【 TiDB 使用环境】测试环境
【 TiDB 版本】v7.1.0。 operator版本为1.4.6
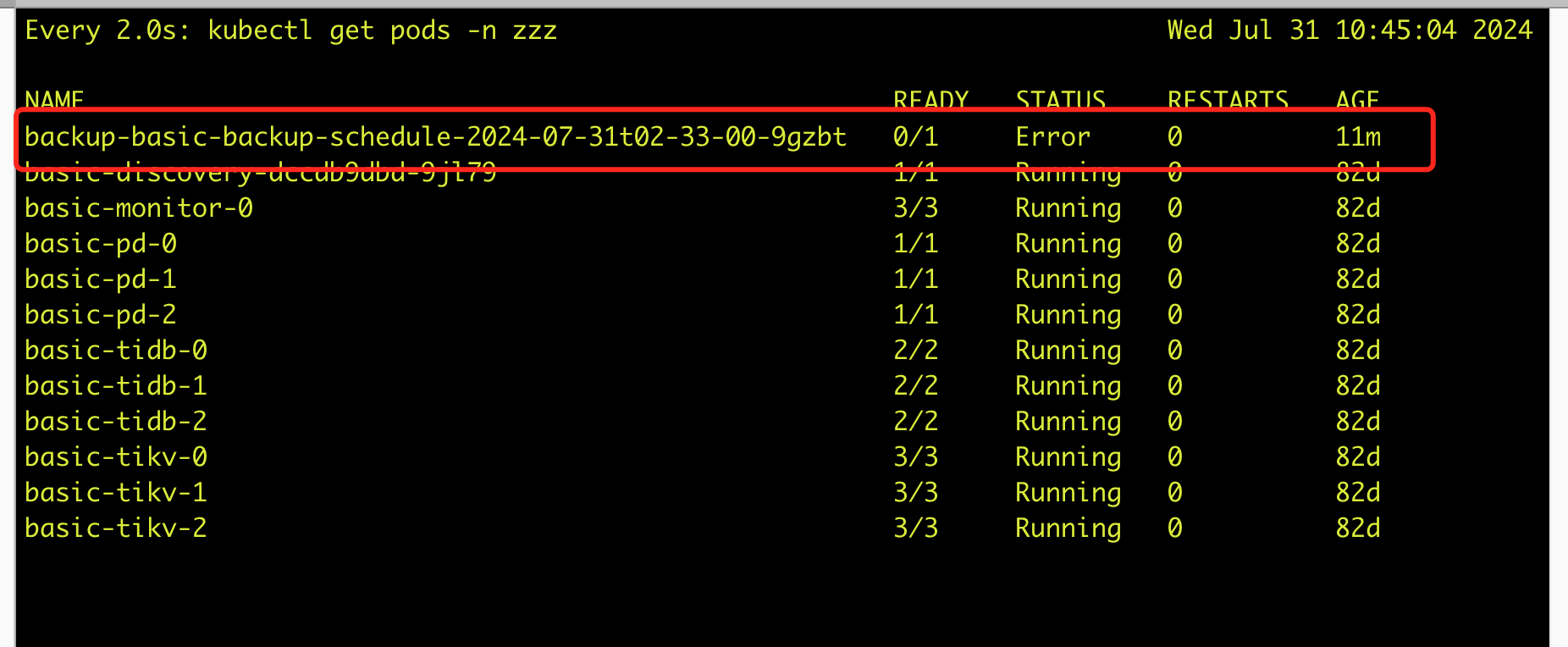
【复现路径】配置bks进行周期性备份,备份报错后没有进行重试
【遇到的问题:问题现象及影响】
