集 Clinic 使用指南&资料大全
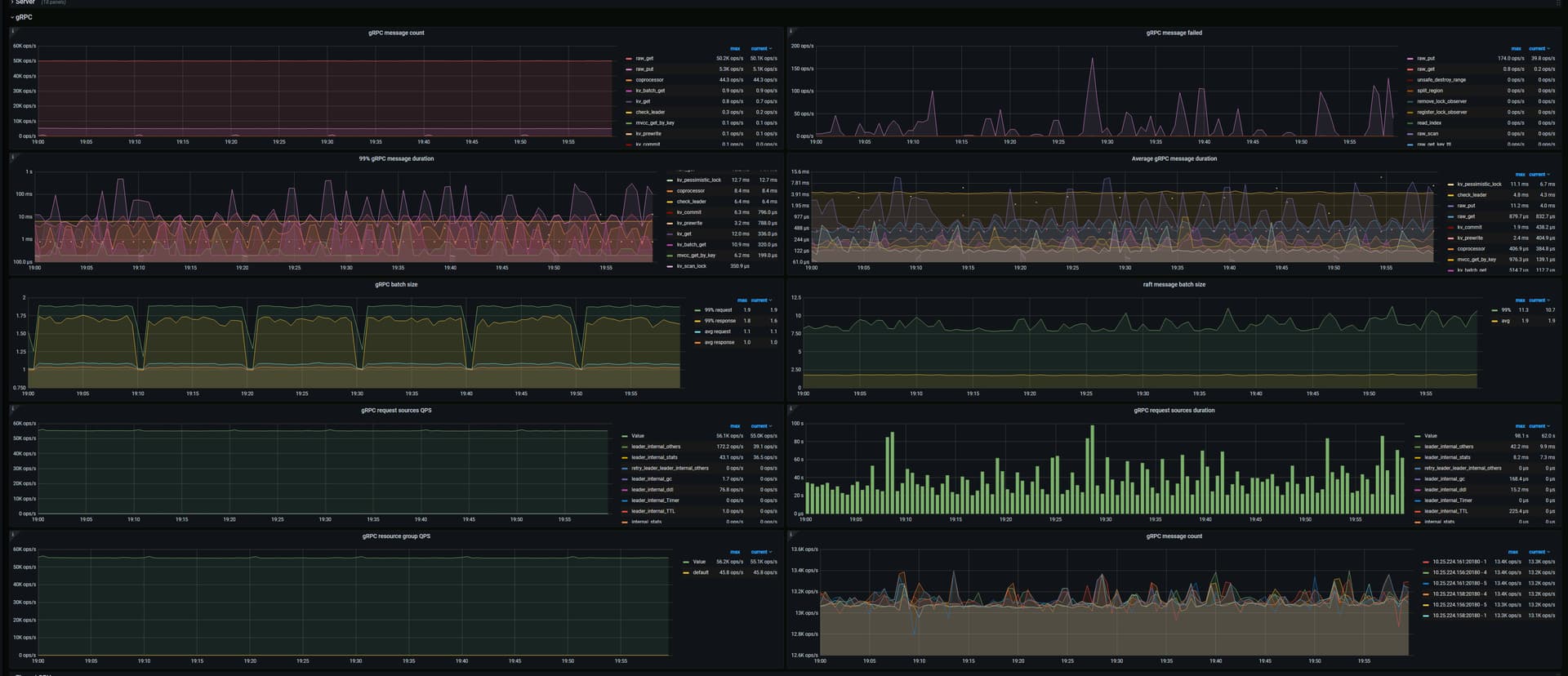
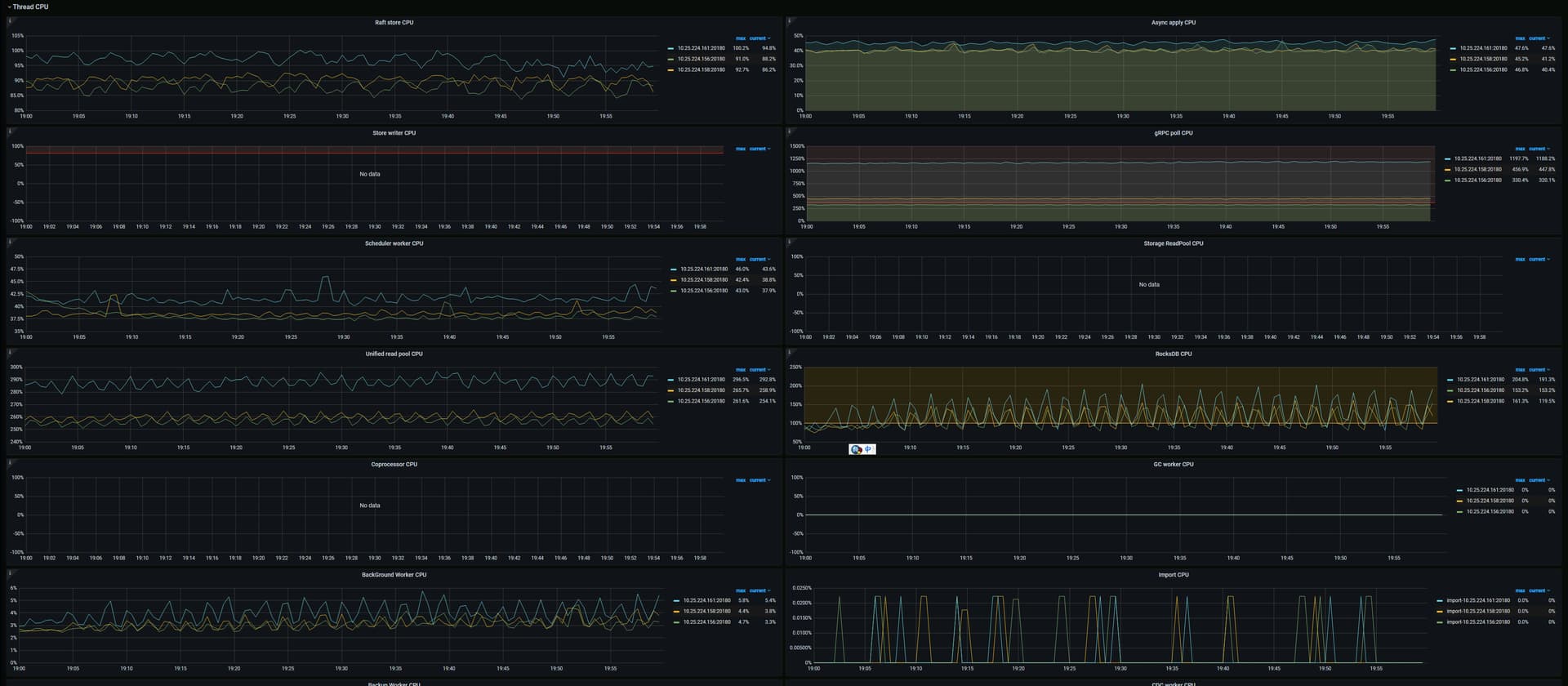
是不是有热点,通过dashboard看看比较明显。
你这个混布的话,即使每台上面一个tidb\pd\tikv,但是pd只有1个干活,所以相当于2台压力小的,1台压力大的。这个cpu统计是不是能精确统计到实际使用量我不确定。
161的各方面都比较高一些。还是优先看看dashboard吧,实在不行,降低下161的region权重。让他少干点活。
https://docs.pingcap.com/zh/tidb/v7.1/pd-control#设置-store-weight
- 我主要用的是tikv不是tidb,,客户端打点来看3台机也是比较均衡请求的。
- 161不是leader, pd的压力在158上
分别取一下 3 个节点的cpu profile吧。dashboard上有入口