chachae
(chachae)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
【复现路径】pd leader 所在云主机宕机
【遇到的问题:问题现象及影响】pd leader 挂掉之后几十秒后选主成功但客户端过了15min 左右才恢复正常读写
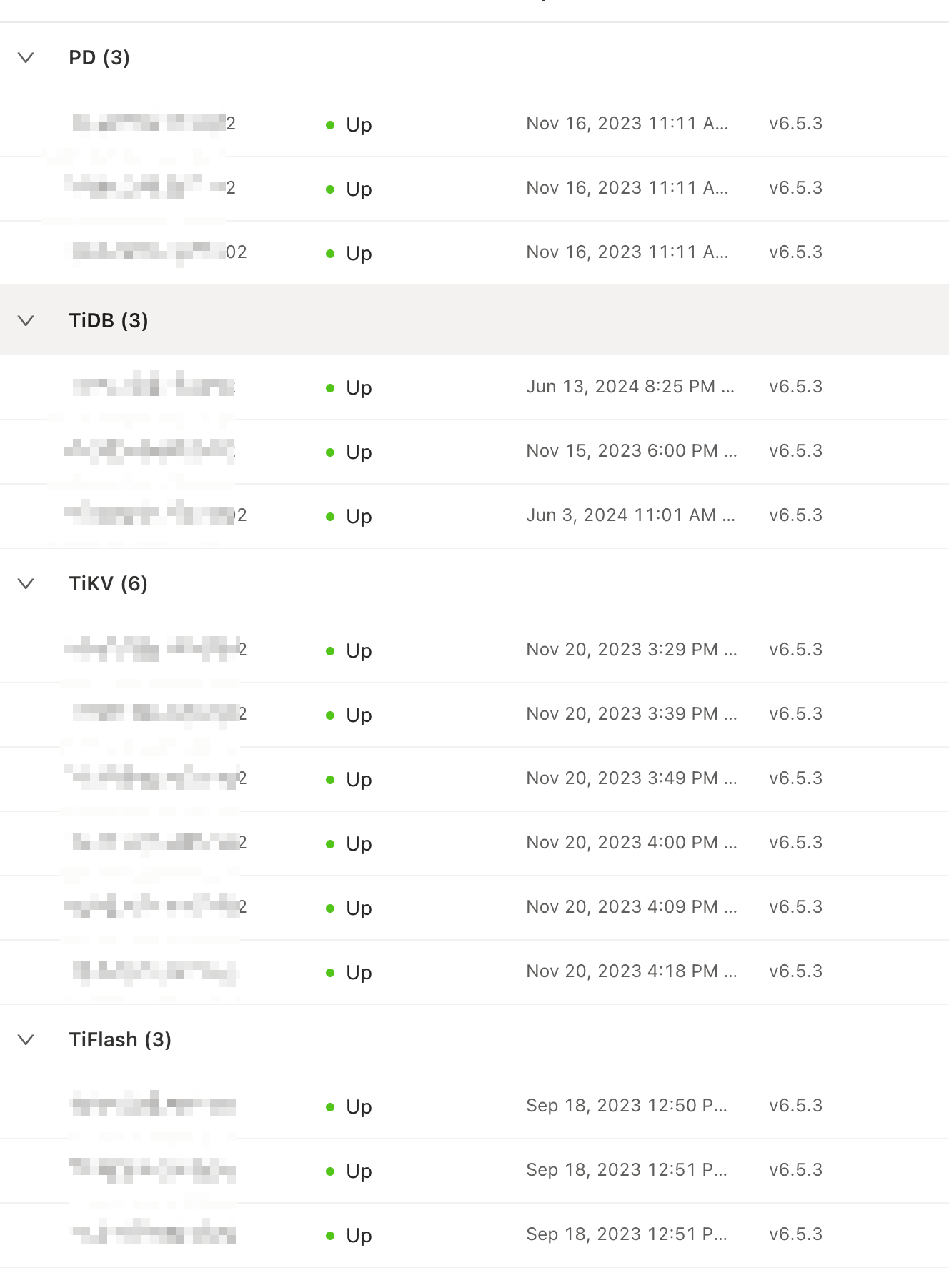
【资源配置】
【附件:截图/日志/监控】20:25 pd挂了,20:40左右恢复读写,下面是选举后其中一个tiserver 的日志,其他几个也tiserver 日志在此期间也差不多一样内容
NEW_PD_LOG_0613.log (3.1 MB)
补充一下:
我们装了tiflash,tiflash 独立部署的,这期间上面的tiserver 日志期间有大量Dispatch mpp task 的日志,结束之后客户端随之正常
有没有可能是客户端可能缓存了旧的 PD leader 地址,并在一段时间内继续向旧地址发送请求,导致请求失败。
chachae
(chachae)
3
pd 切主成功后看我们grafana 对应I/O 监控一直很低,分析日之后其实有怀疑客户端压根没重新连上tidb,我们这边用的aws elb 负载均衡,客户端是flink jdbc connector 内部其实就是jdbc client,jdbc 不直接跟pd 交互吧,还有客户端阻塞了15min 报错了个错后马上恢复,I/O监控也恢复正常,下面是客户端阻塞15min 后的异常以及jdbc url 的path配置,有没有可能是aws elb 的问题或者说是jdbc url path携带的配置导致的呢
1 个赞
chachae
(chachae)
4
大佬,确认了个事情,15min 阻塞期间,新的链接能正常读写,但flink jdbc 那边阻塞的那批有问题,估计大概率是客户端或者elb 的问题了。。
chachae
(chachae)
6
有考虑过,但现在比较尴尬的是得确认是不是真就是elb 的问题,生产不好复现,测试环境我们尝试复现没复现出来 
flink 也是jdbc吧 新建的能写不新建就不能写? 感觉像flink这边数据异常没有自己重试。看看这个思路