【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1
【复现路径】执行一些大表的增删改查大sql
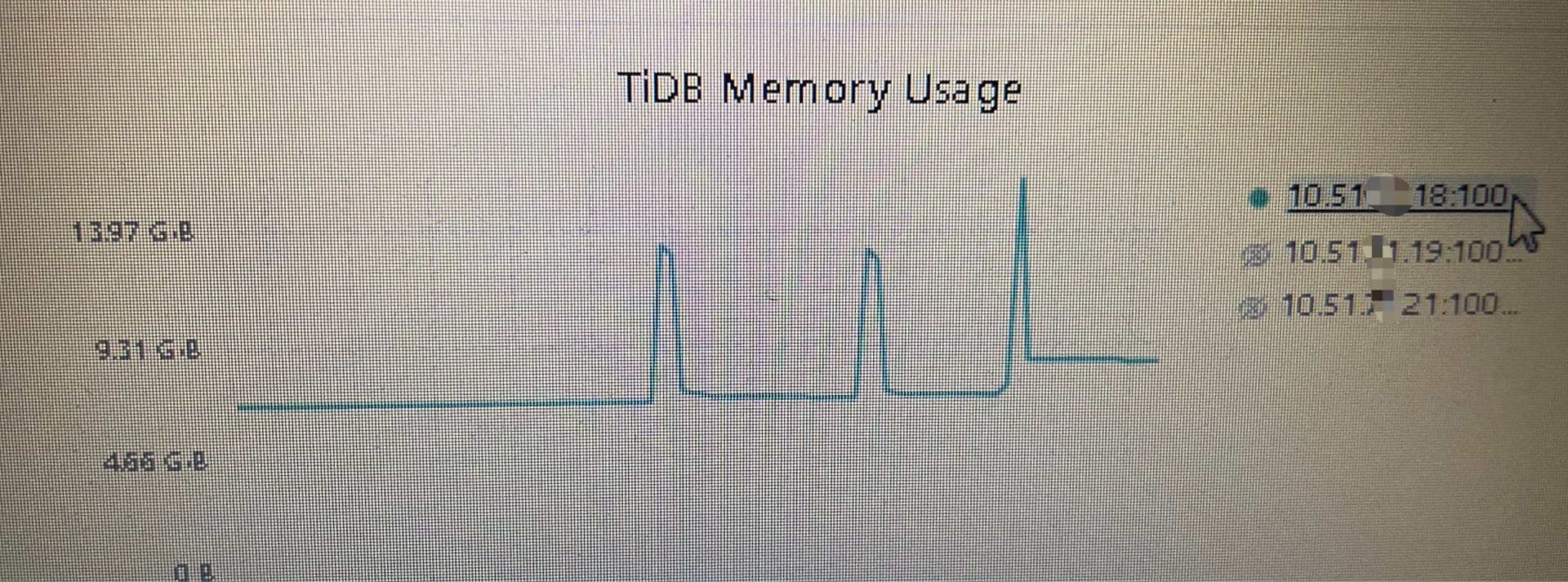
【遇到的问题:问题现象及影响】执行一些大的sql后内存会慢慢上升,虽然每次执行完sql有回收,但是整