» tso 451469320179941376
system: 2024-07-29 10:06:21.204 +0800 CST
logic: 0
» tso 448705299254607872
system: 2024-03-29 09:14:38.138 +0800 CST
logic: 0
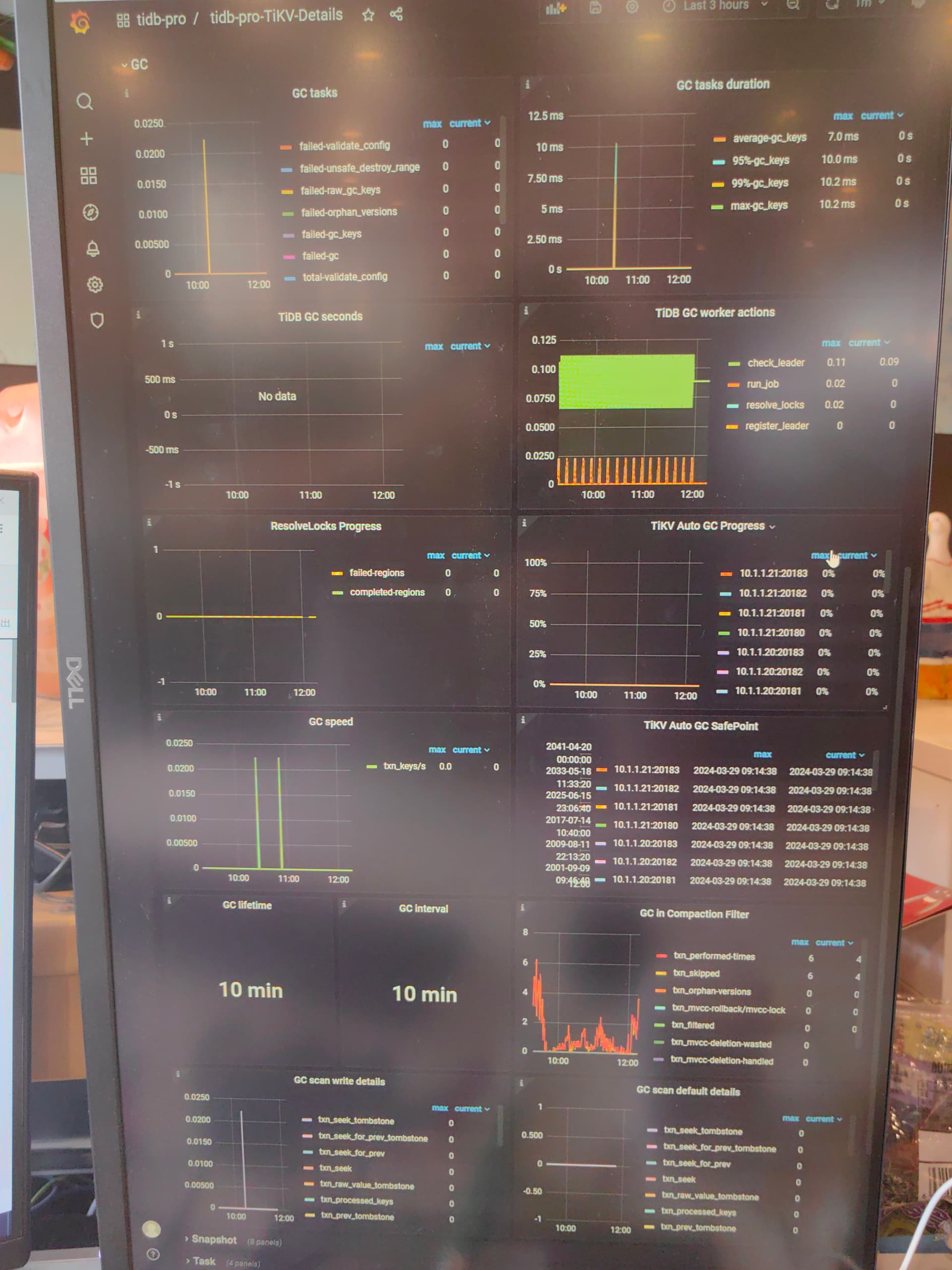
