关注下这问题
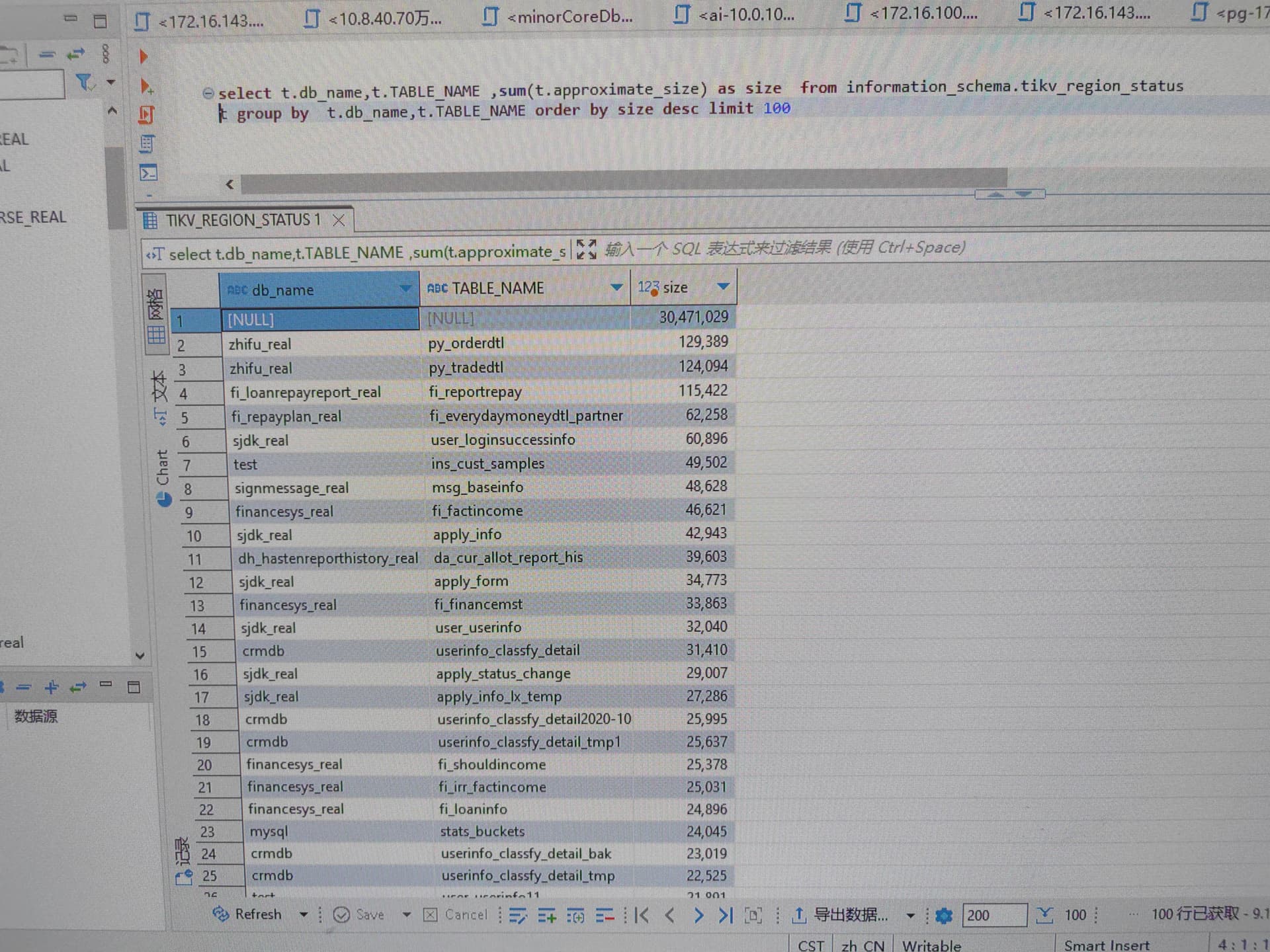
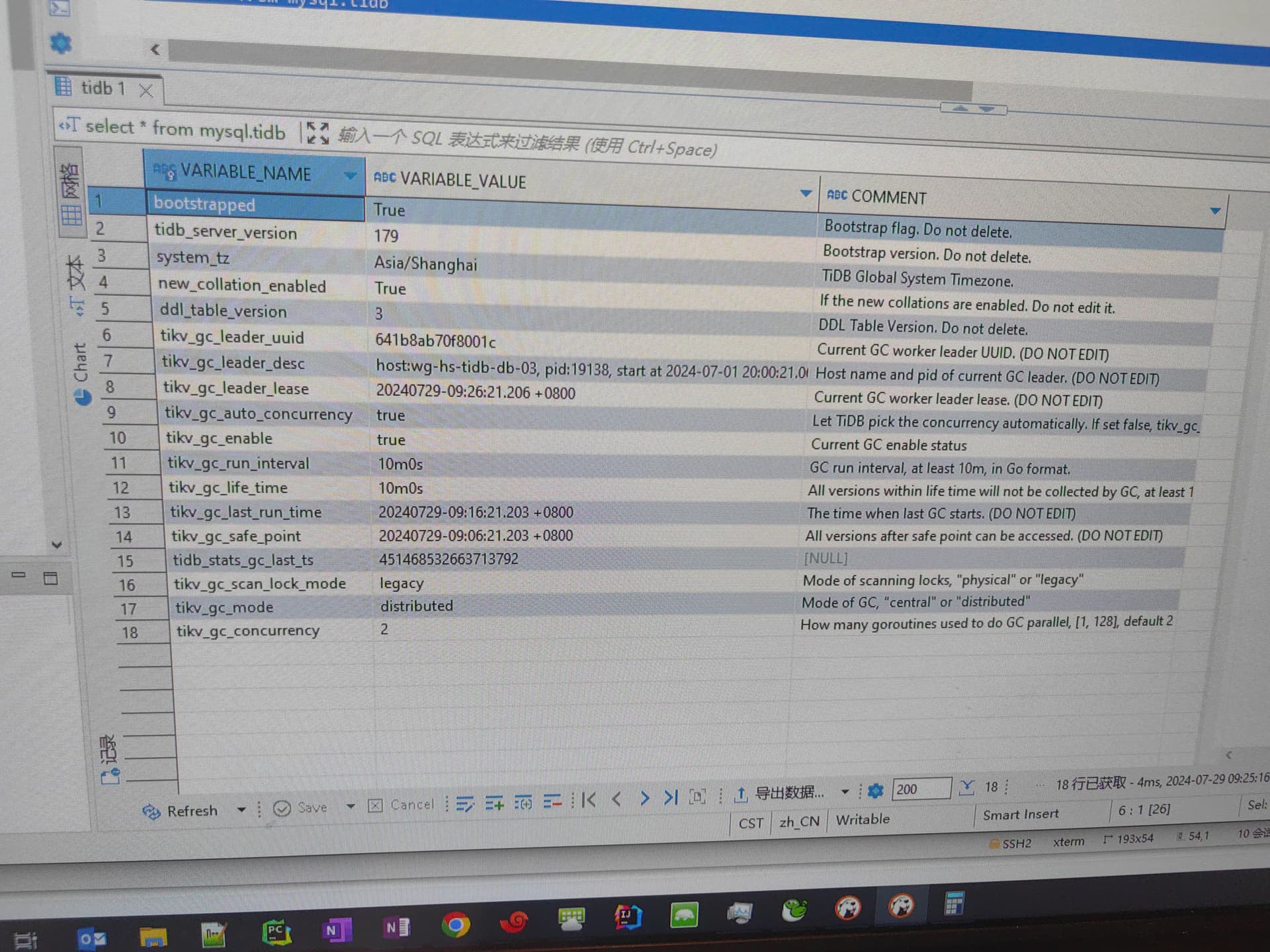
磁盘查了基本都是sst文件占用的
有文档吗,需要怎么调整才能生效,及时GC,清理掉过期的数据,
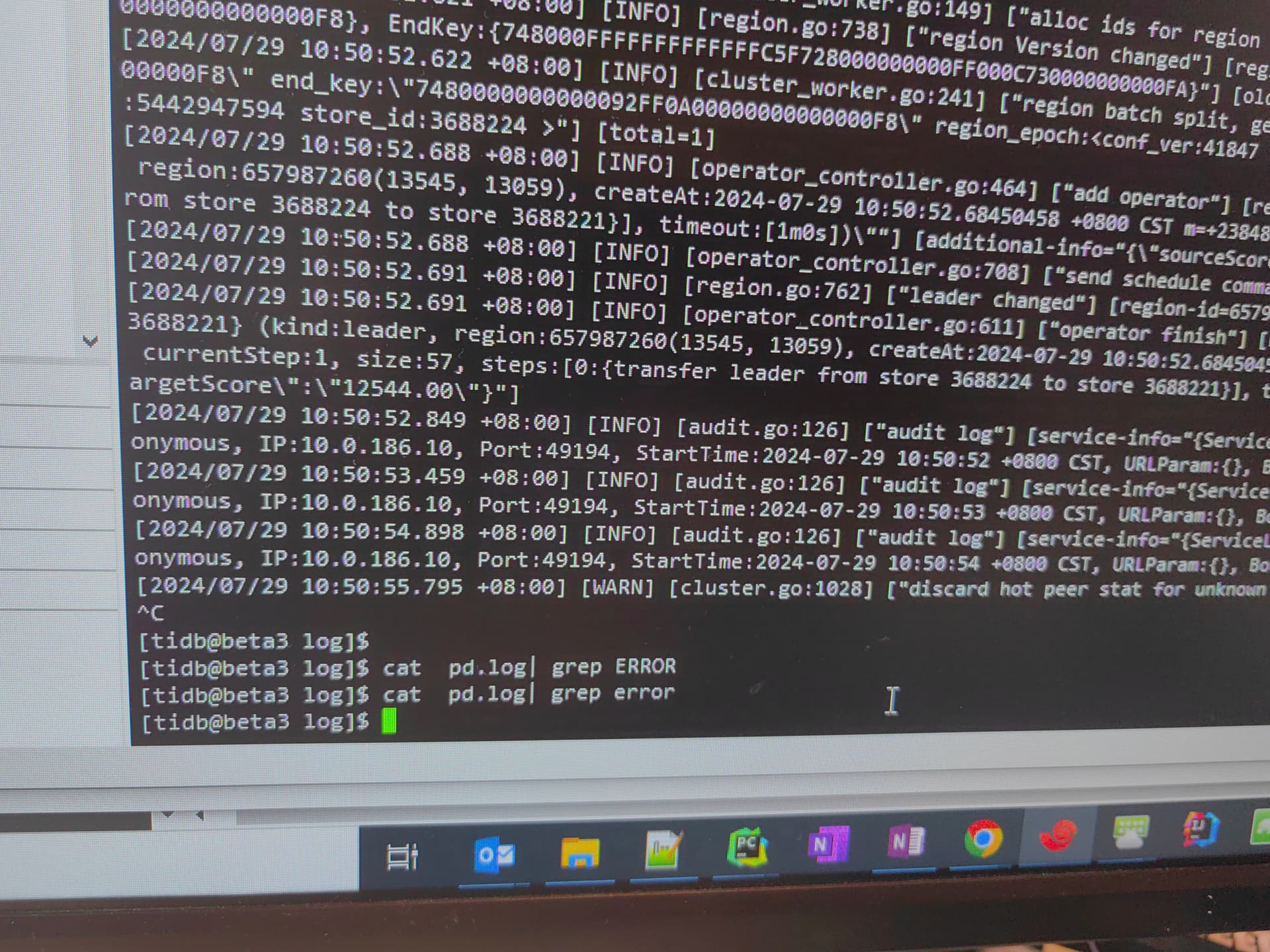
第一个图看起来像是compact出问题了
