个人觉得,如果数据量很大,尤其是分布式系统,tidb要比mysql性能好。反之如果数据量小,不是分布式系统,则mysql要好一些。
1 个赞
官方说法是tidb建议数据量500G以上使用
tidb的性能是远远大于mysql的 不管容量多少其实都建议用tidb 你总会遇到性能瓶颈
一台比一台?
两个数据库的应用场景还是有点区别的,各有优劣。没有最好的,只有更合适的。
1 个赞
吕布和五虎上将加起来谁厉害
各有优劣。大家根据需求选择适合自己的数据库。
![]() 我觉得是吕布
我觉得是吕布
三节点混部,sysbench测试,能始终没跑过mysql单机
这个问题有点笼统了。看使用场景吧。tidb主打的是一个newSQL,性能能够根据需求扩展。
mysql好处是稳定,但是通常开始就要做好性能需求分析,选择好合适的机器,mysq估计装在power上面性能还是很强劲的,但问题是贵呀。
在目前讲求经济性,讲求x86下移的大趋势下,tidb以后应该会比mysql更有想象空间,更符合性能可以弹性拓展的大趋势。
1 个赞
tidb最大的优势是可以水平拓展,这点mysql分库分表是无法做到的。
TiDB 的目的不是替代 MySQL,最早是为了解决 分库分表的复杂性
