【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
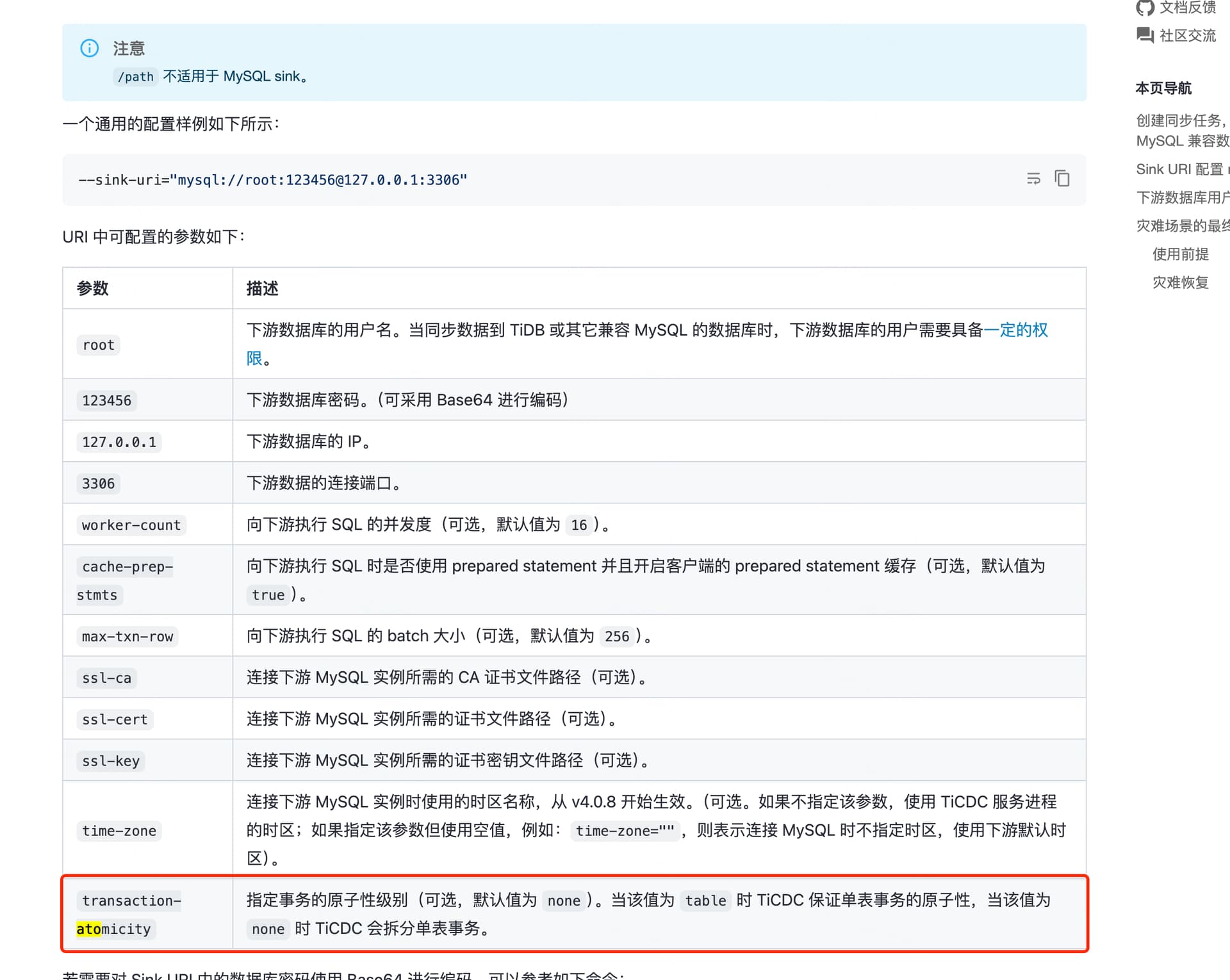
生产环境开始逐步升级到 v7.1.5 ,之前版本都是使用 Drainer 在向下游同步数据,之前遇到业务在一个事务中大批量写入的时候,导致下游 kafka topic oom 报错的情况,查看日志为一个消息150M+,现在想通过使用 cdc 来看看这类问题能不能有所缓解。
想问一下1. cdc 在确认大事务的情况下,有无拆分的相关逻辑。2.事务会有 begin 和 commit 标识吗