1、根据bks的设置,在备份任务失败后的5min后应该再次发起备份,但实际运行中并没有再次备份
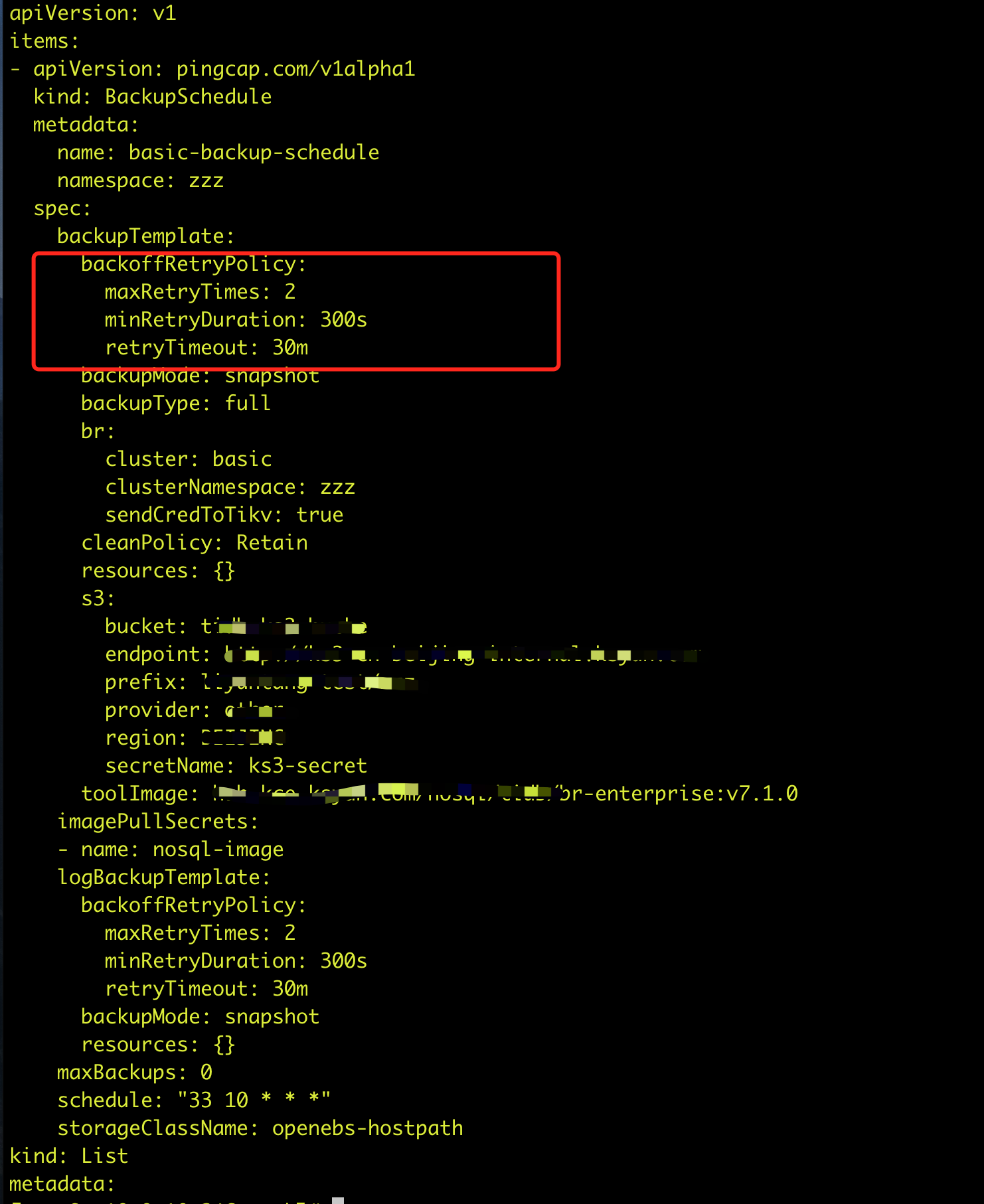
官方参数解释:

bks配置
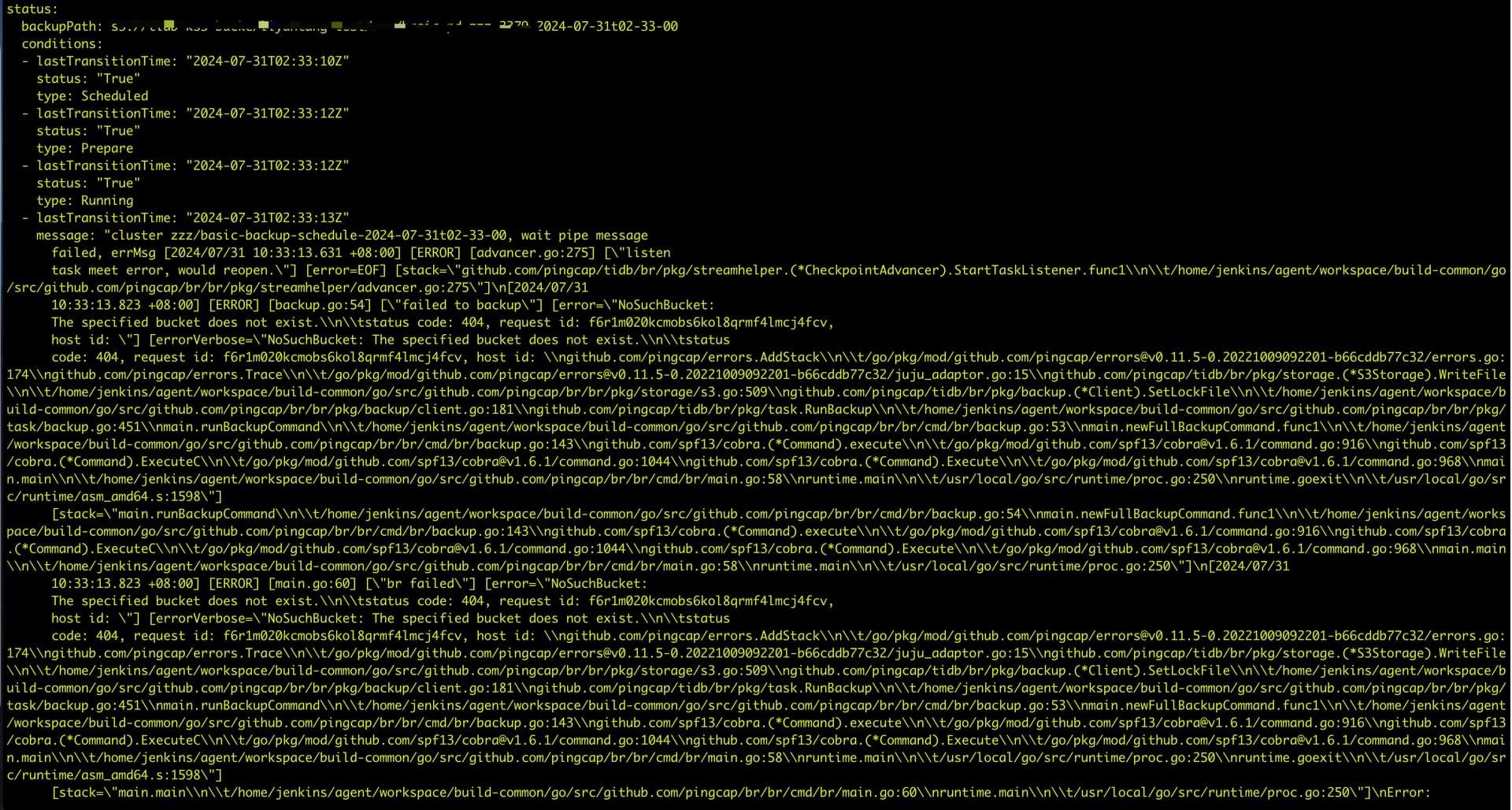
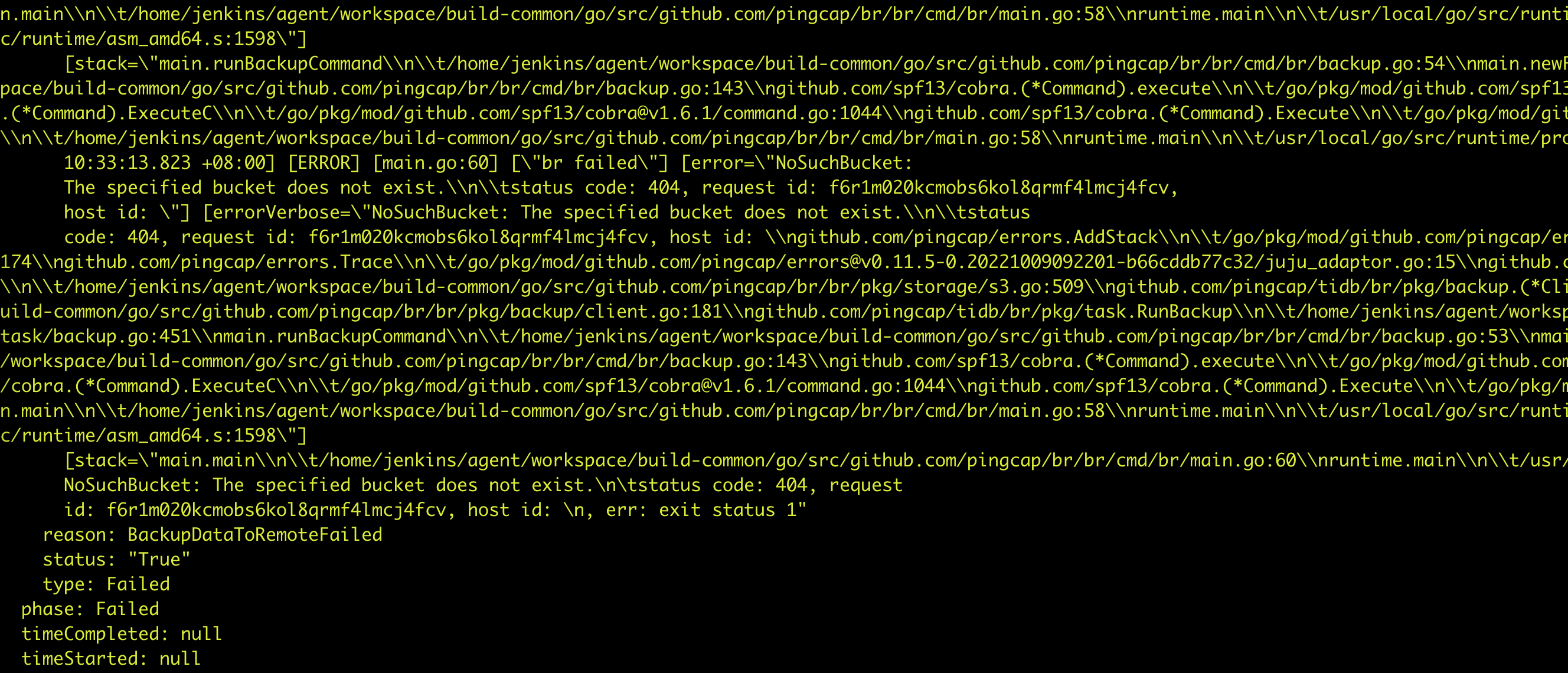
backup任务

报错的任务,此时距离备份报错已经11min了
【 TiDB 使用环境】测试环境
【 TiDB 版本】v7.1.0。 operator版本为1.4.6
【复现路径】配置bks进行周期性备份,备份报错后没有进行重试
【遇到的问题:问题现象及影响】
1、根据bks的设置,在备份任务失败后的5min后应该再次发起备份,但实际运行中并没有再次备份
官方参数解释:
bks配置
backup任务
报错的任务,此时距离备份报错已经11min了
还有这个工具呢。。。
这个问题需要具体分析了 k8s用的人比较少
operator版本1.4.6
我看了下operator的源码,retry这块好像没生效
operator版本 更新到最新版看看?
