月明星稀
(Ti D Ber Suk Xnq Xt)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】6.5
【复现路径】日志报错
【遇到的问题:问题现象及影响】
【附件:截图/日志/监控】
读写出现错误:
loadRegion from PD failed, key: “31373232303439313131732F6563612D746573742F6D6F6E69746F725F676C6F62616C2F3131372E36382E34342E36395F737461747573”, err: rpc error: code = DeadlineExceeded desc = context deadline exceeded
tikv错误日志:
2024/07/27 14:10:17.951 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 115, leader may Some(id: 1075 store_id: 1)" not_leader { region_id: 115 leader { id: 1075 store_id: 1 } }))))))”] [tag=raw_put]
[2024/07/27 14:10:17.951 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 115, leader may Some(id: 1075 store_id: 1)" not_leader { region_id: 115 leader { id: 1075 store_id: 1 } }))))))”] [tag=raw_put]
[2024/07/27 14:10:17.951 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 115, leader may Some(id: 1075 store_id: 1)" not_leader { region_id: 115 leader { id: 1075 store_id: 1 } }))))))”] [tag=raw_put]
[2024/07/27 14:10:17.951 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 115, leader may Some(id: 1075 store_id: 1)" not_leader { region_id: 115 leader { id: 1075 store_id: 1 } }))))))”] [tag=raw_put]
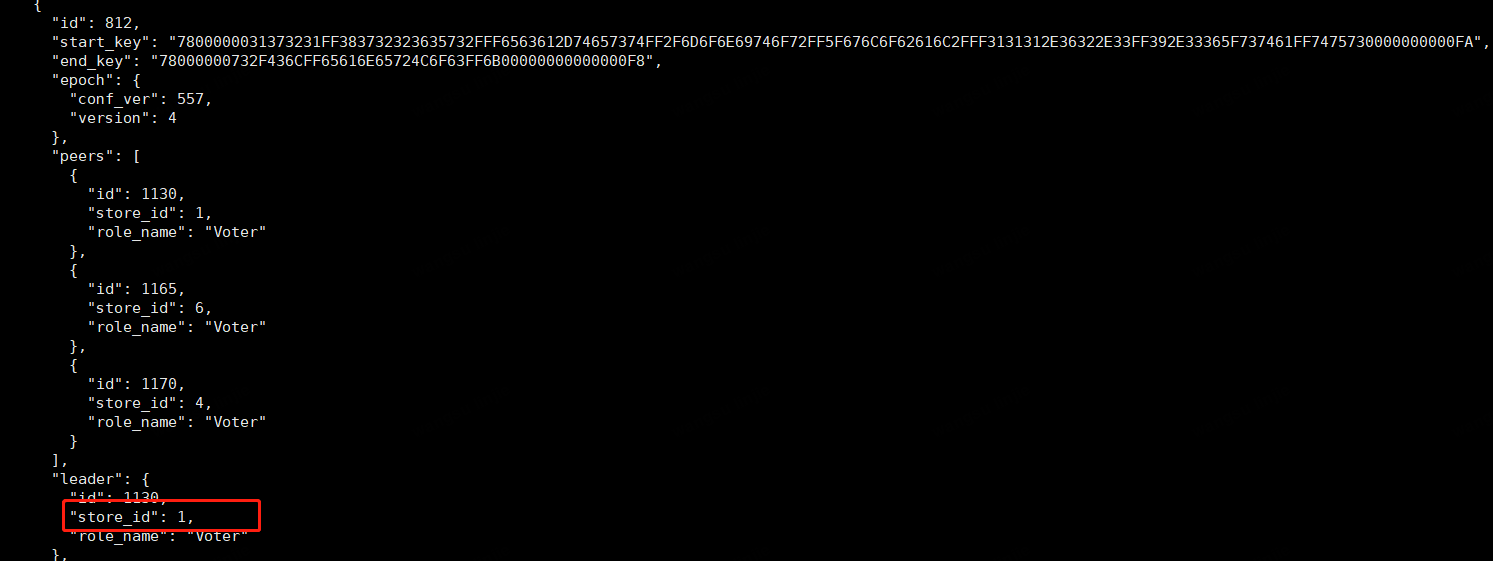
查看pd region信息,发现region 115有leader
以上会是什么问题,大家帮忙看下,谢谢。
xfworld
(魔幻之翼)
2
region_id: 115 leader { id: 1075 store_id: 1 }
日志中的 store_id = 1,Leader Id = 1075 并不是你图中提供的 ,是不是做过什么操作?
