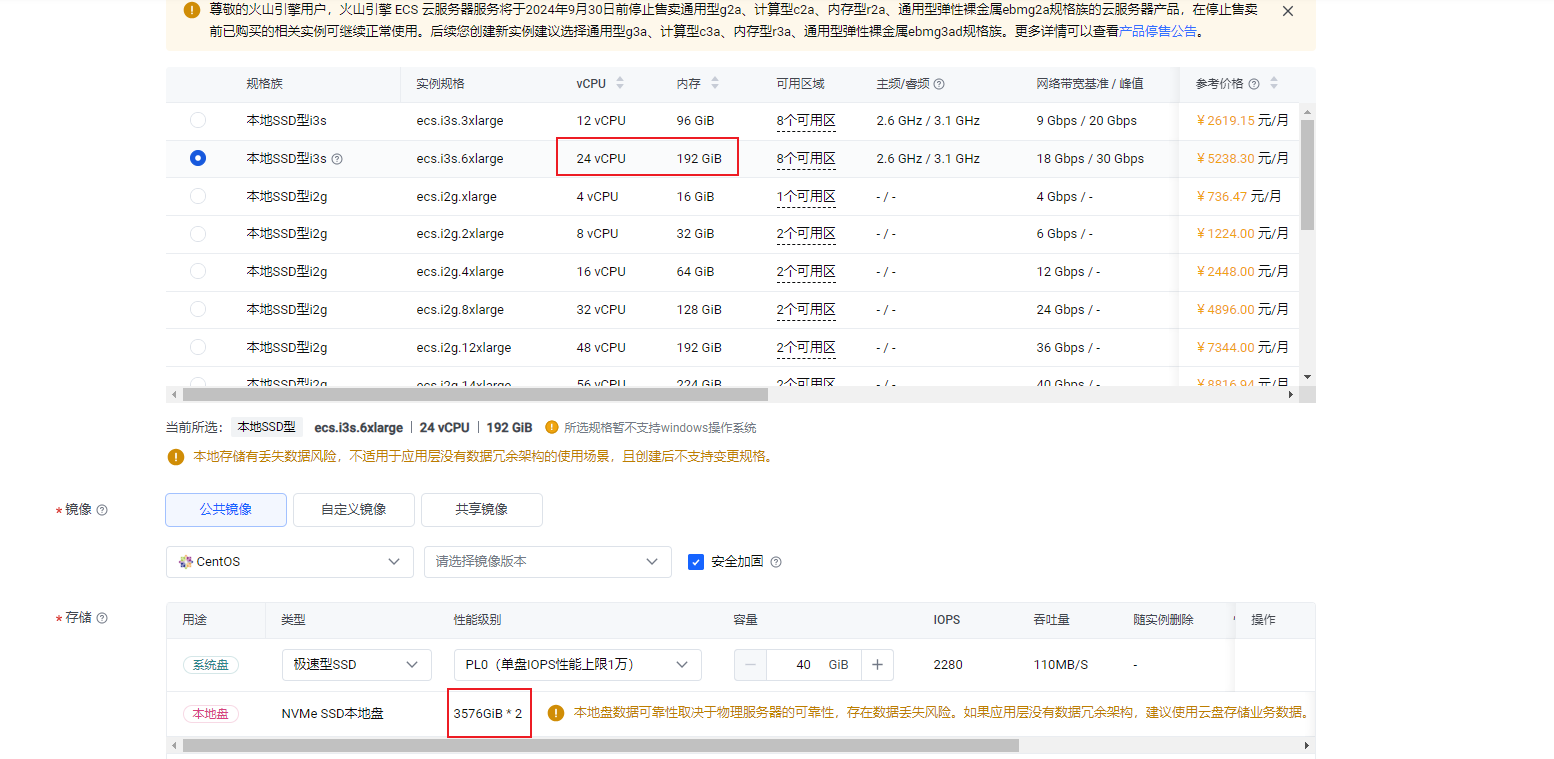
如图,某云服务商本地ssd机器的配置,我是不太理解这些机器配置的比例搭配,感觉离谱。我理想中至少要16C+ 配一个的单盘是比较均衡搭配,实际好多16C起步的都上2个磁盘了。多盘搭建多个tikv实例,CPU和内存又跟不上。
最低配置都是12c 96G + 单盘独立nvme ssd
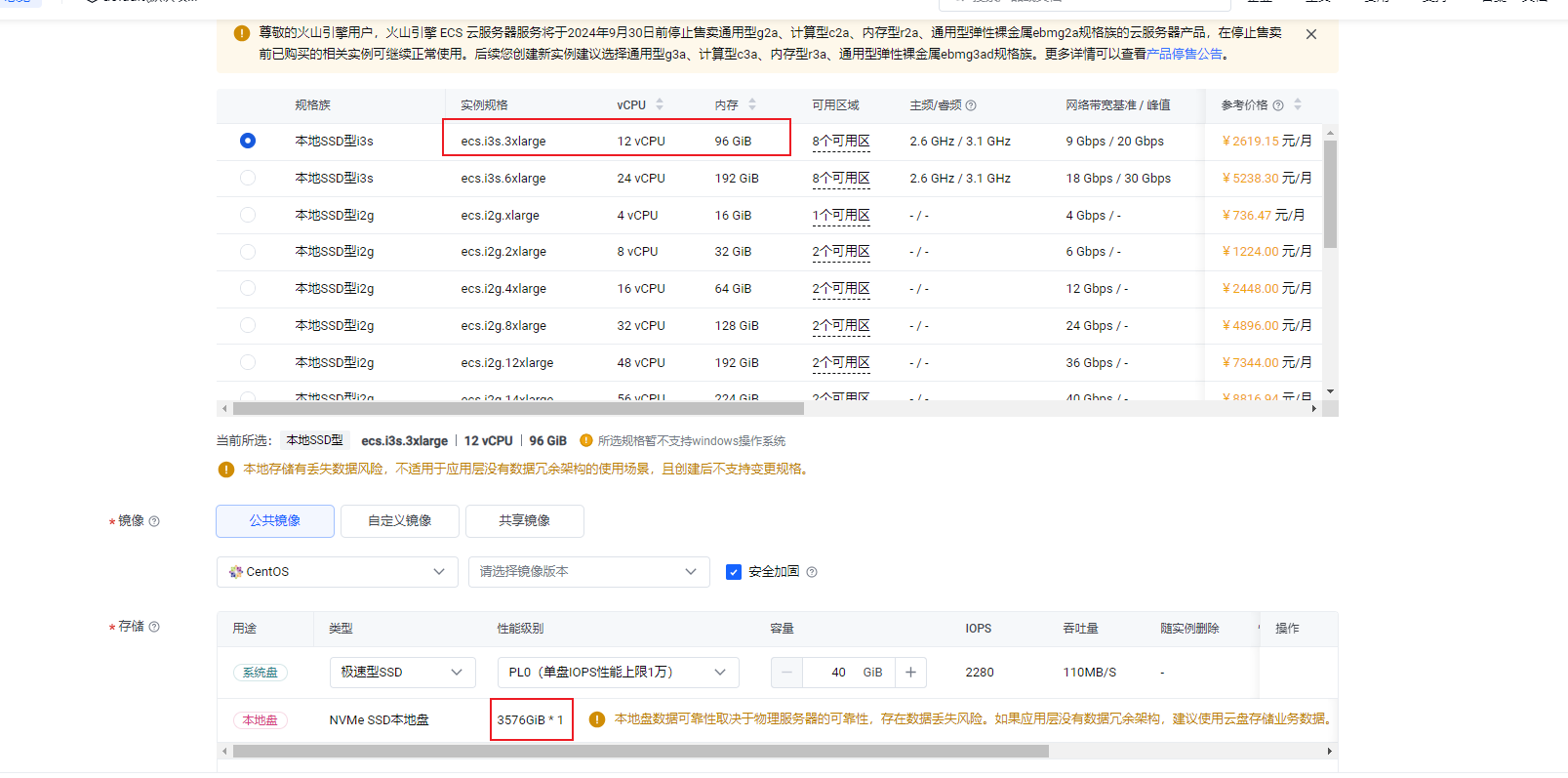
kv节点建议买16C64g内存单块磁盘的服务器,多个kv多买几台服务器。
这种多块磁盘的服务器内存cpu分配麻烦,还要给单台服务器打标签做副本绑定规则。
“16Vcore 部署一个 实例”,这个说的是 tikv 实例,实际很难严格遵守。建议部署时先贴近这个选择类型,然后再参考业务压测的结果,再调整资源使用。
一般多盘部署是因为使用物理机部署,物理机一般配置都比较高,只安装一个tikv比较浪费资源所有会多盘部署多个kv,既然都上云主机了那不如分开部署
本地ssd没这个配置,最低配置都是12c 96G + 单盘独立nvme ssd ![]()
多盘多kv,按照上面那些CPU和内存搭配,感觉不均衡

我写一下文章吧稍等
群里有网友问到多个本地磁盘该如何配置
打开tikv选项
block-cache-size = “1GB”
storage.block-cache.capacity=1GB
比如机器内存是16g
你部署2个tikv