提供一下问题时间段 tidb-operator (controller-manager-xxxx) 的日志
这里是 v1.4.6 重试的逻辑 tidb-operator/pkg/controller/backup/backup_controller.go at v1.4.6 · pingcap/tidb-operator · GitHub ,可以照着代码去日志里搜关键词
W0731 10:33:10.187620 1 backup_schedule_manager.go:340] backup schedule zzz/basic-backup-schedule does not set backup gc policy
I0731 10:33:10.188280 1 event.go:282] Event(v1.ObjectReference{Kind:“Backup”, Namespace:“zzz”, Name:“basic-backup-schedule-2024-07-31t02-33-00”, UID:“3a918b16-529c-4e4b-857b-a07e76f932f5”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“249655598”, FieldPath:“”}): type: ‘Normal’ reason: ‘SuccessfulCreate’ create Backup zzz/basic-backup-schedule-2024-07-31t02-33-00 for backupSchedule/basic-backup-schedule successful
I0731 10:33:10.193676 1 backup_schedule_status_updater.go:61] BackupSchedule: [zzz/basic-backup-schedule] updated successfully
W0731 10:33:10.193756 1 backup_schedule_manager.go:340] backup schedule zzz/basic-backup-schedule does not set backup gc policy
I0731 10:33:10.193809 1 backup_schedule_controller.go:105] BackupSchedule: zzz/basic-backup-schedule, still need sync: backup schedule zzz/basic-backup-schedule, the last backup basic-backup-schedule-2024-07-31t02-33-00 is still running, requeuing
I0731 10:33:10.197416 1 event.go:282] Event(v1.ObjectReference{Kind:“Backup”, Namespace:“zzz”, Name:“basic-backup-schedule-2024-07-31t02-33-00”, UID:“3a918b16-529c-4e4b-857b-a07e76f932f5”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“249655598”, FieldPath:“”}): type: ‘Normal’ reason: ‘SuccessfulCreate’ create job zzz/backup-basic-backup-schedule-2024-07-31t02-33-00 for cluster basic-backup-schedule backup successful