月明星稀
(Ti D Ber Suk Xnq Xt)
3
不好意思,缩容的是其他节点,store1没做过什么,store_id:1 还在集群内,并且运行正常。正常不是应该在选举出一个leader吗?
xfworld
(魔幻之翼)
4
如果是这样的话,可能需要等待,等待 PD 收集完所有的 region 信息
可以参考下 grafana 监控的 region 信息,是否有不一致
如果region 信息未一致(合并和分裂),链接上有任何操作,大概率会报错出现 backoff
突破边界
5
是不是节点有扩容或缩容,可能在做rebalance,但是按理也不应该影响这么大,导致SQL操作直接报错
你这不是info报错吗?这个情况正常的,假如你下线一个节点,它上面的leader都会迁移到其他节点,在这个过程中,可能有访问会负载到这个节点上,这时会backoff,等这个leader从这个节点迁移到其他节点完成,backoff也会成功,之后sql不会报错的。除非你迁移有问题,特别慢,超过backoff重试时间,sql才可能会报错。
h5n1
(H5n1)
8
读写时的错误还一直在吗?这个key 再tikv_region_status 里根据start_key/end_key 找下region和表信息, 看下region信息跟你tikv里的一致吗?
月明星稀
(Ti D Ber Suk Xnq Xt)
9
[2024/07/29 20:56:31.117 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))))))”] [tag=raw_put]
[2024/07/29 20:56:31.148 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))))))”] [tag=raw_put]
[2024/07/29 20:56:31.148 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))))))”] [tag=raw_put]
[2024/07/29 20:56:31.215 +08:00] [INFO] [scheduler.rs:742] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))”] [cid=62]
[2024/07/29 20:56:31.289 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))))))”] [tag=raw_put]
[2024/07/29 20:56:31.404 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))))))”] [tag=raw_put]
[2024/07/29 20:56:31.414 +08:00] [INFO] [mod.rs:1899] [“get snapshot failed”] [err=“Error(Txn(Error(Engine(Error(Request(message: "peer is not leader for region 2, leader may Some(id: 7 store_id: 4)" not_leader { region_id: 2 leader { id: 7 store_id: 4 } }))))))”] [tag=raw_put]
清理掉集群数据,不管是clean --data 或者是clean --all,然后启动集群,马上又会出现这个not leader的错误,不知道是什么问题,帮忙解答下,感谢
月明星稀
(Ti D Ber Suk Xnq Xt)
10
[2024/07/29 20:59:01.113 +08:00] [ERROR] [] [“Handshake failed with fatal error SSL_ERROR_SSL: error:1408F10B:SSL routines:ssl3_get_record:wrong version number.”]
这这个不确定有没有关系,这个个错误日志看不到客户端ip,不知道哪里请求过来的?
WalterWj
(王军 - PingCAP)
11
tidb no leader 情况挺正常的,比如 tikv 重启、leader 调度走都会遇到 no leader。
不过 tidb-server 执行 SQL 的时候会统一成 backoff error。然后对应 task 会重试,所以相关 SQL 可能 duration 会略有上升,但是不会报错。
tikv日志显示的是INfO级别,短暂的报错可以忽略,如果长时间报no leader就有问题了。
kevinsna
(Ti D Ber P O Zcnp Ja)
14
如果等操作完成后,报错不再,则应属于正常现象,看这个是INFO级别的信息,估计是操作导致的正常现象