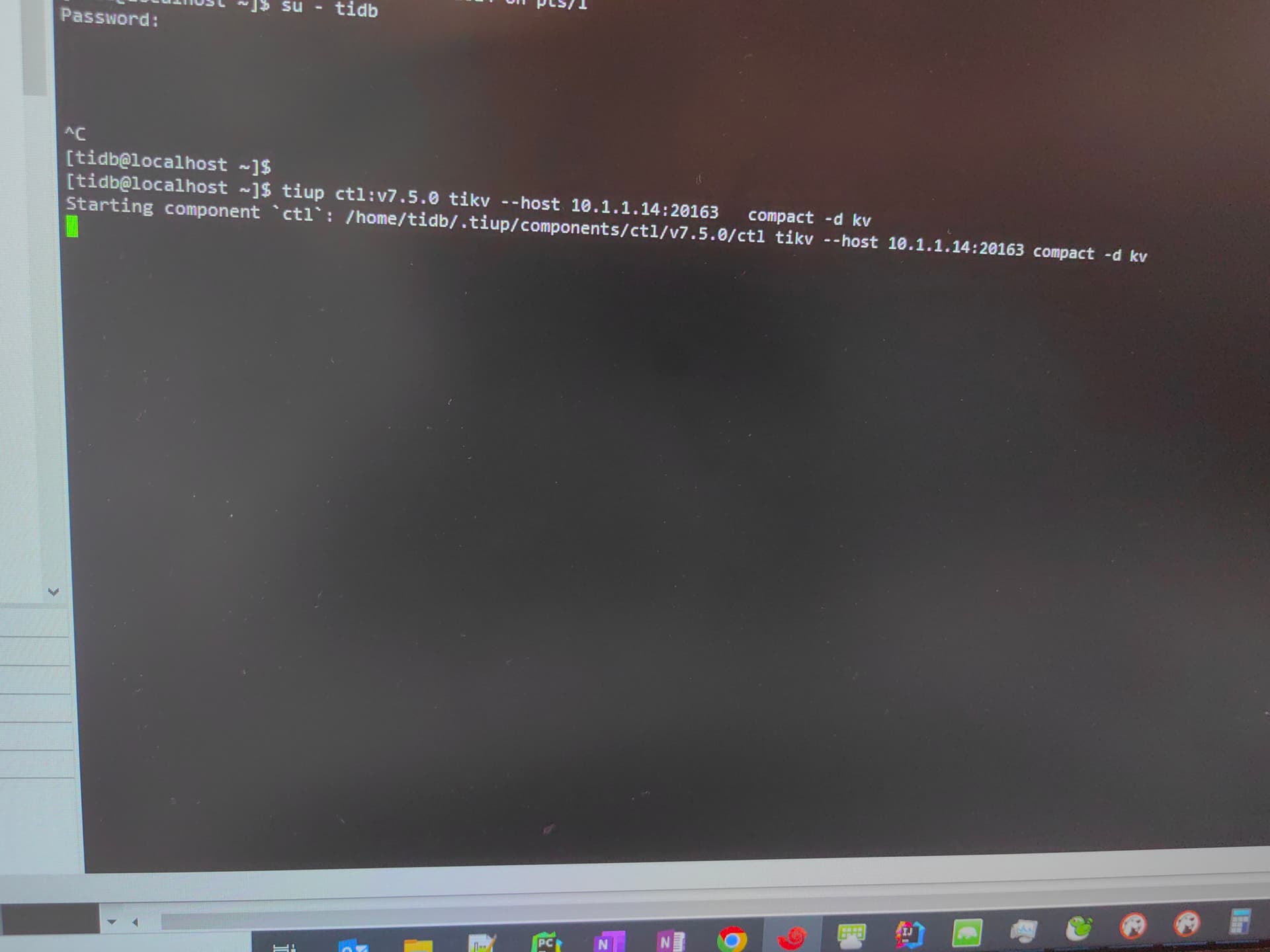
gc失败,数据不过期,compact也没用,得喊个研发给你看看
tiup ctl:v7.6.0 tikv --host 127.0.0.1:20162 compact -d kv --bottommost force -c write
tiup ctl:v7.6.0 tikv --host 127.0.0.1:20162 compact -d