I0731 10:33:10.205148 1 backup_status_updater.go:123] Backup: [zzz/basic-backup-schedule-2024-07-31t02-33-00] updated successfully
W0731 10:33:11.194986 1 backup_schedule_manager.go:340] backup schedule zzz/basic-backup-schedule does not set backup gc policy
I0731 10:33:11.195076 1 backup_schedule_controller.go:105] BackupSchedule: zzz/basic-backup-schedule, still need sync: backup schedule zzz/basic-backup-schedule, the last backup basic-backup-schedule-2024-07-31t02-33-00 is still running, requeuing
W0731 10:33:13.195967 1 backup_schedule_manager.go:340] backup schedule zzz/basic-backup-schedule does not set backup gc policy
I0731 10:33:13.196088 1 backup_schedule_controller.go:105] BackupSchedule: zzz/basic-backup-schedule, still need sync: backup schedule zzz/basic-backup-schedule, the last backup basic-backup-schedule-2024-07-31t02-33-00 is still running, requeuing
这才 3s 的日志,上面有代码逻辑,搜下关键词哇,比如 “exceed retry times” “exceed retry limit, failed reason“
日志中没有
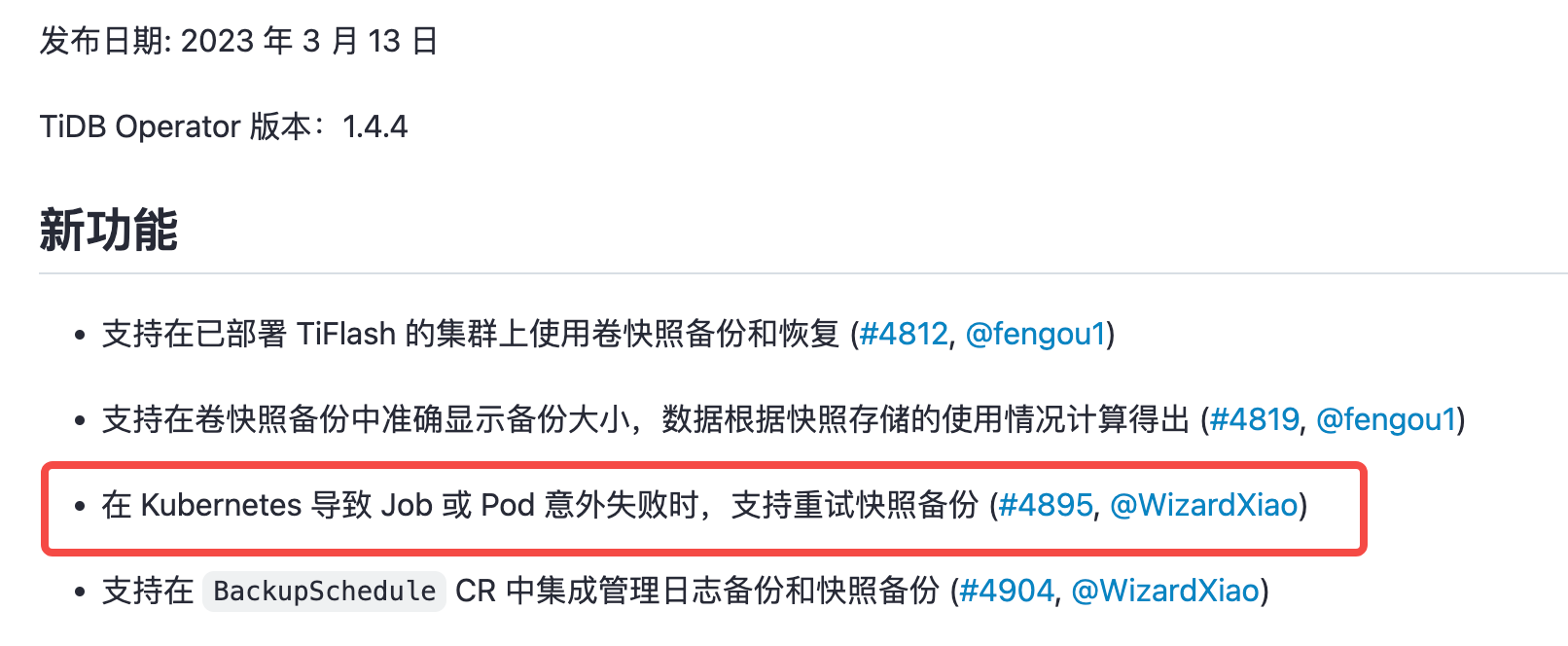
这个字段在 TiDB Operator v1.4.4 引入,只针对 job || pod failed 的 k8s 报错情况
相关文档 https://docs.pingcap.com/zh/tidb-in-kubernetes/stable/release-1.4.4
相关代码 tidb-operator/pkg/controller/backup/backup_controller.go at v1.4.6 · pingcap/tidb-operator · GitHub
重试的判断条件为 pod.Status.Phase: failed 或 job.status.conditions: failed
BR 备份/恢复 失败的情况下,重试的意义并不大
这个就很难区分了,其实从用户的角度讲,不论什么报错,都应该有重试过程的
k8s 属于期望调度,所以增加重试是合理的。 BR 涉及到备份/恢复的数据,举个🌰 当 BR restore 恢复数据到一半报错,此时找出并解决问题比单纯重试的意义会更大。
有些故障是不需要排查的,比如网络抖动、机器负载比较高、pod迁移,尤其是从对象存储推、拉数据的时候,网络连接断开是个很正常的现象