1 个赞
tidb的和mysql的横向对比并不是单台对单台比。而是一个业务对一个业务比。
比如说我们这个业务用mysql得用1000台mysql 然后部署分库分表。这个时候就适合用tidb业务。
如果业务量请求很小。也不重要数据不需要备份。可以用mysql 具体tidb和mysql对比我写了一篇文章
你可以看一下
mysql 会被tidb替代掉
在日本 tidb已经是数据库排名第一的数据库。并且是连续三年排名第一。

在全世界 tidb的增长速度是全世界第一的。
为什么我们中国人会做出这么一款被全世界认可的数据库?
他们有什么秘诀在身上?
第一 开源 只有开源才能吸引优秀的人参加。
第二开发者是真正的运维数据库的人。
第三开发者不断在追寻最新的数据库趋势
为什么aurora 会被tidb 替代掉呢
因为aurora 是aws开发的。他的目的是为云平台服务的主要目的是大幅度降低云平台运维mysql的成本

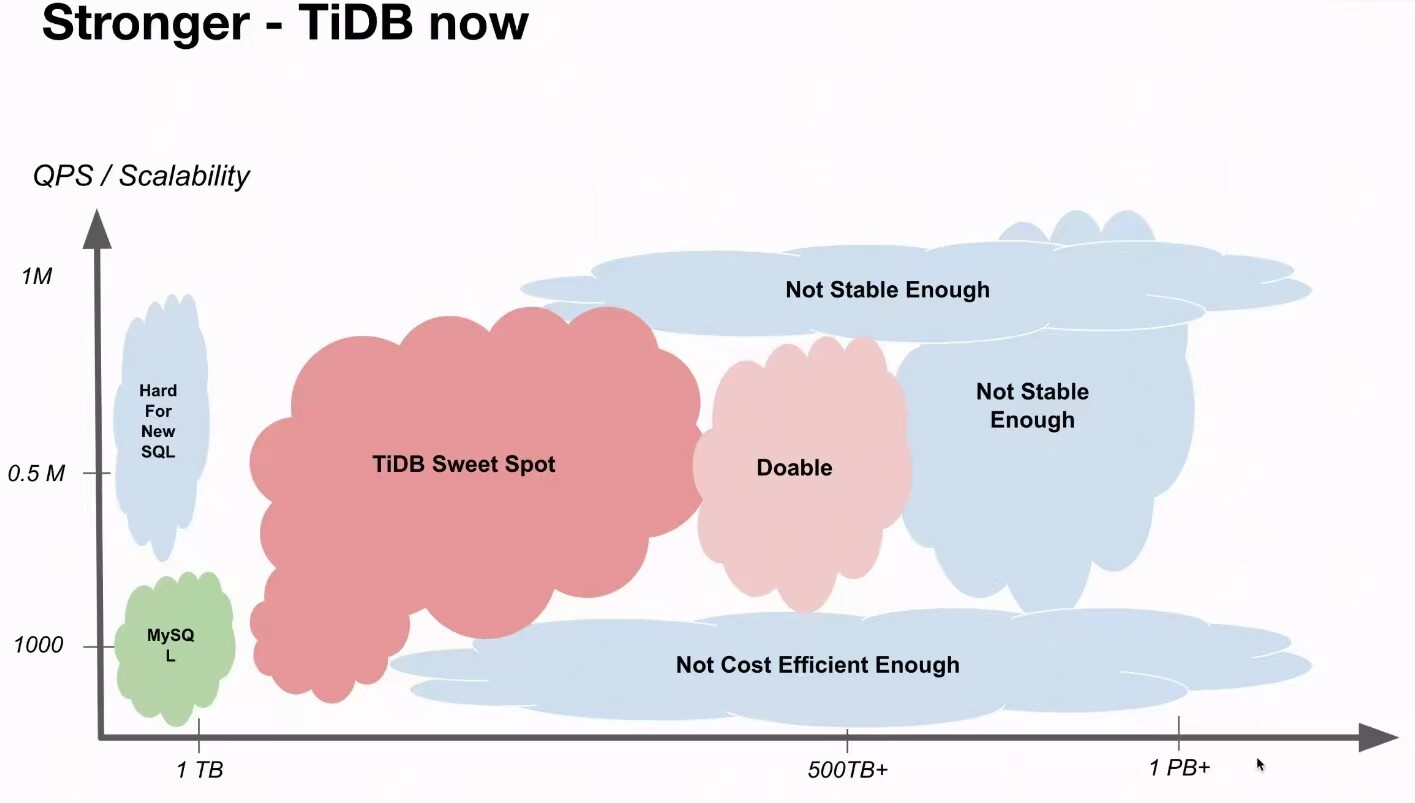
这是aurora数据库的架构图。mysql的速度受到2个因素影响 一个是ebs带宽。 另外是机器的内存。只要是大于内存的内容就会变得非常慢。因为他需要通过ebs带宽来载入存放在s3上的数据库内容 ebs的内容最后是落入到s3的。