你们 3-29 有做什么操作么?应该在这天上午 9 点多之后 gc 就卡了。
» tso 451469320179941376
system: 2024-07-29 10:06:21.204 +0800 CST
logic: 0
» tso 448705299254607872
system: 2024-03-29 09:14:38.138 +0800 CST
logic: 0
你们 3-29 有做什么操作么?应该在这天上午 9 点多之后 gc 就卡了。
tikv-details → gc 观察下这些监控有活动了没
那时候做了pd的迁移,和集群tikv的迁移
要不要当前找个时间窗口,reload 下整个集群?刷一下配置。
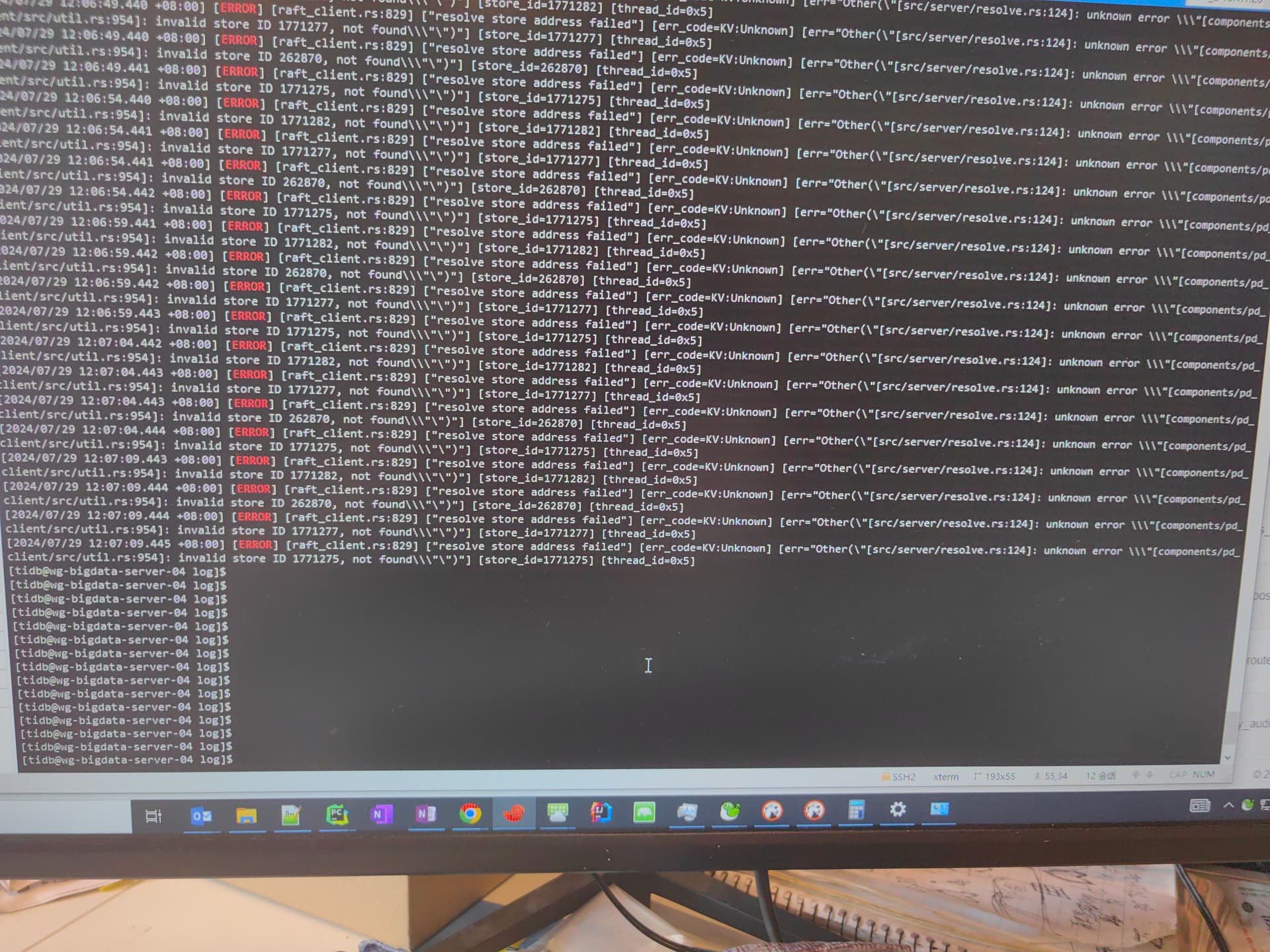
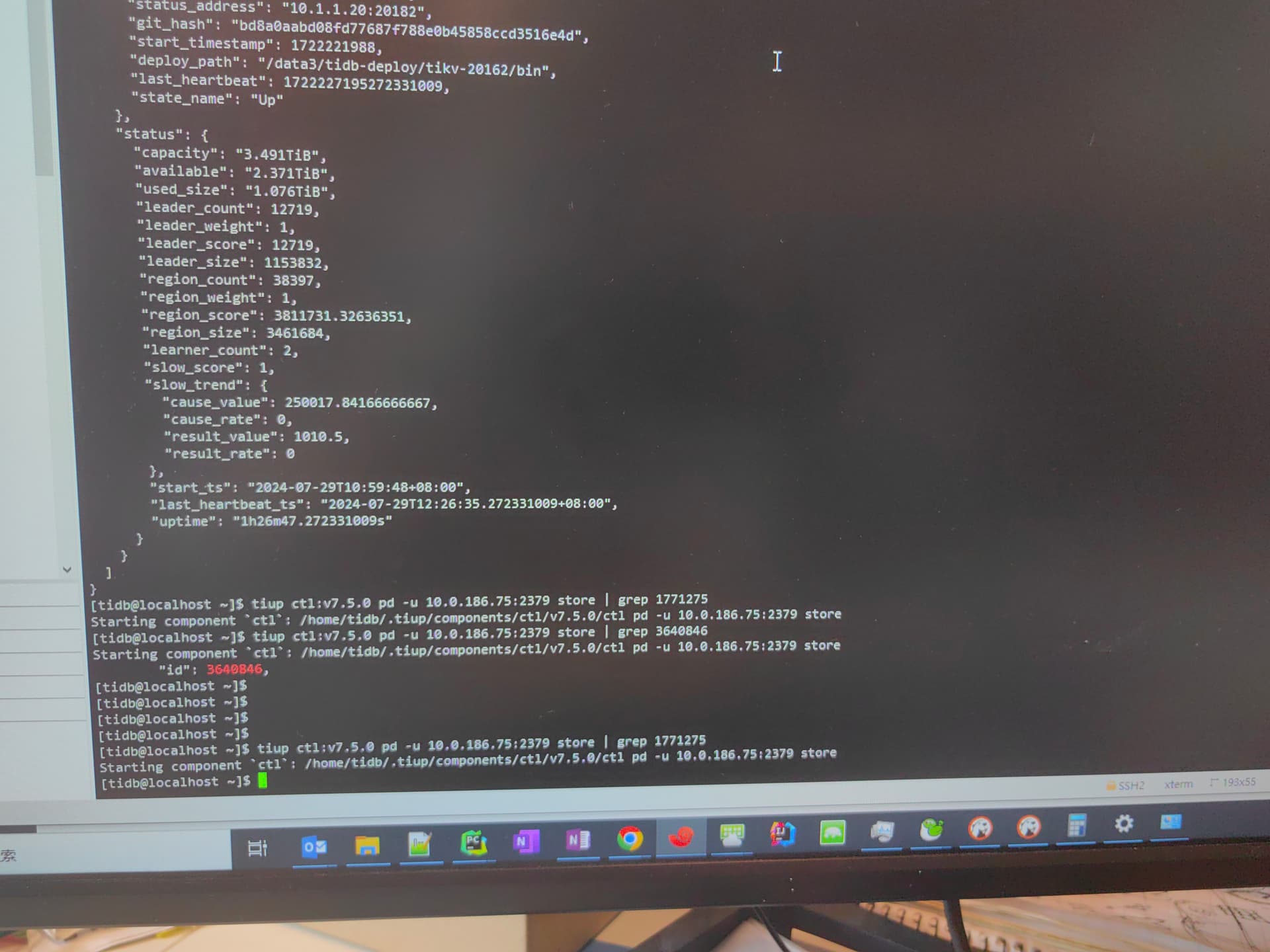
store id 1771275 是什么节点?