kv --bottommost force -c default
参看上面的例子,compact需要跑2次,不同的cf
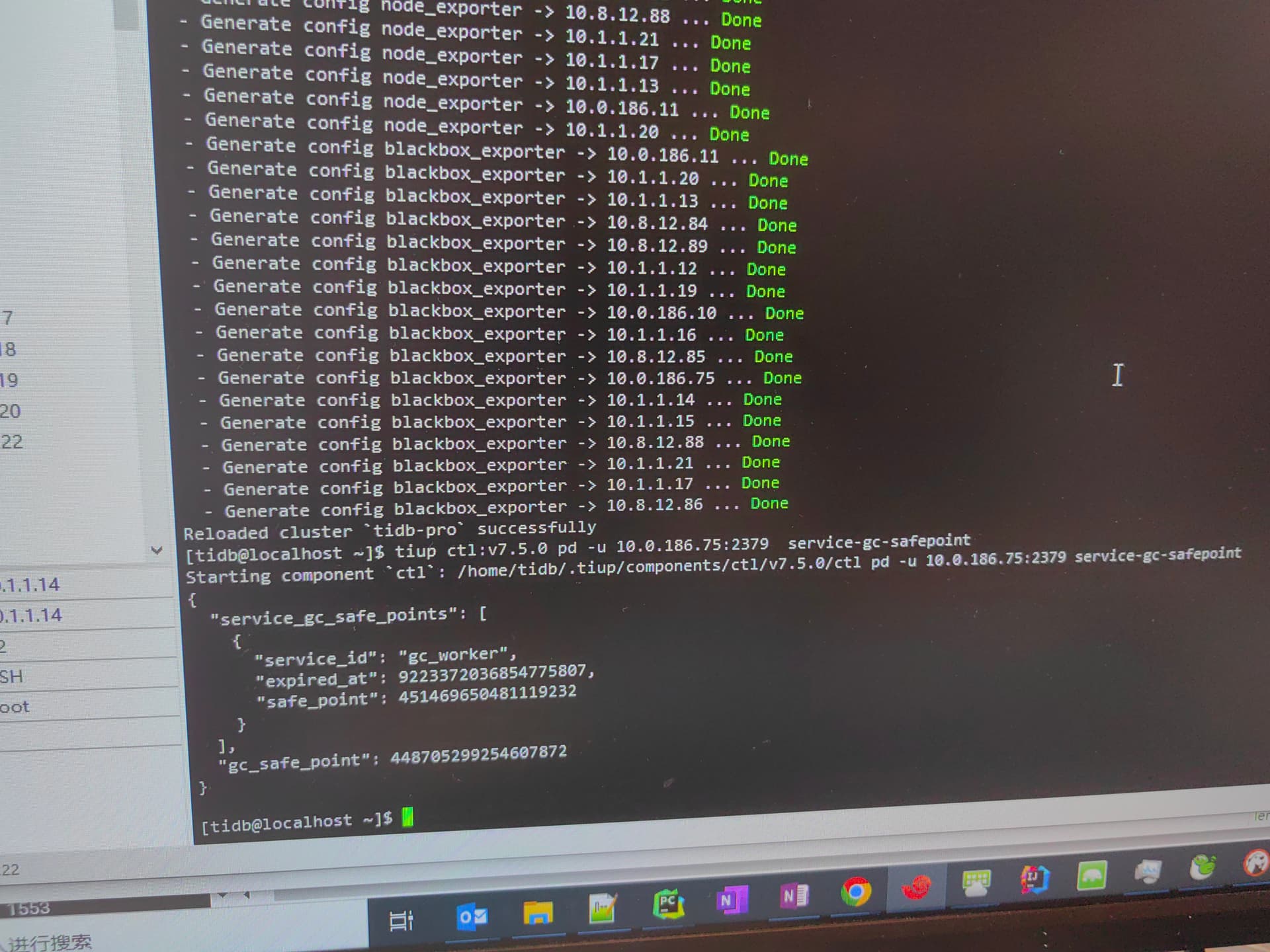
进入 pd-ctl ,查下:
» service-gc-safepoint
{
“service_gc_safe_points”: [
{
“service_id”: “gc_worker”,
“expired_at”: 9223372036854775807,
“safe_point”: 450541884193374208
}
],
“gc_safe_point”: 450541884193374208
}
1 个赞
+1,这里能详细展示出来,到底是哪个服务阻塞了 GC

看起来两个 safe point 是对不上的。
我看上文有写扩缩容过 pd,pd 扩缩容之后,有 reload 整个集群,刷配置么?
tikv没有刷新配置,reload需要时间太长了,有没有只刷新配置不重启角色的命令

看下gc leader的日志里还有报错吗
你当时是所有 PD 都被替换了,还是只替换了部分的 PD?
没刷新配置,那你扩缩容之后 tidb-server 有没有发生过重启?看下各个组件的 uptime。比如 oom 或者什么操作重启过就会有问题。
所有pd都迁移了机器,都是使用tiup命令中的scale-out和scale-in做的