【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1.2
【遇到的问题:问题现象及影响】集群重启后,一台tikv从grafna上消失,但是tiup上依然可以看见
【附件:截图/日志/监控】
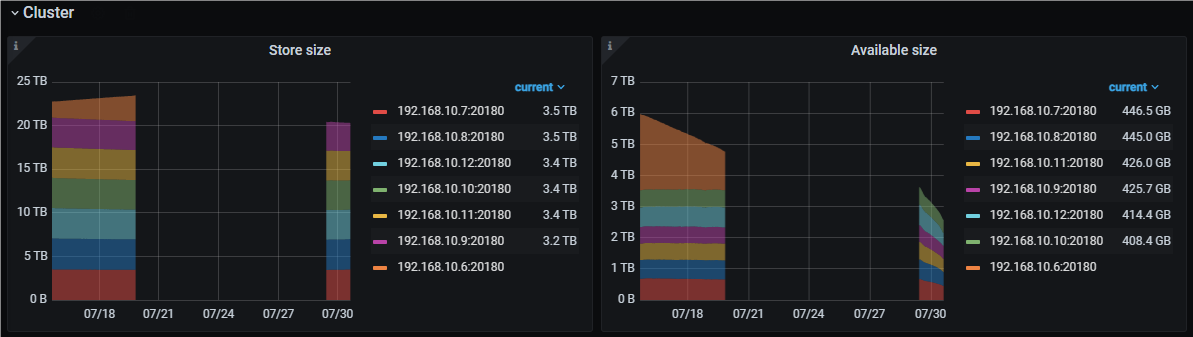
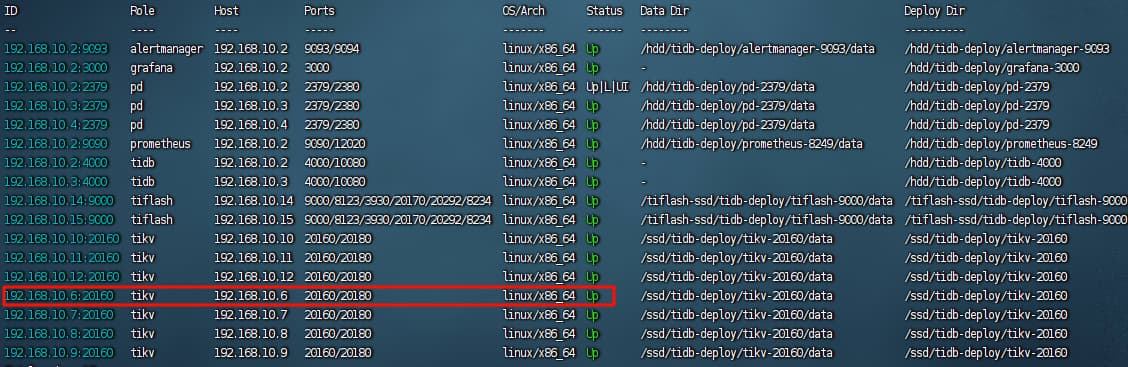
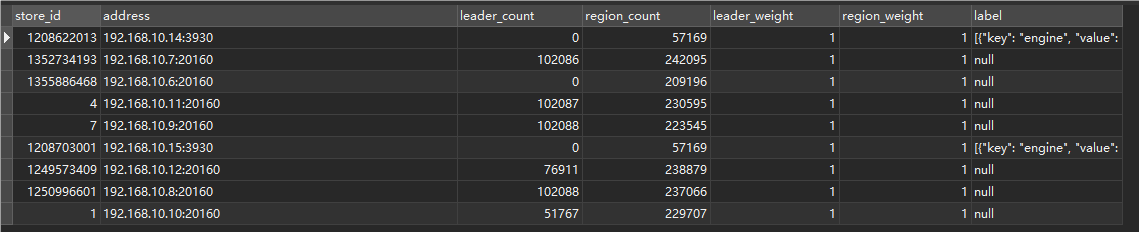
如图,192.168.10.6这台tikv是之前新扩容的,后由于机房空调故障所以服务器停了约有一周。再次启动后,从grafana上就看不到192.168.10.6了,但从tiup上还是能看见其状态为上线。除此之外,这个tikv结点的磁盘使用情况是占用空间在持续减少,可用空间在持续增加。
【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1.2
【遇到的问题:问题现象及影响】集群重启后,一台tikv从grafna上消失,但是tiup上依然可以看见
【附件:截图/日志/监控】
如图,192.168.10.6这台tikv是之前新扩容的,后由于机房空调故障所以服务器停了约有一周。再次启动后,从grafana上就看不到192.168.10.6了,但从tiup上还是能看见其状态为上线。除此之外,这个tikv结点的磁盘使用情况是占用空间在持续减少,可用空间在持续增加。
先看下这个tikv上有数据没 select store_id,address,leader_count,region_count,leader_weight,region_weight,lable from information_schemat.tikv_store_status;
pd-ctl scheduler show 看下调度
监控里看不到容量信息 试试reload下prometheus
登录pd,pd-ctl 看看是什么状态,这就是真正的在不在用了。
至于grafana上看不到,这不重要,grafana就是个监控而已。如果想通过pdctl看确实在用,再考虑修一下grafana
pdctl里面member看下,有的话,看下leader和region是不是在往其他节点迁移,是的话这个机器还是不正常,建议缩容扩容。
这个呢
pd-ctl 不太熟,是这么执行的吗?