这需要不停的做两件事情一件事情是保持数据库的大小必须小于机器内存大小。第二是必须购买大容量的ebs带宽。
我们来看tidb用ebs的情况
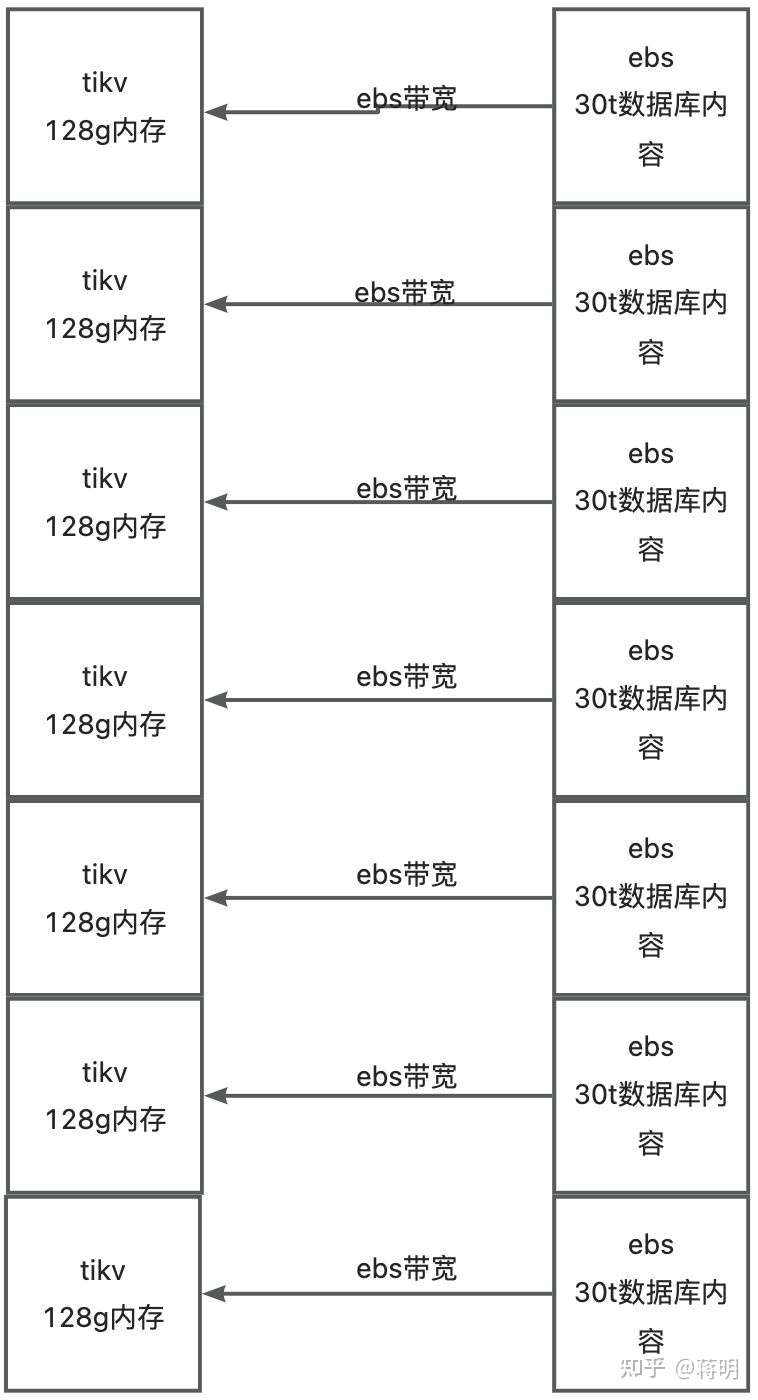
而tidb为什么会比aurora快 就是因为ebs虽然带宽被限制 被卡脖子了。但架不住他机器多 他有6台机器他就能提升六倍多性能。如果性能还是不行。那么再加机器就行。这就是tidb 横向扩展比aurora好的原因之一。
另外一个aurora mysql他是商业付费的。他除了卖的比ec2贵三倍之外。他所有的操作。备份,归档,高可用,主从隔离都是需要付费的。一个aurora的机器价格比tidb贵三倍。而且为了隔离不通数据库带来的性能相互影响。必须要购买多个实例
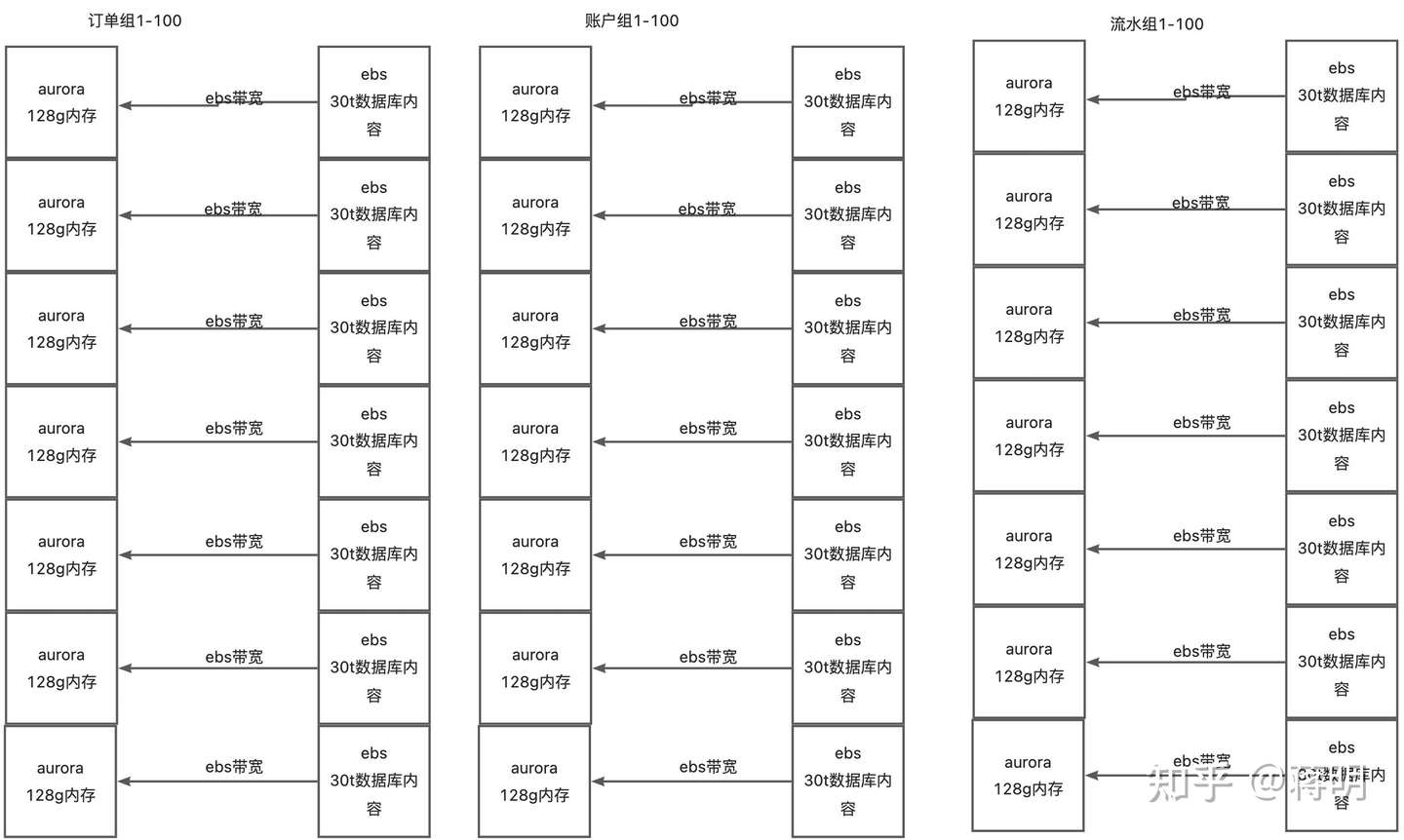
这样的话才能物理隔绝不通业务在对数据库加压的时候会影响到其他业务。这也是mysql分库分表的原因。业务得分库分表。因为aurora 无法对单个mysql用户进行限流。放在单个aurora实例上他的弊端也很多。