用 pd-ctl 看一看 store 信息。
之前迁移集群、扩缩容组件时执行步骤什么样? 有没有碰上问题 怎么查处理的
你去 tikv 节点,看下部署目录下,scripts 目录中 run_tikv.sh 脚本中,pd 信息是否正确。理论上缩容了就不会再访问缩容节点了。
之前迁移有一个机器缩容的时候使用了 --force
这这个pd信息都是正确的
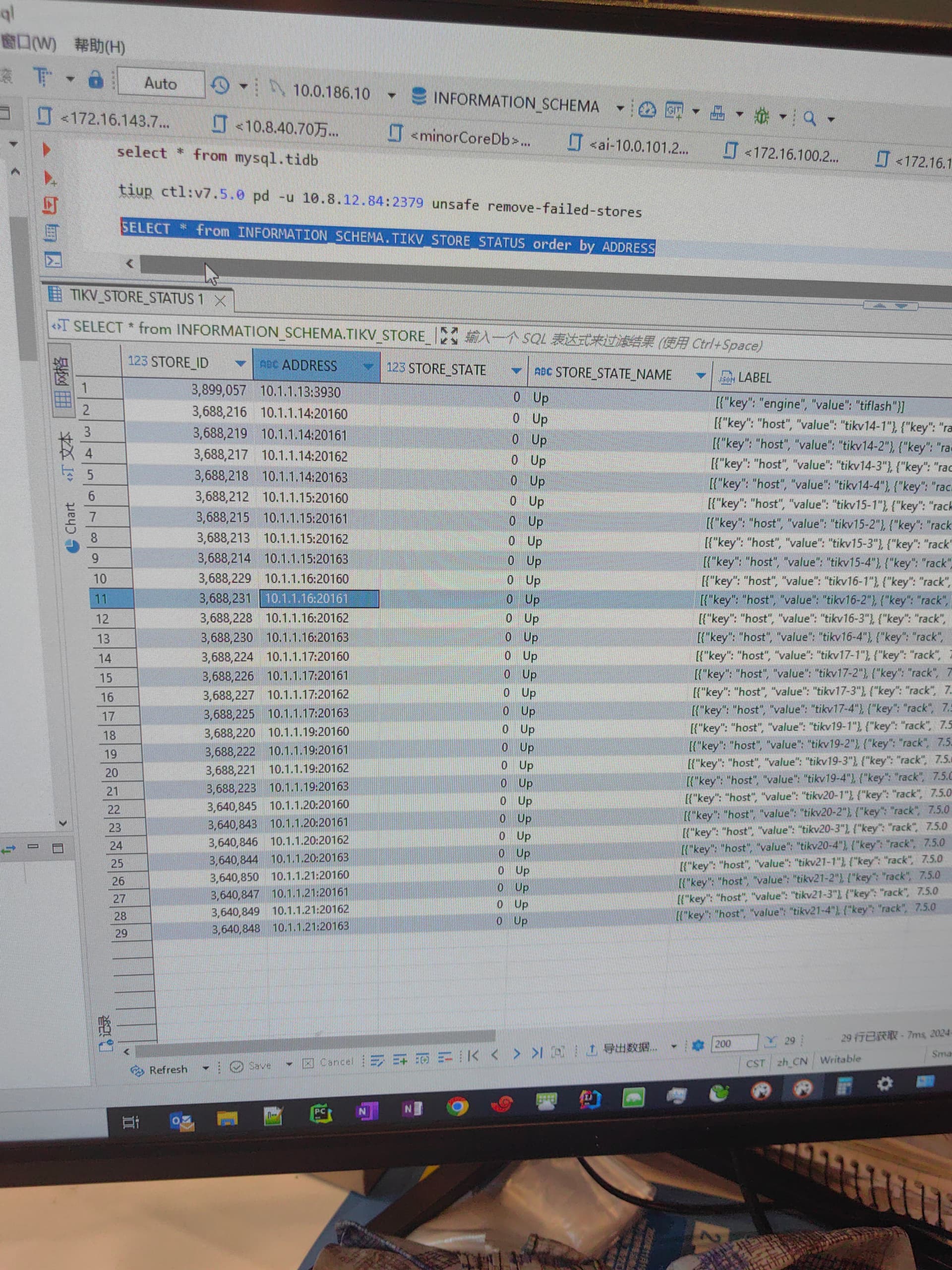
之后还有过处理吗? 是不是就是你前面tikv.log里报的那个store_id ,按理说只是force后pd-ctl store应该能看到还没有移除的store信息,再information_schema.tikv_store_status里 看看能看到你force缩容的那个不
找个时间将数据集群重启下吧
刚把整个集群都reload了,这不是把整个集群文件分发和重启吗?