那你系统配置里单个tikv占用的内存就需要设置为1g 具体参数需要你自己调整。不同的磁盘性能会占用不通的磁盘内存。这个不是硬限制。
tikv默认还有其他占用。
还有内存被系统磁盘缓存所用。
--------------------------
global:
user: “tidb”
ssh_port: 22
deploy_dir: “/tidb-deploy”
data_dir: “/tidb-data”
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
instance.tidb_slow_log_threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: [“host”]
tiflash:
logger.level: “info”
pd_servers:
- host: 10.0.1.1
tidb_servers:
- host: 10.0.1.1
tikv_servers:
- host: 10.0.1.1
port: 20160
status_port: 201
deploy_dir: “/tidb-deploy1”
data_dir: “/tidb-data1”
- host: 10.0.1.1
port: 20161
status_port: 20181
deploy_dir: “/tidb-deploy2”
data_dir: “/tidb-data2”
- host: 10.0.1.2
port: 20160
status_port: 201
deploy_dir: “/tidb-deploy1”
data_dir: “/tidb-data1”
- host: 10.0.1.2
port: 20161
status_port: 20181
deploy_dir: “/tidb-deploy2”
data_dir: “/tidb-data2”
- host: 10.0.1.3
port: 20160
status_port: 201
deploy_dir: “/tidb-deploy1”
data_dir: “/tidb-data1”
- host: 10.0.1.3
port: 20161
status_port: 20181
deploy_dir: “/tidb-deploy2”
data_dir: “/tidb-data2”
tiflash_servers:
- host: 10.0.1.1
monitoring_servers:
- host: 10.0.1.1
grafana_servers:
- host: 10.0.1.1
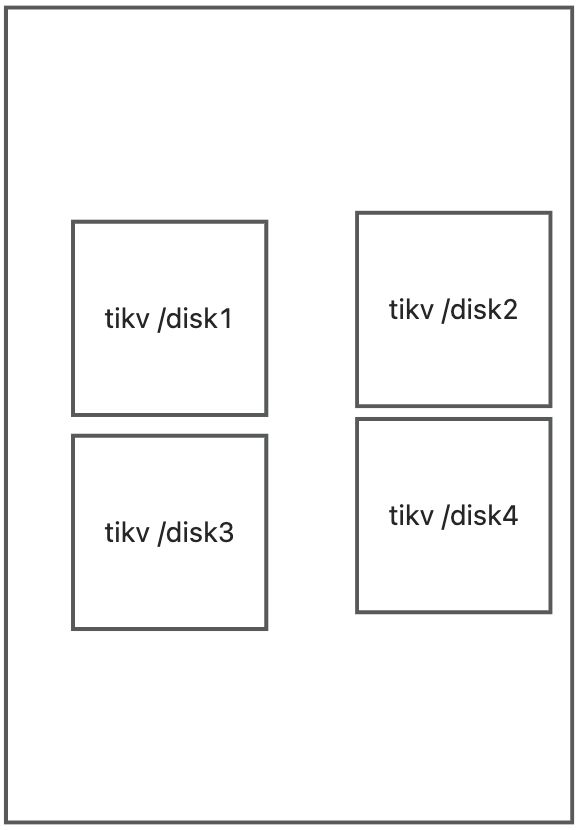
你把本地磁盘1挂载在/tidb-data1
你把本地磁盘2挂载在/tidb-data2
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。