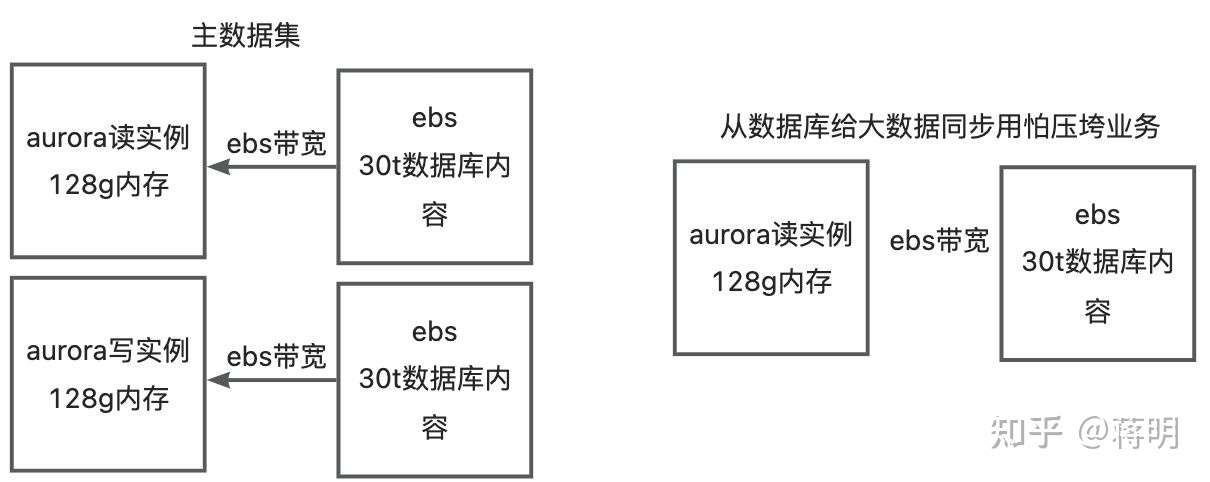
这样以来生产业务和大数据集的业务是可以不相互影响了。但费用翻了9倍。机器数量翻了3倍。单机的价格也比tidb贵三倍。
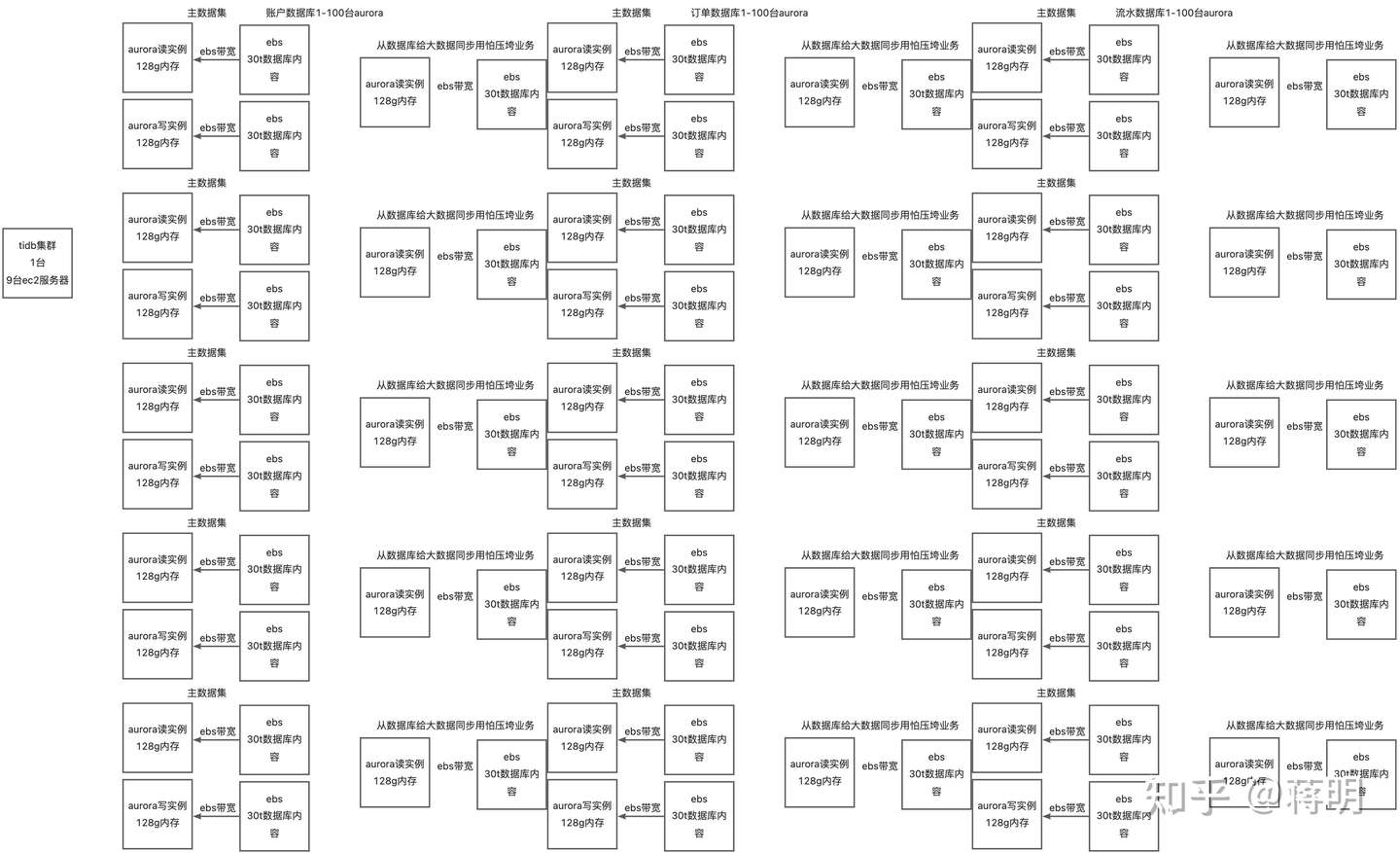
可以从图上看出来 两边数据库数量的巨大差异。
这几年经济都不好。特别是日本进入了衰退的30年。企业兜里都没钱。这就是tidb为什么能在日本市场排第一的原因。
至于为什么tidb一套服务器就能替代aurora 100套服务器。因为tidb还有一套资源管控
创建资源组
下面举例说明如何创建资源组。
- 创建
rg1资源组,限额是每秒 500 RU,并且允许这个资源组的应用超额占用资源。
CREATE RESOURCE GROUP IF NOT EXISTS rg1 RU_PER_SEC = 500 BURSTABLE;
- 创建
rg2资源组,RU 的回填速度是每秒 600 RU。在系统资源充足的时候,不允许这个资源组的应用超额占用资源。
CREATE RESOURCE GROUP IF NOT EXISTS rg2 RU_PER_SEC = 600;
