【 TiDB 使用环境】测试
【 TiDB 版本】
【复现路径】销毁集群重建
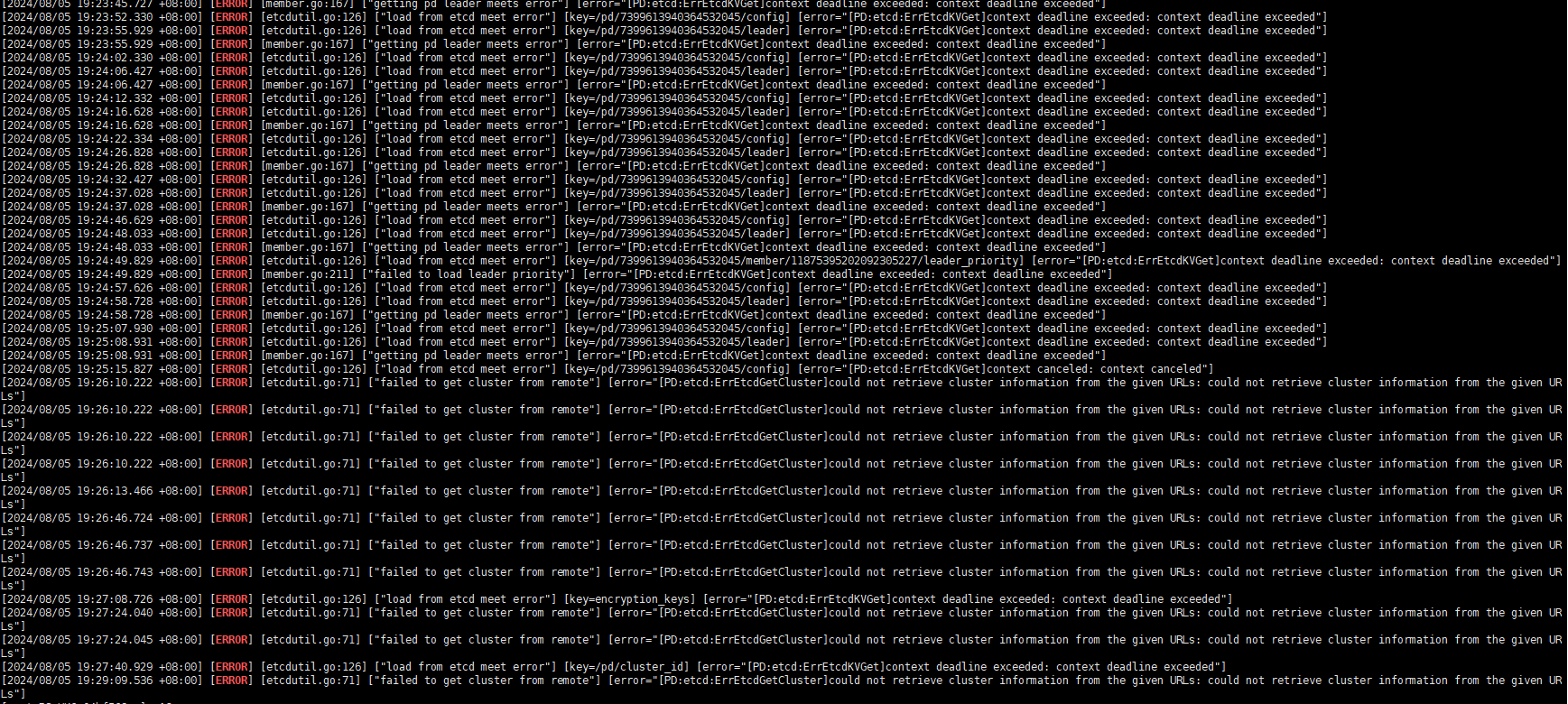
【遇到的问题:问题现象及影响】重建后进程无法启动,有报错,信息如下
[2024/08/05 19:36:49.829 +08:00] [WARN] [raft.go:440] [“leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk”] [to=d67d3fd3190b0ca2] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=699.085802ms]
[2024/08/05 19:36:49.829 +08:00] [WARN] [raft.go:440] [“leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk”] [to=36ce6c0c109af23c] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=699.082896ms]
[2024/08/05 19:36:49.829 +08:00] [WARN] [raft.go:440] [“leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk”] [to=1c74c6905f2178a2] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=699.095266ms]
会不会是磁盘问题导致的呢?
把所有的操作步骤也发下?以及tidb的集群版本也发下?
磁盘太慢?参照官方文档,做个fio测速看看呢
什么环境啊,拓扑发一下,原集群是通过 tiup cluster destroy销毁的不?
主要看下pd的日志,如果pd没起来其他起不来的
空集群的话,再重新销毁重建下,销毁的时候保证目录都清空了
空目录吗?
把所有的目录都删除,还有/etc/systemd/system下面的tidb相关的service文件删除;
在重新创建集群。