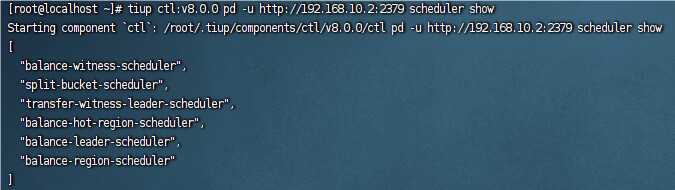
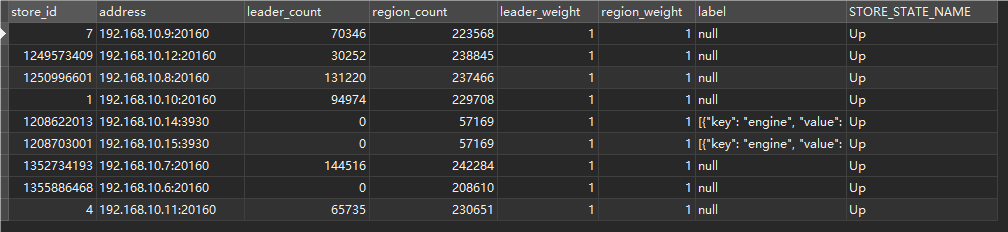
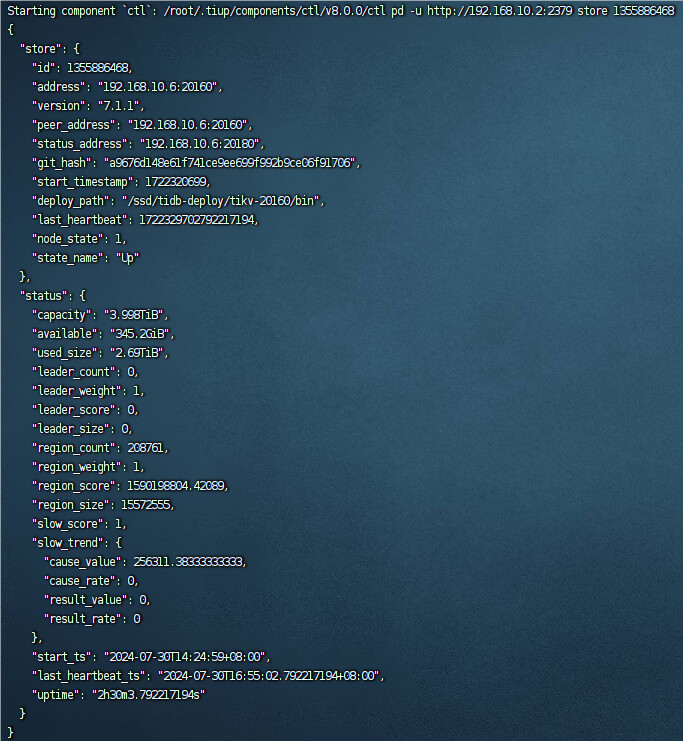
你在看下这表里的STORE_STATE_NAME 列 ,看看是不是都是up 或者pd-ctl store 1355886468
发现个新情况,这个tikv结点的系统时间慢了整整两分钟,会不会是这个原因?
你把时间同步呢

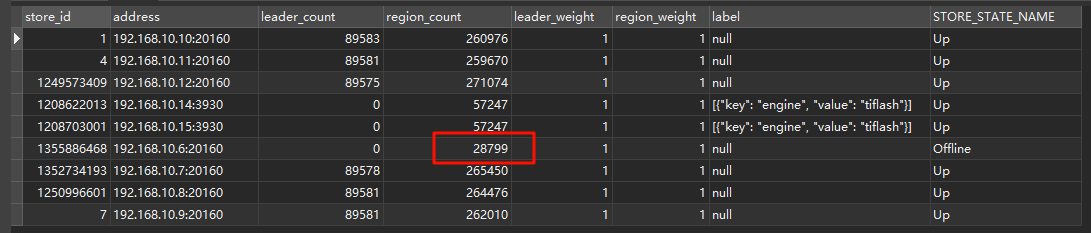
这个tikv目录空间不足,used+available 比capactity少不少
感谢回复。时间同步了也没解决问题,目前进行了缩容。tikv空间不足是因为日志文件占用很大,所以想顺便问下,曾经尝试了将tikv日志的路径修改到其他盘上,但是集群启动报错,在论坛上查了下是已经运行过的集群不能修改。现在是否有可行的方法来进行修改?
没试过改路径,按理说应该可以吧
正常来说,这台机器启动后,你光停了,再起来后这台机器还是会再加到集群里的,建议你用 pd-ctl 看下是不是还在
卡在这多久了 先看Pd leader和这个tikv的日志 看看是哪个region_id 在往其他的store上调度失败
数据过期了 要删完了在增加