- 创建
rg3资源组,设置绝对优先级为HIGH。绝对优先级目前支持LOW|MEDIUM|HIGH,资源组的默认绝对优先级为MEDIUM。
CREATE RESOURCE GROUP IF NOT EXISTS rg3 RU_PER_SEC = 100 PRIORITY = HIGH;
绑定资源组
TiDB 支持如下三个级别的资源组设置:
- 用户级别。通过 CREATE USER 或 ALTER USER 语句将用户绑定到特定的资源组。绑定后,对应的用户新创建的会话会自动绑定对应的资源组。
- 会话级别。通过 SET RESOURCE GROUP 设置当前会话使用的资源组。
- 语句级别。通过 RESOURCE_GROUP() Optimizer Hint 设置当前语句使用的资源组。
将用户绑定到资源组
下面的示例创建一个用户 usr1 并将其绑定到资源组 rg1。其中 rg1 为创建资源组示例中创建的资源组。
CREATE USER 'usr1'@'%' IDENTIFIED BY '123' RESOURCE GROUP rg1;
下面示例使用 ALTER USER 将用户 usr2 绑定到资源组 rg2。其中 rg2 为创建资源组示例中创建的资源组。
ALTER USER usr2 RESOURCE GROUP rg2;
绑定用户后,用户新建立的会话对资源的占用会受到指定用量 (RU) 的限制。如果系统负载比较高,没有多余的容量,用户 usr2 的资源消耗速度会被严格控制不超过指定用量。由于 usr1绑定的 rg1 配置了 BURSTABLE,所以 usr1 消耗速度允许超过指定用量。
如果资源组对应的请求太多导致资源组的资源不足,客户端的请求处理会发生等待。如果等待时间过长,请求会报错。
用一台超级的大水桶替代了aurora的小水桶。数据正常一般只占用资源的1%-10%。剩下的都是为数据库冗余做准备的避免一个大sql打过来业务崩了。

这就是tidb省钱的原因。两个原因
1.本身ec2的价格便宜三倍。
2.tidb有资源控制本身可以把几百个mysql小数据库聚合起来。通过共享资源的方式把之前每个数据库90%的空闲能力。规避掉达到真正节约费用的目的。
5 个赞
大佬的这个图我搜藏了
学习了,贴子内容收藏了。
这要看具体情况呀
高的不是一点半点啊 。 并行加列存 无敌了
唯我独尊