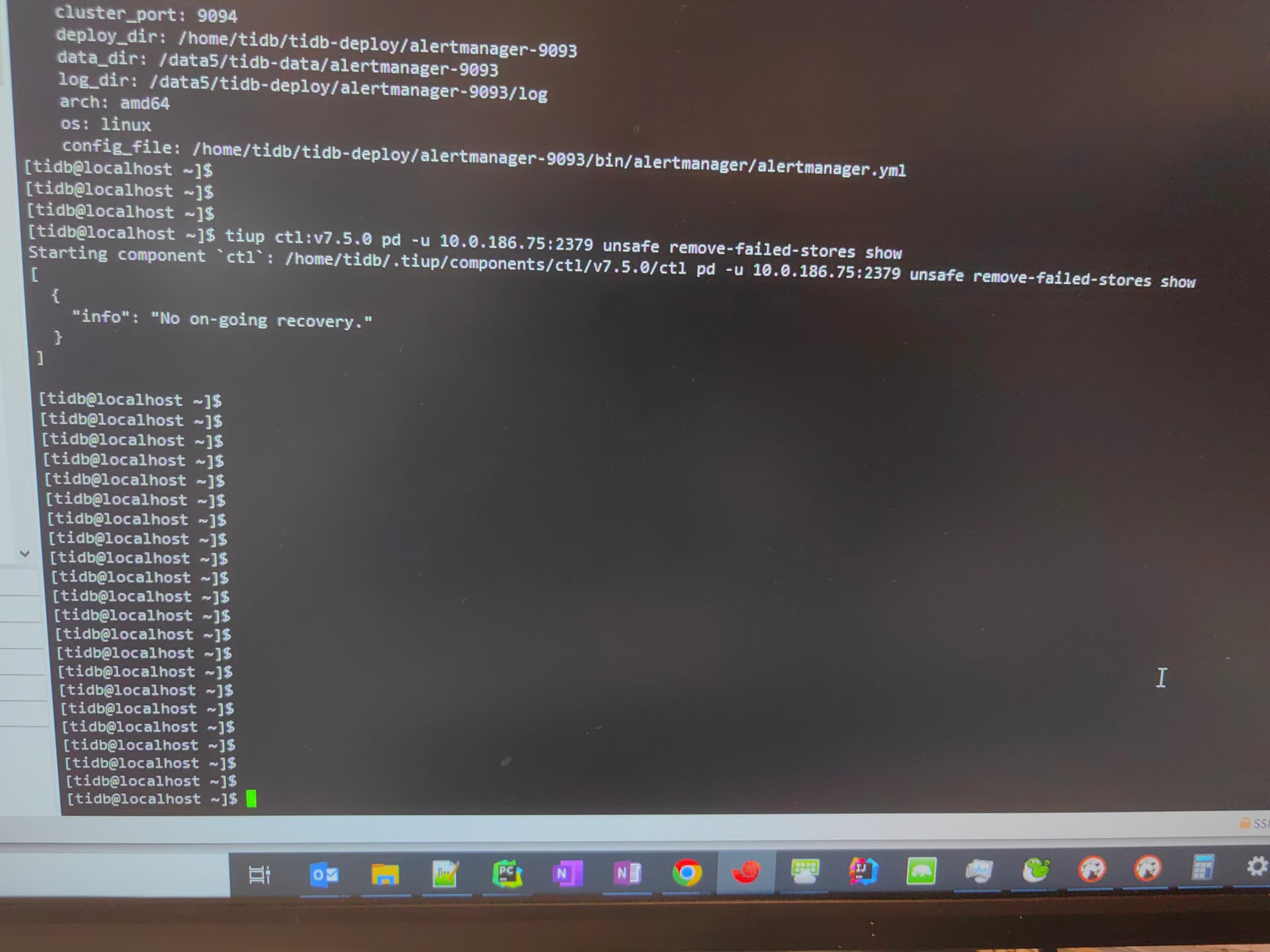
pd-ctl -u <pd_addr> unsafe remove-failed-stores show 这个看看还能看到结果不
这个看错了,是tidb的log 有gc_worker的那个