体呈现上涨趋势,比如原来只用两个G,大SQL查增大四个G,回收后会在2G+,然后没有任何脚本执行、甚至没有任何连接的时候会然后一直2G+。升到邻近阈值,最后导致其他sql执行不了,提示:查询使用内存超过tidb-server的内存。直到服务重启后才能正常。
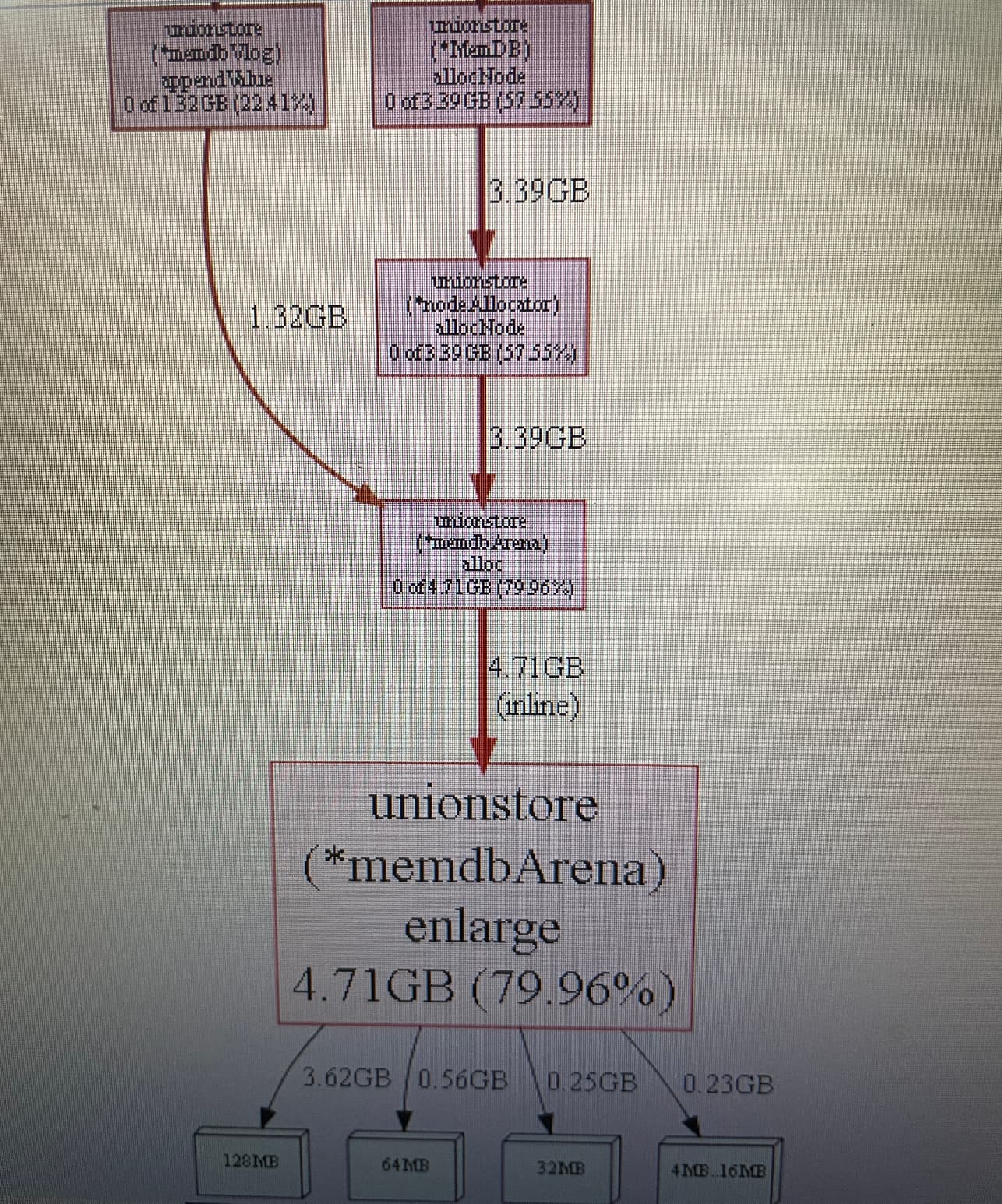
请问堆内存关系图里的unionstore是存的什么?占了79% 是否有办法清除掉?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
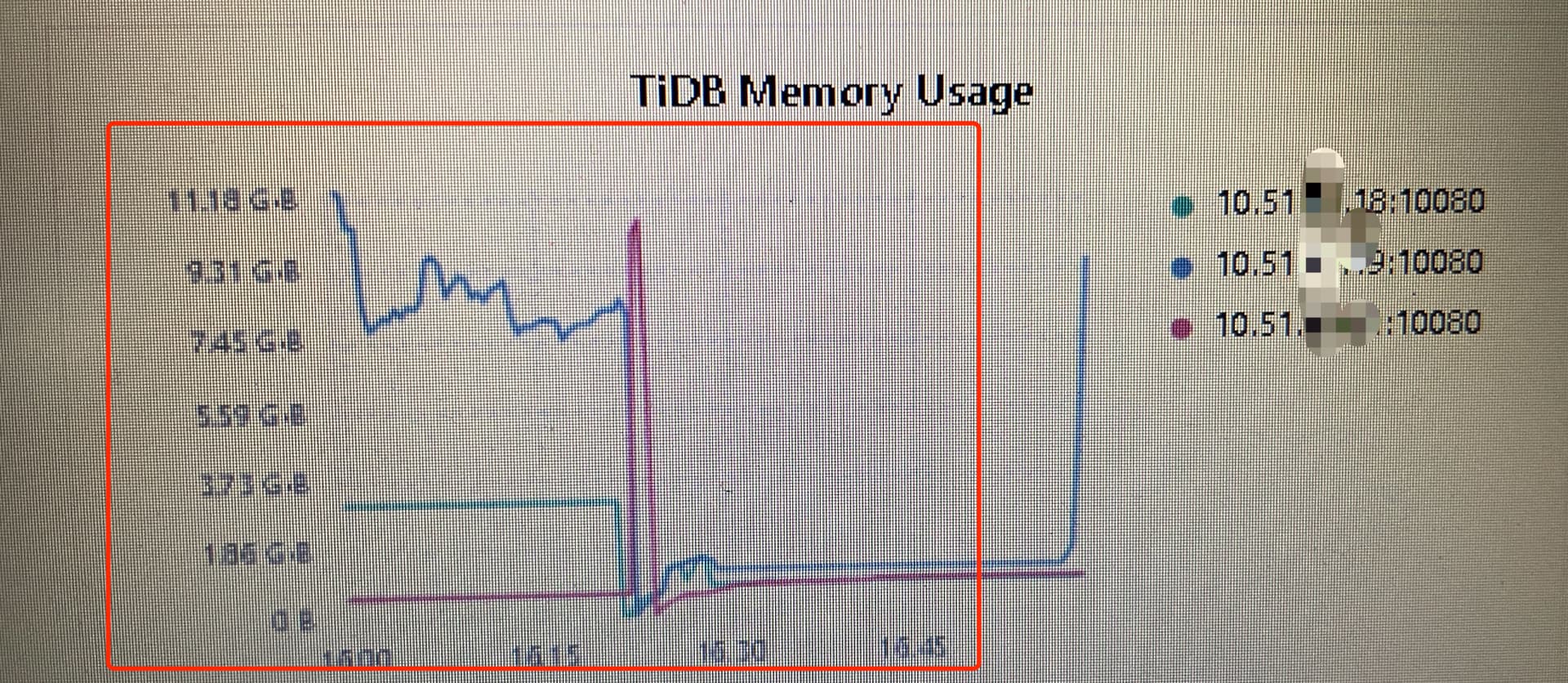
下图是12小时内的测试情况,基本上跑一个星期就能占到20个G.
到今天这玩意已经占到80%了
大SQL有分析过其执行计划吗?特别是大的DML SQL
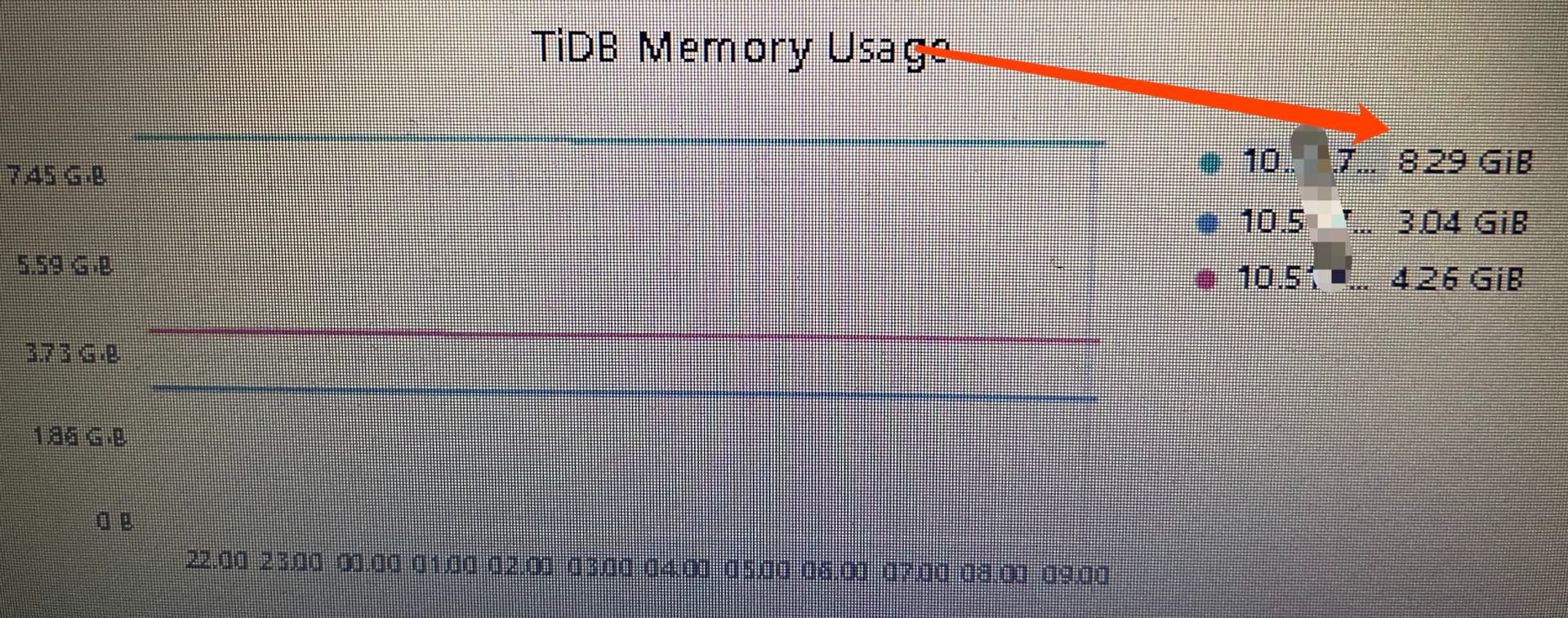
到今天已经升到8点多G了。啥都没干。连接都没有。什么情况?unionstore有没有办法清掉?非要重启服务吗?
这个图拍摄向右倾斜了,其实它是呈往上涨趋势
jhm633
(Jhm633)
8
您好,麻烦再跑一次出问题的 sql,同时收集一下使用 clinic 收集一下监控和 log 信息,然后再收集一下 heap profile,我们分析一下,谢谢。
柴米油酱
(Ti D Ber R Qstj35v)
9
内存本身就是加速缓存。 要查看具体内存使用情况,你可以查询系统表INFORMATION_SCHEMA.MEMORY_USAGE或者CLUSTER_MEMORY_USAGE
WalterWj
(王军 - PingCAP)
10
好的。这个unionstore。在没有任何连接、任务,不重启的情况下能不能有办法清除掉。
你好!感谢支撑协助。
刚才又测了一遍。但这次它回收了。
需求:我们对三四张有大几千万的数据表。做查询、计算、删除、插入\更新的动作。
这次改造了sql有(具体不知哪个生效):
1、删除几千万数据的语句从delete改为truncate
2、全量抽取改为分批次抽取
3、大范围更新分为小批量更新
8g的内存的确太小了。
1、删除几千万数据的语句从delete改为truncate
这个是有效果的 delete走事务。 truncate不走事务
system
(system)
关闭
14
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。